05|数组:一秒钟,定义1000个变量
文章目录
你好,我是胡光,咱们又见面了。通过前几节的学习,你已经了解了基本的程序结构。我们来简单总结一下,其中第一种结构就是顺序结构,它指的是我们所写的按照顺序执行的代码,执行完上一行,再执行下一行这种的。第二种就是分支结构,主要是用 if 条件分支语句来实现,主要特征是根据表达式的真假,选择性地执行后续代码。最后一种就是循环结构,用来重复执行某段代码的结构。
如果把程序比喻成工厂的话,现在你的工厂中已经有了各种各样的流水线,但这个工厂只是能生产产品还不行,还需要有存储的空间。今天,我们来学习的就是如何创建和使用工厂中的库房,本节之后,你的程序工厂就可以开工了!
今日任务
先来看看今天这 10 分钟的小任务吧。今天的任务是这样的,程序中读入一个整数 n,假设 n 不会大于 1000,请输出 1 到 n 的每一个数字二进制表示中的 1 的个数。
我举个例子哈,当 n 等于 7 的时候,我们把 1 到 7 的每个数字的二进制表示罗列出来,会得到下表所示内容:
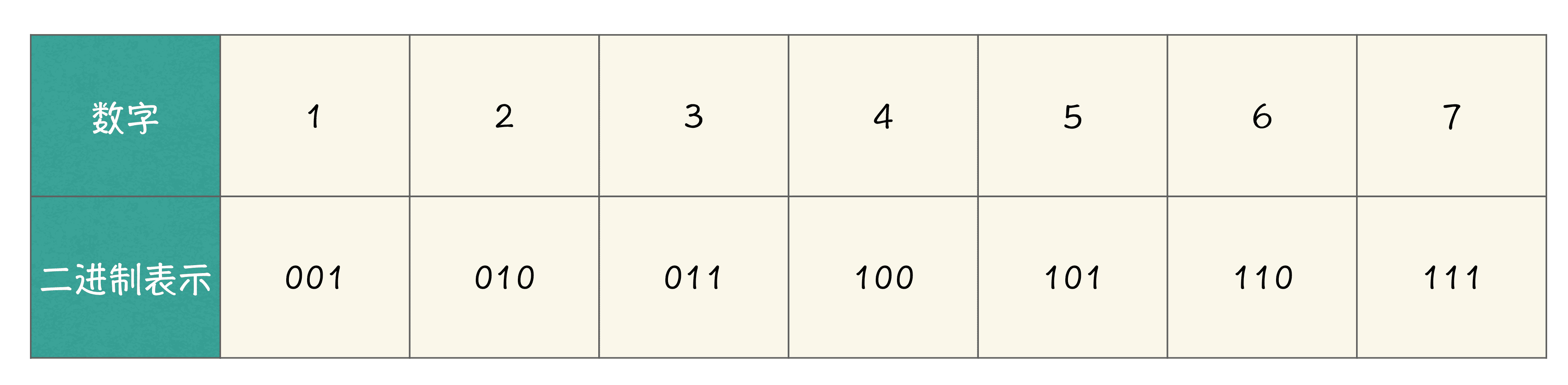
表 1:1 到 7 的二进制表示
根据表 1 中的内容,如果你的程序编写成功的话,程序应该分别输出 1、1、2、1、2、2、3,这些输出内容分别代表每个数字二进制表示中 1 的数量。
对于这个任务,你想写出来一个可行的程序不难,例如:我们可以循环 n 次,每次计算一个数字二进制中 1 的数量。怎么计算一个数字二进制中 1 的数量呢?这个问题,你可能想采用如下程序来进行实现:
int cnt = 0;
while (n != 0) {
if (n % 2 == 1) cnt += 1;
n /= 2;
}
我解释下上面这段程序,它每次都会判断 n 的二进制末尾是不是 1,如果是 1,计数量 cnt 就加 1(+= 表达式,我这里就不解释了,如果你不理解,可以自己查下),然后将 n 除以 2,相当于去掉 n 的二进制表示的最后一位,这样就可以用 O(logn) 的时间复杂度(关于这个知识点,你也可以自行查阅相关资料,其实很简单)计算一个数字 n 二进制中 1 的数量。
以二进制数字 110 为例,末尾是 0,计数量 cnt 不进入计算;然后使用二进制除法,让 110 除以 2,即去掉最后一位的 0,变成了 11,此时末尾是 1,计数量 cnt 就加 1;11 再除以 2,变成了 1,此时末尾是 1,计数量 cnt 再次加 1。最后的 n 等于 1,再除以 2,n 变成了 0,循环结束。
可以看到,当我们输入数字 6,二进制的表示是 110 时,整个程序中计数量 cnt 共计算了 2 次,所以最后的输出结果是 2。
关于时间复杂度这个概念,后续我们还会进一步介绍,现在你可以简单地理解成为是程序运行的次数,例如 n=8 的时候,上面循环执行 3 次,也就是 log 以 2 为底 8 的对数的值。
如果你的方法像上面这么做的话,确实是一种可行的方法,可是效率不是很高。今天这个任务的要求是,对每一个数字,请用 O(1) 的时间复杂度计算得到其二进制表示中 1 的个数。O(1) 也就是 1 次,或者是与问题规模 n 无关的有限次,例如:2 次、3 次均可。下面就让我们来看看如何完成这个任务吧。
必知必会,查缺补漏
1. 数组:规模化存储工具
我要给你介绍的第一个帮助我们完成今天任务的工具是:数组。所谓数组,你可以把这两个字对调过来理解,即组数,一组数据。
以往我们定义的变量,都是单一变量,例如:一个整型变量,一个浮点型变量,等等。可当我们要同时记录 n 个整型数据的时候,通过以往的知识,你能实现这个需求么?注意,这个里面的 n 是通过读入的一个变量,通常情况会有一个最大范围,例如:n 不会超过 1000。你总不能定义 1000 个整型变量吧?
面对上面这种需求,数组就派上了用场,利用数组,我们可以定义存放一组数据的存储区,用法如下代码所示:
int arr[1000];
通过上述代码,我们很轻松的就定义了存储 1000 个整型变量的存储区 arr。这里相当于向计算机申请了可以存储 1000 个整型变量的存储空间。第一个存储整型数据的内存空间,也就是第一个整型变量,就是 arr[0],第二个整型变量是 arr[1],以此类推。arr 后面方括号里面的东西,我们称之为“数组下标”,数组下标从 0 开始,也就是说,代表 1000 个整型变量的数组,下标范围应该是 0 到 999,具体可以参考图 1。
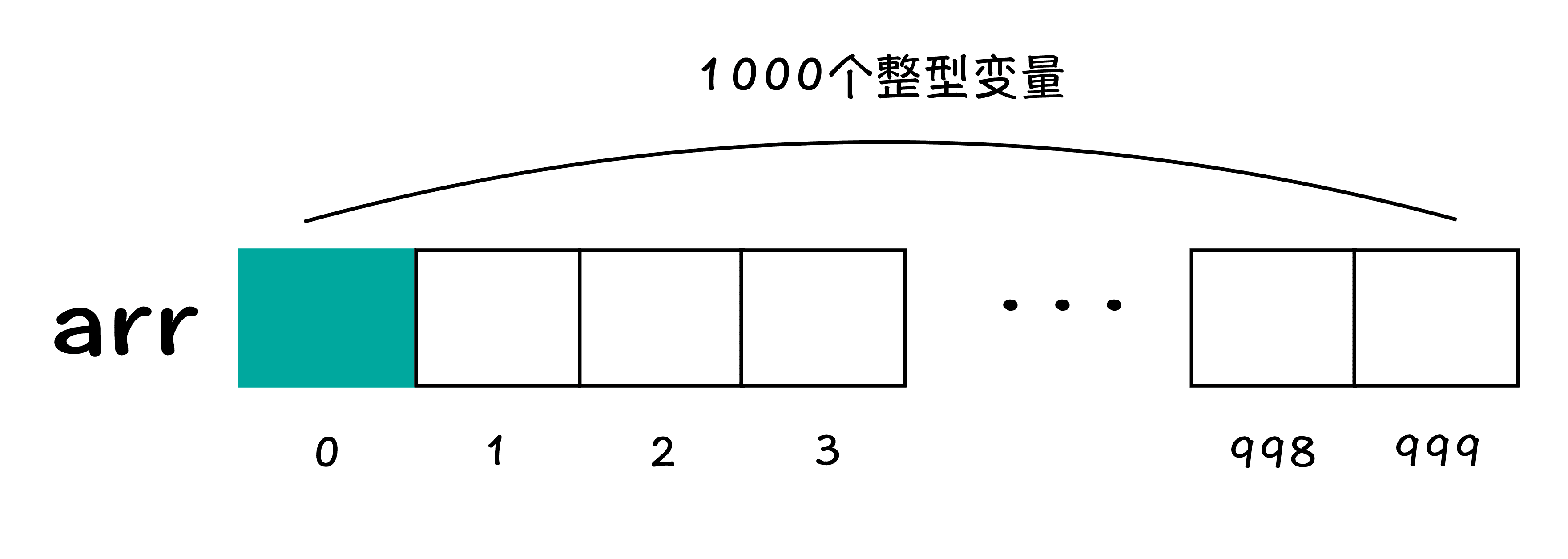
图 1:数组示意图
有了数组以后,你就可以轻松的完成读入 n 个整型数据的任务了,参考代码如下:
int n, arr[1000];
scanf("%d", &n);
for (int i = 0; i < n; i++) scanf("%d", &arr[i]);
代码中,第一行定义了一个整型变量 n 和一个最多存储 1000 个整型元素的数组空间。第二行接下来读入 n 的值,第三行利用循环结构循环 n 次,循环变量 i 取值从 0 到 n-1,循环每次读入一个整型数据存放在 arr[i] 里面。
这样一段程序执行完后,n 个整型数据就被依次的存放在了 arr[0] 到 arr[n-1] 中。当你想在程序中使用第三个整型数据的时候,只需要访问 arr[2] 即可。当然,上述循环变量的取值范围也可以调整到 1 到 n,这样做的话,相当于我们将 n 个整型数据存放在了 arr[1] 到 arr[n] 处。
2. 字节与地址:数据的住所和门牌号
在之前第 2 篇的学习中,不知道你还记不记得一个叫做 char 的数据类型,我们称其为字符型。当时在学习的时候,我们说,字符型数据形如:“a”,“b”,“c”,“+”,“-”等等这些被引号包裹着的内容。这次我将带你从 char 类型开始,深入理解两个概念:字节与地址。
什么是字节呢?它是计算机中最基本的存储单位,就像一个一个不可分割的小格子一样,存在于我们计算机的内存中。例如,我们通常所说的,一个 32 位整型元素占用 4 个字节,那就意味着这个元素需要占用 4 个小格子,不会存在某个元素占用 0.5 个小格子的情况。这就是所谓的不可分割。

图 2:字节示意图
任何类型的元素,整型也好,浮点型也罢,只要是想存储在计算机中,就一定要放在这些小格子里面,唯一的区别,就是每一种类型的元素占用的格子数量不一样。例如:32 位整型占 4 个格子,double 双精度浮点型占 8 个格子。在这里,需要注意的是,每一种基础类型,在内存中存储时,一定是占用若干个连续的存储单元。
那么如何查看某个类型的元素究竟占用多大的存储空间呢?可以使用 sizeof 这个运算符,如下:
int a;
sizeof(a); // 计算 a 变量占用字节数量
sizeof(int); // 计算一个整型元素占用字节数量
正如你所看到的,sizeof 的使用,就像函数方法一样,我们想要查看什么元素或者类型所占用字节数量,就把什么传入 sizeof 即可,你可以使用 printf 语句输出 sizeof 表达式的值以查看结果。
了解了什么是字节以后,下面我们就要说一个更小的单位了,叫做比特,英文是 bit。这个是计算机中表示数据的最小单位。对比字节是存储数据的最基本单位,比特是表示信息的最基本单位。
那什么又是比特呢?在其他参考资料上你可能知道,计算机里面的所有数据,均是用二进制来表示以及存储的,这里需要注意,是所有的。那么一个比特,就是一个二进制位,要么是 0,要么是 1。8 比特位是 1 个字节,那么我们之前所说的 32 位整型,也就是占 32 个比特位的整数类型,换算一下,正好是占 4 个字节。
说完了字节的概念后,我们再来说说地址。
现在我们的一些小区里面都有一个集中式的邮箱,邮递员来投递信件的时候,只需要把信件放到相应的邮箱里面即可。而作为住户,会有一把能打开自己家邮箱的钥匙,找到自己的邮箱,取出信件即可。
如果把这个场景放在计算机中,住户其实就是 CPU,而邮箱就是内存。你会发现,住户之所以可以准确找到自己的邮箱,是因为每个邮箱上面有一个独立编号。那么 CPU 能够准确找到程序所需要数据的本质原因,也是因为每一个字节都有一个独立的编号,我们管这个编号,叫做:内存地址!下面我给你放了一张示意图:

图 3:内存地址示意图
上图中,下面空白的格子就是我们所谓的字节,具体的数据信息,就是存储在这些格子里面的,格子上面的是十六进制数字,就是我们所谓的地址,你会看到,在内存中,字节的地址是连续的。
最后我们来总结一下,比特是数据表示的最小单位,就是我们通常所说的一个二进制位。字节是数据存储的最基本单位,存储在计算机中的数据,一定是占用若干个字节的存储空间。最后就是内存地址,是每一个字节的唯一标记。
3. 直观感受:内存地址
你可能会觉得内存地址是一个很抽象的概念,不具体。其实我们可以像输出整型值一样,把内存地址也输出出来。
你还记得格式占位符的作用吧?不同数据类型,用不同的格式占位符输出,例如:%d 对应了十进制整型的输出。内存地址则采用 %p 这个格式占位符进行输出,下面给你一个演示程序,你可以在你的环境中运行一下:
#include <stdio.h>
int main() {
int a;
printf("%p\n", &a); // 输出 a 变量的地址
return 0;
}
代码中,首先定义一个了整型变量 a,然后使用 %p 占位符输出 a 变量的地址。单一的 & 运算符放到变量前面,取到的就是这个变量的首地址。
为什么说是首地址呢?上一部分说了,一个 32 位整型变量会占用 4 个字节的存储空间,每一个字节都会有一个地址,那么你会发现,上面程序中的 a 变量实际上有 4 个地址,这 4 个地址究竟哪一个作为 a 变量的地址呢?答案是最靠前的那个地址,作为 a 变量的地址,也就是这个变量的首地址。
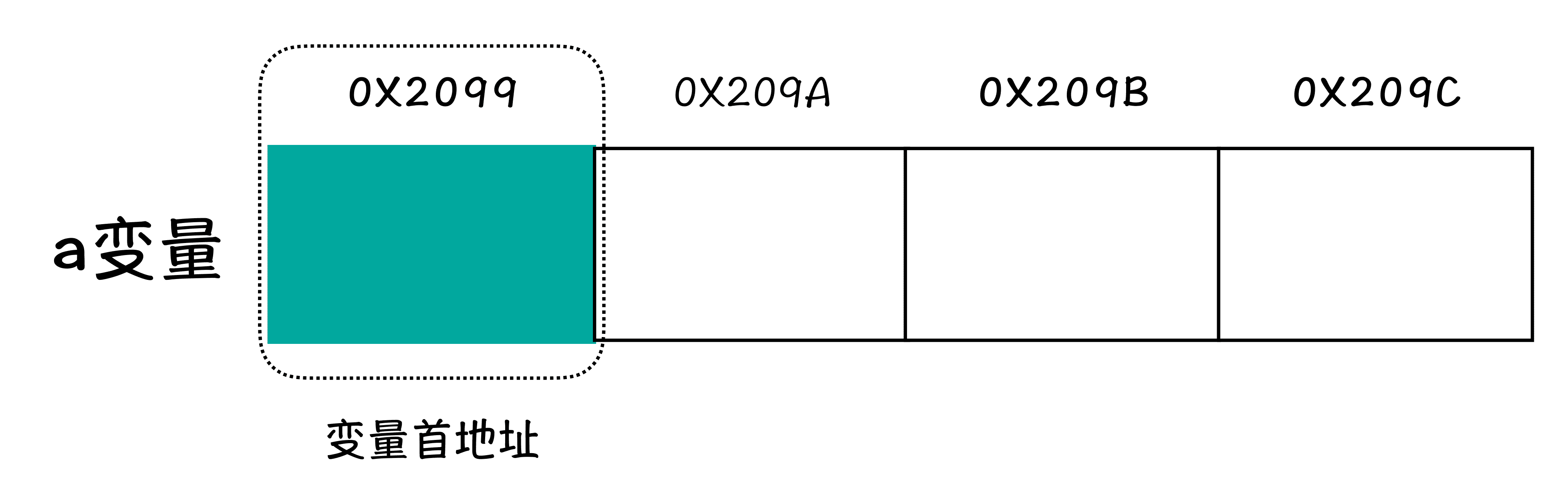
图 4:变量的首地址
看到了变量的地址信息以后,下面就让我们来看一看与数组相关的地址信息,看下面这段程序:
#include <stdio.h>
int main() {
int arr[100];
printf("&arr[0] = %p\n", &arr[0]); // 输出 arr[0] 的地址
printf("&arr[1] = %p\n", &arr[1]); // 输出 arr[1] 的地址
printf(" arr = %p\n", arr); // 输出 arr 的信息
return 0;
}
上述代码,会输出三行信息,针对这三行信息,每个人的程序运行出来的结果很可能是不一样的,这一点没关系,可你一定会发现如下规律:第一个地址与第二个地址之间差 4 字节,而输出的第三个地址与第一个地址完全相同。
下面我就来解释一下这两个现象。
- 第一,数组的每个元素之间在内存中是连续存储的,也就是对上面程序中的数组而言,第一个元素占头 4 个字节,第二个元素紧接着占接下来的 4 个字节的存储空间。再结合上面说到的变量首地址的概念,你就很容易理解为什么头两个地址之间差 4 了。
- 第二,在程序中,当我们单独使用数组名字的时候,实际上就代表了整个数组的首地址,整个数组(arr[100])的首地址就是数组中第一个元素的首地址,也就是 arr[0] 的地址。
在这里,我们来进一步看一下这个等价关系,arr 等价于 &arr[0](取地址 arr[0]),实际上我们的地址也是支持 +/- 法的,也就是 arr + 0 等价于 arr[0] 的地址,那么 arr[1] 的地址等于 arr 加几呢?
你可能会认为是加 4,这种直觉还是值得鼓励的,可结果不正确,这个和地址的类型有关系,后面讲到指针的时候,我再详细的讲给你听。不过,事实上,arr + 1 就等价于 arr[1] 的地址,更一般的 arr + i 就等价于 arr[i] 的地址。关于地址上的 +/- 运算的规则,我在后续的文章中会详细进行讲解。
4. 再看 scanf 函数:其实我是一个“邮递员”
有了上面对于地址的基本认识以后,我们再来回顾一下 scanf 函数的用法,你可能会有新的收获,看如下读入程序:
#include <stdio.h>
int main() {
int a;
scanf("%d", &a);
return 0;
}
上面这个程序,就是一个最简单的读入程序,首先定义一个整型变量 a,然后读入一个整数,存储到 a 中。
学习完了地址以后,你就会意识到,我们传给 scanf 函数的,不是 a 变量,准确来说,而是 a 变量的地址。
为什么要把 a 变量的地址传递给 scanf 函数呢?这个很好理解,你就把 scanf 函数当成邮递员,邮递员得到了信件以后,需要知道这个数据放到哪个邮箱里面啊,而你需要做的就是把邮箱地址告诉这个邮递员即可,就是变量 a 的地址,这样 scanf 函数就能把获得的数据,准确的放到 a 变量所对应的内存单元中了。
一起动手,搞事情
思考题:去掉倍数
设计一个去掉倍数的程序,要求如下:
首先读入两个数字 n 和 m,n 的大小不会超过 10,m 的大小都不会超过 10000;
接下来读入 n 个各不相同的正整数,输出 1 到 m 中,有哪些数字无法被这 n 个正整数中任意的一个整除。
下面给出一组输入和输出的样例,以供你来参考。
输入如下:
3 12
4 5 6
输出如下:
1 2 3 7 9 11
用数组,做递推
有了对数组的基本认识之后,就让我们来看一下今天的任务应该如何求解。请你观察下面的位运算性质:
y = x & (x - 1)
我们看到,我们将 x 与 x - 1 这两个数字做按位与(这个名词的含义很简单,你随便查查资料就知道了),按位与以后的结果再赋值给 y 变量,下面我们着重来讨论 y 变量与 x 变量之间的关系。
既然是位运算,我们就需要从二进制的角度来思考这个问题。首先思考 x - 1 的二进制表示与 x 二进制表示之间的关系,当 x 二进制表示的最后一位是 1 的时候,x - 1 就相当于将 x 最后的一位 1 变成了 0,如果 x 二进制表示最后一位是 0 呢,计算 x - 1 的时候,就会试图向前借位,应该是找到最近的一位不为 0 的位置,将这一位变成 0,原先后面的 0 都变成 1,如下图所示:
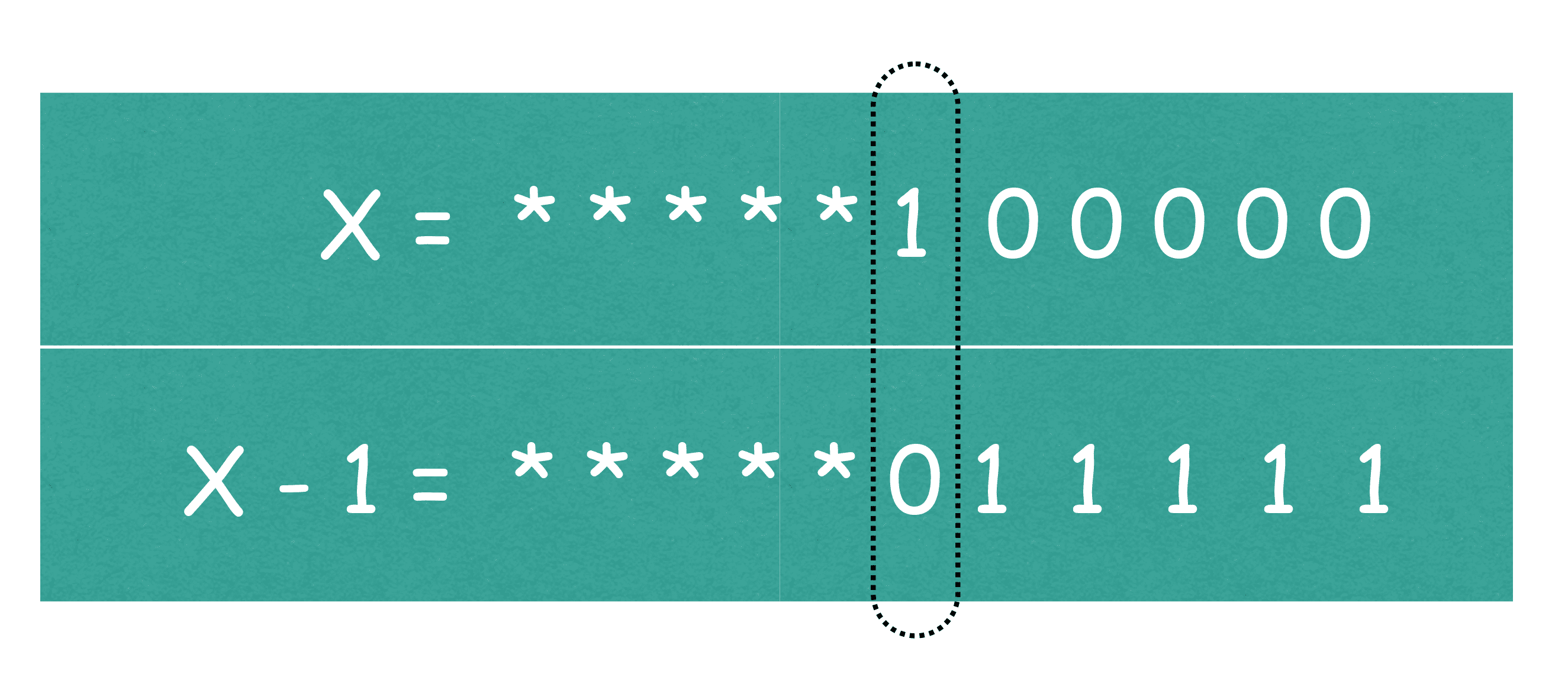
图 5:x 与 x-1 的二进制表示
图中打 * 的部分,代表了 x 与 x - 1 二进制表示中完全相同的部分。根据按位与操作的规则,相应位置都为 1,结果位就为 1,那么 x 与上 x - 1 实际效果等效于去掉 x 二进制表示中的最后一位 1,从而我们发现原来 y 变量与 x 变量在二进制表示中,只差一个 1。
回到原任务,如果我们用一个数组 f 记录相应数字二进制表示中 1 的数量,那么 f[i] 就代表 i 这个数字二进制表示中 1 的数量,从而我们可以推导得到 f[i] = f[i & (i - 1)] + 1,也就是说 i 比 i & (i - 1) 这个数字的二进制表示中的 1 的数量要多一个,这样我们通过一步计算就得到 f[i] 的结果。
下面给你准备了一份参考程序:
#include <stdio.h>
int f[1001];
int main() {
int n;
scanf("%d", &n);
f[0] = 0;
for (int i = 1; i <= n; i++) {
f[i] = f[i & (i - 1)] + 1;
}
for (int i = 1; i <= n; i++) {
if (i != 1) printf(" “);
printf("%d”, f[i]);
}
printf("\n");
return 0;
}
这个程序中,首先先读入一个整数 n,代表要求解的范围,然后循环 n 次,每一次通过递推公式 f[i] = f[i & (i - 1)] + 1 计算得到 f[i] 的值,最后输出 1 到 n 中每个数字二进制表示中 1 的个数。
课程小结
通过今天这个任务,你会发现,有了数组以后,我们可以记录一些计算结果,这些计算结果可能对后续的计算有帮助,从而提高程序的执行效率。关于数组的使用,会成为你日后学习中的一个重点,今天就当先热个身吧。下面呢,我来总结一下今天课程中需要你记住的重点:
- 使用数组,可以很方便的定义出一组变量存储空间,数组下标从 0 开始。
- 数据的最基本存储单位是字节,每一个字节都有一个独一无二的地址。
- 一个变量占用若干个字节,第一个字节的地址,是这个变量的首地址,称为:变量地址。
记住今天这些,对于日后学习指针相关知识,会有很大的帮助。好了,今天就到这里了,我是胡光,我们下期见。
文章作者 anonymous
上次更新 2024-05-18