37|如何对数据进行分类和预测?
文章目录
今天我们进入专栏的最后一个模块,补全大数据知识体系最后一块拼图,一起来学习大数据算法。大数据越来越多的和人工智能关联起来,所谓人工智能就是利用数学统计方法,统计数据中的规律,然后利用这些统计规律进行自动化数据处理,使计算机表现出某种智能的特性,而各种数学统计方法,就是大数据算法。关于专栏算法模块的设置,我会围绕数据分类、数据挖掘、推荐引擎、大数据算法的数学原理、神经网络算法几个方面,为你展开大数据算法的“全景图”。
分类是人们认知事物的重要手段,如果你能将某个事物分类得足够细,你实际上就已经认知了这个事物。如果你能将一个人从各个维度,比如专业能力、人际交往、道德品行、外貌特点各个方面都进行正确的分类,并且在每个维度的基础上还能再细分,比如大数据专业能力、Java 编程能力、算法能力也能正确分类,那么可以说你已经完全了解这个人了。
现实中,几乎没有人能够完全将另一个人分类。也就是说,几乎没有人能完全了解另一个人。但是在互联网时代,一个人在互联网里留下越来越多的信息,如果计算机利用大数据技术将所有这些信息都统一起来进行分析,理论上可以将一个人完全分类,也就是完全了解一个人。
分类也是大数据常见的应用场景之一,通过对历史数据规律的统计,将大量数据进行分类然后发现数据之间的关系,这样当有新的数据进来时,计算机就可以利用这个关系自动进行分类了。更进一步讲,如果这个分类结果在将来才会被证实,比如一场比赛的胜负、一次选举的结果,那么在旁观者看来,就是在利用大数据进行预测了。其实,现在火热的机器学习本质上说就是统计学习。
下面我通过一个相对比较简单的 KNN 分类算法,向你展示大数据分类算法的特点和应用,以及各种大数据算法都会用到的数据距离计算方法和特征值处理方法。
KNN 分类算法
KNN 算法,即 K 近邻(K Nearest Neighbour)算法,是一种基本的分类算法。其主要原理是:对于一个需要分类的数据,将其和一组已经分类标注好的样本集合进行比较,得到距离最近的 K 个样本,K 个样本最多归属的类别,就是这个需要分类数据的类别。下面我给你画了一个 KNN 算法的原理图。
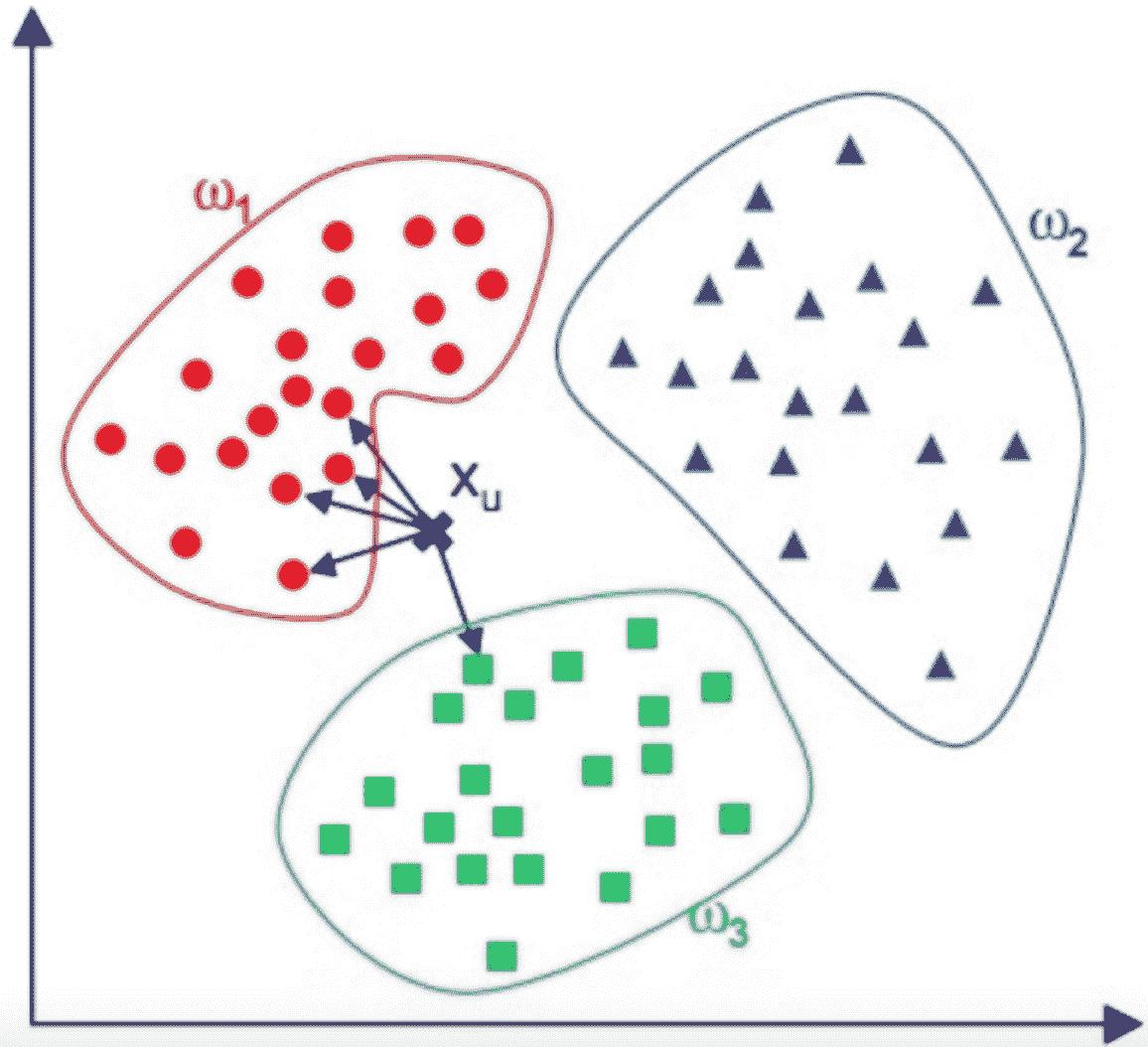
图中,红蓝绿三种颜色的点为样本数据,分属三种类别 [Math Processing Error]w1
文章作者 anonymous
上次更新 2024-01-14