38|如何发掘数据之间的关系?
文章目录
通过上一个模块“大数据分析与运营”的学习,我们知道数据之中蕴藏着关系,如果数据量足够大,这种关系越逼近真实世界的客观规律。在我们的工作和生活中你会发现,网页之间的链接关系蕴藏着网页的重要性排序关系,购物车的商品清单蕴藏着商品的关联关系,通过对这些关系的挖掘,可以帮助我们更清晰地了解客观世界的规律,并利用规律提高生产效率,进一步改造我们的世界。
挖掘数据的典型应用场景有搜索排序、关联分析以及聚类,下面我们一个一个来看,希望通过今天的学习,你能够了解数据挖掘典型场景及其应用的算法。
搜索排序
我们说过 Hadoop 大数据技术最早源于 Google,而 Google 使用大数据技术最重要的应用场景就是网页排名。
当我们使用 Google 进行搜索的时候,你会发现,通常在搜索的前三个结果里就能找到自己想要的网页内容,而且很大概率第一个结果就是我们想要的网页。而排名越往后,搜索结果与我期望的偏差越大。并且在搜索结果页的上面,会提示总共找到多少个结果。
那么 Google 为什么能在十几万的网页中知道我最想看的网页是哪些,然后把这些页面排到最前面呢?
答案是 Google 使用了一种叫 PageRank 的算法,这种算法根据网页的链接关系给网页打分。如果一个网页 A,包含另一个网页 B 的超链接,那么就认为 A 网页给 B 网页投了一票,以下面四个网页 A、B、C、D 举例,带箭头的线条表示链接。
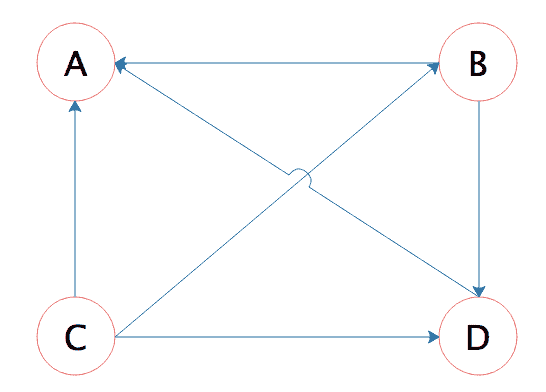
B 网页包含了 A、D 两个页面的超链接,相当于 B 网页给 A、D 每个页面投了一票,初始的时候,所有页面都是 1 分,那么经过这次投票后,B 给了 A 和 D 每个页面 1/2 分(B 包含了 A、D 两个超链接,所以每个投票值 1/2 分),自己从 C 页面得到 1/3 分(C 包含了 A、B、D 三个页面的超链接,每个投票值 1/3 分)。
而 A 页面则从 B、C、D 分别得到 1/2、1/3、1 分。用公式表示就是
PR(A)=PR(B)2+PR(C)3+PR(D)1
PR(A)=PR(B)2+PR(C)3+PR(D)1
文章作者 anonymous
上次更新 2024-01-14