41_大模型_LLMs_LLM生成SFT数据方法面
文章目录
大模型(LLMs)LLM生成SFT数据方法面
来自: AiGC面试宝典
扫码 查看更
一、SFT数据集如何生成?
SFT数据集构建通常有两种方法:人工标注和使用LLM(比如GPT-4)来生成的,人工标注对于构建垂直领域比较合适,可以减少有偏数据,但是成本略高;使用LLM生成,可以在短时间内生成大量数据。
SFT数据集构建以及SFT微调Pipeline如下图所示:
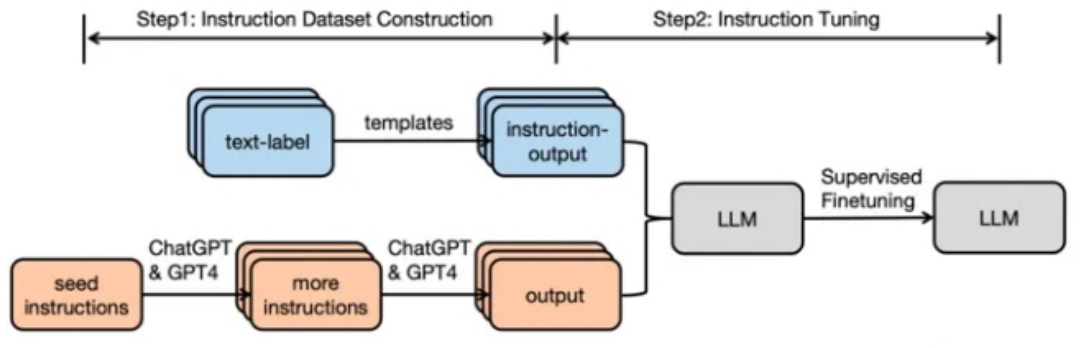
Figure 1:General pipeline of instruction tuning.
二、Self-Instruct 篇2.1 什么是 Self-Instruct ?
Self-Instruct(https://arxiv.org/abs/2212.10560):一个通过预训练语言模型自己引导自己来提高的指令遵循能力的框架。
2.2 Self-Instruct 处理思路?
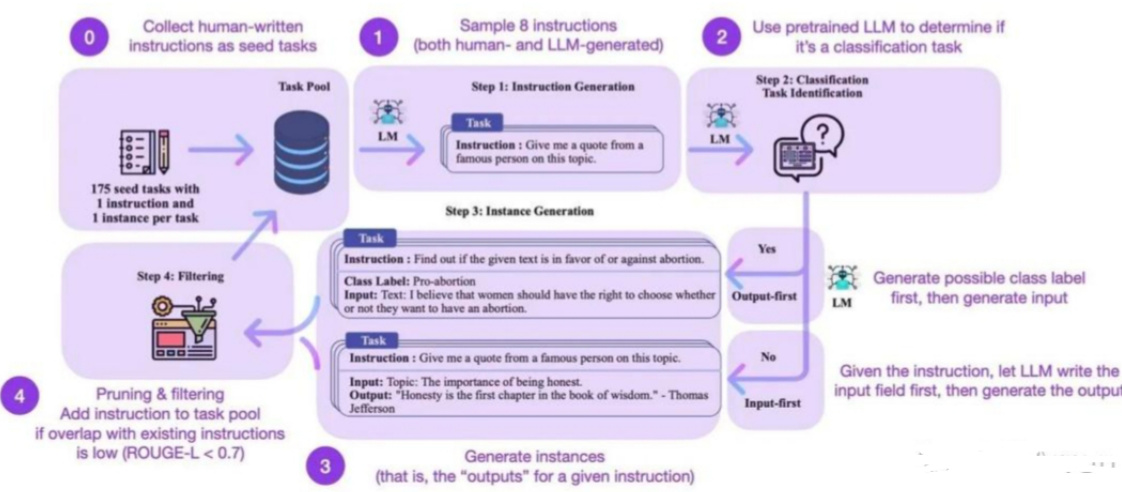
• 步骤1:作者从 175个种子任务中随机抽取 8 条自然语言指令作为示例,并提示InstructGPT生成更多的任务指令。
• 步骤2:作者确定步骤1中生成的指令是否是一个分类任务。如果是,他们要求 InstructGPT 根据给定的指令为输出生成所有可能的选项,并随机选择特定的输出类别,提示 InstructGPT 生成相应的“输入”内容。对于不属于分类任务的指令,应该有无数的“输出”选项。作者提出了“输入优先”策略,首先提示 InstructGPT根据给定的“指令”生成“输入”,然后根据“指令”和生成的“输入”生成“输出”。
• 步骤3:基于第 2 步的结果,作者使用 InstructGPT 生成相应指令任务的“输入”和“输出”,采用“输出优先”或“输入优先”的策略。
• 步骤4:作者对生成的指令任务进行了后处理(例如,过滤类似指令,去除输入输出的重复数据),最终得到52K条英文指令
三、Backtranslation 篇3.1 什么是 Backtranslation?
回译在传统的机器学习中是一种数据增强方法,比如从中文翻译成英文,再从英文翻译会中文,这样生成的中文与原来的中文在语义上是一致的,但是文本不同;然而SFT数据生成的回译(https://arxiv.org/abs/2308.06259)则是通过输出来生成指令,具体步骤如下图所示:
Step1.Self-Augmentation. Train abackwardmodel $M_{y x}$ to
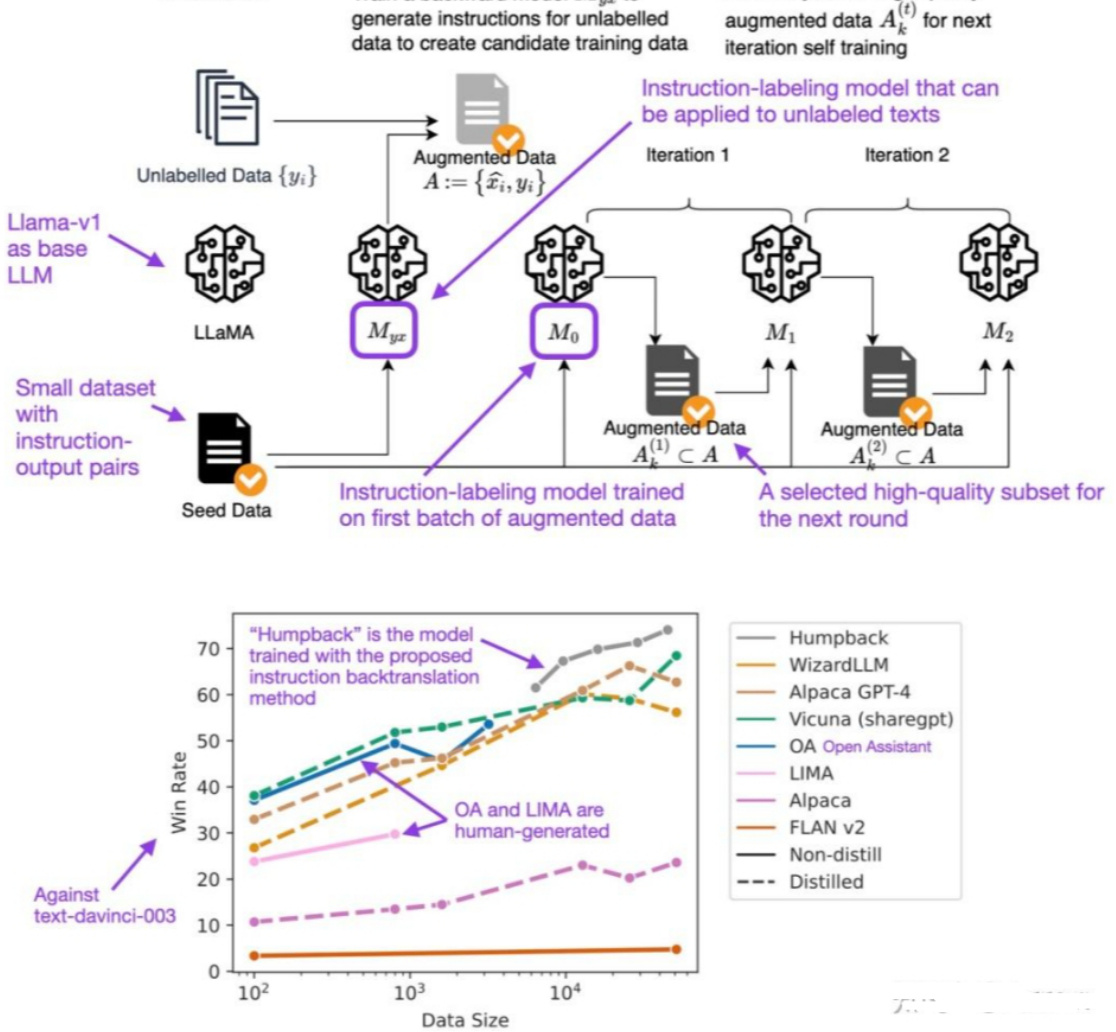
Step 0. Initialization
Step 2. Self-Curation. Iterativelyselecthigh-quality
文章作者 大模型
上次更新 2025-03-09