互联网_浅谈DeepSeek的成本和跟行业对比
文章目录
浅谈 DeepSeek 的成本和跟行业对比
华泰研究
2025 年 2 月 04 日│美国
动态点评
DS 引发资本市场对算力增长展望的担忧,但或迎来杰文斯悖论
DeepSeek(DS)低开发成本引发全球投资者对美国科技巨头高成本投资的质疑,但其对算力的影响也许迎来杰文斯悖论(Jevons Paradox)。微软 CEOSatya Nadella 认为 DS 热潮或带来杰文斯悖论时刻,即通过降低成本推动需求增加,从而促进 AI 商业化趋势的加速。ASML CEO Christophe Fouquet也认同大模型训练成本降低可推动 AI 应用的发展,从而带动更多芯片需求。我们认为,不管 DS 或其他类似模型的冒起,在 Test-time Scaling Law 对算力需求的驱动下,推理芯片或存在较大增长潜力。相较于训练芯片,推理芯片的研发门槛较低,包括博通和 Marvell 等,以及台系 ALChip、GlobalUni和联发科均涉足 ASIC 设计业务。TrendForce 曾提及英伟达或将成立 ASIC部门。我们认为英伟达或意识到来自科技巨头的自研芯片竞争,包括亚马逊Trainium、谷歌 TPU、Meta MTIA 以及微软 Maia,特别在推理端。
DS 较低的训练成本会否影响算力需求?
Meta Llama 3.1 与 DS V3 技术报告显示,Llama 3.1 405B 模型训练需 30MH100 小时和 15T Tokens 训练语料,成本超 6000 万美元,而 DS V3(37B激活参数)只需 2.8M H800 小时,训练成本约 600 万美元。不过,该成本仅包括训练 V3 的 GPU 租赁成本(2048 块 H800 训练一次的花销),并不包括人员薪酬、数据标注费用,以及训练失败产生的额外费用等。从推理API 调用价格看,V3 输入/输出价格分别为 0.9/1.1 美元每百万 Token,仅为o1 模型的 2-3%,Llama 3.1 405B 的 30%。我们认为 DS 实现低成本的原因包括:1)采用 FP8 和 FP32 混合精度,FP8 对算力需求更少;2)采用DualPipe 双重流水线设计,减少数据传输和计算之间的等待时间,提高计算资源利用率;3)DS作为后发追赶者也可在现有玩家的算法上做深度优化。
FP8 混合精度训练如何提升 DS V3 的计算效率?
FP8 混合精度训练是 DS V3 提高计算效率的核心。此前,行业已从 FP32(全浮点)转向 FP16(半浮点)训练,而 FP8 能进一步把算力需求减半。在 V3 中,前向传播、激活反向传播以及权重反向传播模块均采用 FP8 计算,速度相较 FP16 提高 100%。为保证精度,敏感算子如 MoE 门控模块、注意力算子等,仍保留 FP16 或 FP32 格式,使精度损失控制在 0.25%以内。目前,使用 FP8 进行大模型训练的案例较少,微软曾于 2023 年做过相关研究,特斯拉也采用 FP8 训练其自动驾驶模型,均认为低精度训练是降本的重要路径。且英伟达 Hopper 和 Ada Lovelace 架构均增加对 FP8 的硬件支持。本次,FP8 的推出或促进更多优化技巧和混合精度训练流程绑定,且英伟达 Blackwell 架构更进一步拓展低精度范围,支持 FP6 和 FP4 格式。
R1 模型对于大模型技术发展、算力需求和行业格局有何影响?
1)从技术发展看:R1 证明无需大量人工标注的强化学习的潜力,有望突破传统大模型依赖监督数据微调的限制;2)从算力需求看:R1 推动 AI 训练与推理进入低成本、高效学习的新模式,有望加速 ASIC 在推理端落地。我们预计 GPU 与 ASIC 两种芯片不是零和博弈,并将长期共存,为终端应用场景提供兼具两者优势的解决方案;3)从行业格局看:R1 的发布或较大影响以博通、Marvell 为代表的 ASIC 设计公司,其将或面临英伟达的跨赛道竞争;液冷、光模块和铜缆需求或因训练效率提升受短期影响,但在杰文斯悖论推动下,AI 应用与推理的增长潜力将驱动其长期发展。但我们认为,台积电受此影响较小,主要系其先进制程 GPU 和 ASIC 的领先地位;此外,随着 ASIC 的升级,HBM 的规格和需求也将保持增长,利好美光和海力士。
风险提示:大模型技术研发进展不及市场预期,贸易科技摩擦风险。
互联网
增持 (维持)
研究员 何翩翩 SAC No. S0570523020002 [email protected] SFC No. ASI353 +(852) 3658 6000 联系人 易楚妍 SAC No. S0570124070123 [email protected] +(86) 21 2897 2228
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除
行业报告资源群
- 进群福利:进群即领万份行业研究、管理方案及其他学
习资源,直接打包下载 - 每日分享:6份行研精选报告、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

微信扫码,长期有效
知识星球 行业与管理资源
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。

同等英伟达 H800 数量与算力下,GPT-4 的成本为多少?
根据 DeepSeek 2024 年 12 月公布的 V3 模型技术报告,其每万亿 tokens(trillion T)需要18 万(180K)H800 GPU 小时进行训练。DeepSeek 采用 14.8 trillion tokens 训练语料,因此总预训练计算量约为 266.4 万(2664K)H800 GPU 小时( $\langle180|\times\times14.8$ trillion)。如果使用 2048 块 H800 GPU 组成集群进行训练,每块 GPU 需要约 1301 小时(2664K GPU小时÷2048 块 GPU),即大约 54 天完成训练。
我们也参考了英伟达在 2021 年发表的论文《Efficient Large-Scale Language ModelTraining on GPU Clusters Using Megatron-LM》,计算不同参数的 GPU 在结合数据并行、流水线模型并行、张量模型并行及服务器通信优化等多种加速方式下的有效算力。根据公式 X=8TP/Nt(X 是单块 GPU 的有效算力,T 为模型训练数据 Token 总数,P 是模型参数量(每次激活的参数量),N 是所使用 GPU 数量,t 训练时间),得出 DeepSeek 单块 GPU的有效算力约为 458 TeraFLOPs。我们也尝试假设 GPT-4 采用 DeepSeek-V3 相同的浮点精度(FP8)和有效算力,在同样采用 2048 个 GPU 集群的情况下,训练时间将拓展至 142天,约合 6980K H800 GPU 小时( $(142~\times24\times~2048)$ ,若以 2 美元每 GPU 小时计算,即 1396 万美元。在假设相同的浮点精度(FP8)和有效算力,若 GPT-4 需在 54 天内完成训练,需要约 5300 块 H800 GPU,约 6980K H800 GPU 小时,约 1396 万美元训练成本。对比 GPT-4 原训练方式,采用 A100 GPU,FP16 浮点精度,共耗时 570000K A100 GPU小时,若以 1.3 美元每 GPU 小时计算约 7350 万美元,成本降幅明显。
图表1: 大模型 Pre-Training 训练所需 GPU 测算(GPT-4 若需在 54 天内完成训练,需要约 5300 块 H800 GPU,1396 万美元训练成本)
| 公式参数 | 参数数量 | 每次激活参数 训练Tokens | 总计算量 (8PT) FLOPS | GPU型号 浮点精度 | 单芯片额定算力单芯片有效算力 | (X) | 训练时间 (t) | GPU数量 租赁价格 (n) | 总成本 | |||
| (P) billion | (T) billion | |||||||||||
| 单位 GPT-4 | billion 1750 | 111 | 13,000 | 1.15E+25 | A10080GBSXM | FP16 | TeraFLOPs 624 | TeraFLOPs 56 | 天 95.0 | 个 25,000 | 美元/小时 1.29 | 百万美元 73.5 |
| Llama-3.1 | 405 | 405 | 15,000 | 4.86E+25 | H100SXM | FP16 | 1979 | 439 | 80.0 | 16,000 | 2.15 | 66.0 |
| DeepSeek-V3 | 671 | 37 | 14,800 | 4.38E+24 | H800SXM | FP8 | 3958 | 458 | 54.0 | 2,048 | 2.00 | 5.3 |
| GPT-4(假设) | 1750 | 111 | 13,000 | 1.15E+25 | H800SXM | FP8 | 3958 | 458 | 142.3 | 2,048 | 2.00 | 14.0 |
| GPT-4(假设) | 1750 | 111 | 13,000 | 1.15E+25 | H800SXM | FP8 | 3958 | 458 | 54.0 | 5,397 | 2.00 | 14.0 |
注 1:GPU 测算计算公式参考英伟达 2021 年 8 月论文《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》注 2:DeepSeek V3 模型相关参数与训练成本参考其 2024 年 12 月论文《DeepSeek-V3 Technical Report》资料来源:DeepSeek 官网、Meta 官网、OpenAI 官网、英伟达官网、Medium、Semianalysis、华泰研究预测;其中 GPT-4 的训练时间和 GPU 数量为根据假设测算
图表2: DeepSeek 论文公布的 V3 模型训练成本
| Pre-Training | ContextExtension | Post-Training | Total | |||
| 每万亿Token训 练语料所需时长 | 总训练语料 | 总训练时长 | 总训练时长 | 总训练时长 | 总训练时长 | 总训练成本 |
| H800GPU小时 | 万亿 (T) | H800GPU小时 (千) | H800GPU小时 (千) | H800GPU小时 (千) | H800GPU小时 (千) | 百万美元 |
| 180,000 | 14.8 | 2664 | 199 | 5 | 2,788 | 5.58 |
注:其中假设 H800 的租赁价格为每 GPU 小时 2 美元资料来源:DeepSeek 2024 年 12 月论文《DeepSeek-V3 Technical Report》、华泰研究;
我们发现,市场对模型训练所需 GPU 数量的需求存在较大分歧。我们认为影响 GPU 使用数量的核心在于:1)模型参数数量与每次激活参数数量;2)GPU 型号与峰值算力;3)浮点计算精度。我们认为,1)DeepSeek-V3 采用 MoE 结构,拥有总计 6710 亿参数,每个 Token 上激活 370 亿参数。此外,The Decoder 报道,GPT-4 的 MoE 模型预计拥有 1.75万亿参数,由16个专家组成,每个专家对应1110亿参数。2)A100的单卡FP16TensorCore峰值算力较低,为624TFLOP/s,H100的单卡FP16算力可提升至1979TFLOP/S,但A100并没有 FP8 部署。3)浮点精度方面,理论上精度越高,计算的准确度也应提升,但使用更高精度,如 FP16 和 FP32,会对算力要求有显著增加,从而增加所需的 GPU 资源。在模型训练中,我们需要权衡精度与准确度(precision vs. accuracy tradeoff)。如果提高精度带来的准确度提升微乎其微,那么提升精度反而会造成算力和能源的浪费,得不偿失。此外,训练过程中可通过数据并行、流水线模型并行、张量模型并行以及服务器通信优化等方式进行全面优化,提升训练效率并缩短训练时间。
图表3: Llama 与 DeepSeek 模型训练数据对比
| 公司 | Meta | |||||
| 模型 | Llama2 | Llama3 | Llama3.1 | DeepSeek-V1 | DeepSeek-V2 DeepSeek-V3 | |
| 发布日期 | 2023年7月 | 2024年2月 | 2024年6月 | 2024年1月 2024年5月 | 2024年12月 | |
| 参数量 | 7B | 70B | 70B | 405B | 67B 236B | 671B |
| 训练Token | 2.0T | 2.0T | 15T | 15T 2T | 8.1T | 14.8T |
| 上下文窗口 | 4k | 4k | 8k | 128k 4k | 128K | 128K |
| GPU | NVIDIAA100-80GB | NVIDIAH100TensorCore | NVIDIAH800 | |||
| GPU训练小时 | 0.18M | 1.7M | 6.4M | 30.8M | 172.8K 300.6K | 2.8M |
资料来源:Medium、华泰研究
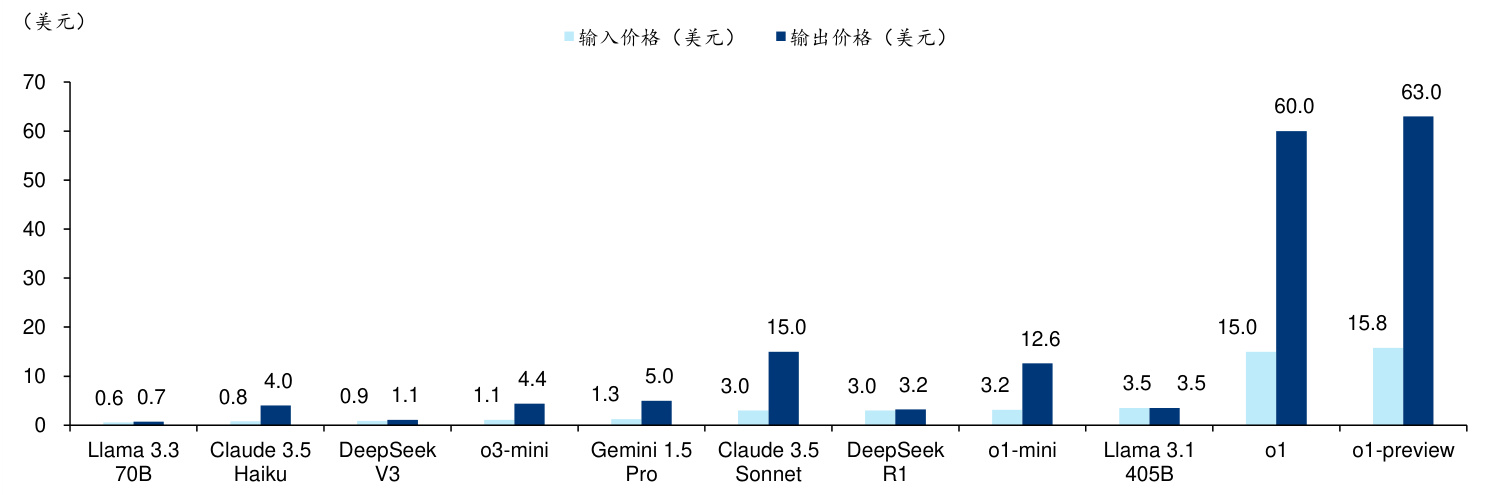
图表4: DeepSeek R1 与 OpenAI o1 模型 API 调用价格对比(每百万 Token)
资料来源:Artificial Analysis、Analytics Vidhya、华泰研究
图表5: DeepSeek 的技术报告(Technical Paper)发表情况,均在 Arxiv 里展示
| 论文名称 | 发表时间 |
| DeepSeekLLM:ScalingOpen-SourceLanguageModelswithLongtermism | 2024/1/5 |
| DeepSeek-Coder:When the Large Language Model MeetsProgramming -The Rise of Code Intelligence | 2024/1/26 |
| DeepSeek-VL:TowardsReal-WorldVision-LanguageUnderstanding | 2024/3/11 |
| DeepSeek-V2:A Strong,Economical,and Efficient Mixture-of-ExpertsLanguageModel | 2024/6/19 |
| DeepSeek-Coder-V2:BreakingtheBarrierofClosed-SourceModelsinCodeIntelligence | 2024/6/17 |
| DeepSeek-V3TechnicalReport | 2024/8/15 |
| 2024/12/27 | |
| DeepSeek-R1:IncentivizingReasoningCapabilityinLLMsviaReinforcementLearning | 2025/1/22 |
注:arXiv 是一个开放的学术文章档案,由康奈尔大学维护和运营。arXiv.org 不进行同行评审。然而,所有提交的文章都要经过一个审核过程,该过程根据主题领域对材料进行分类,并检查其学术价值。作者可在向期刊和峰会提交前或同时向 arXiv 提交预印本文章。资料来源:Arxiv、华泰研究
风险提示
大模型技术研发进展不及市场预期:大模型研发具有较高的不确定性,可能因技术突破受阻、算法优化困难、计算资源不足等因素导致进展缓慢不及市场预期。
贸易科技摩擦风险:若中美贸易与科技摩擦风险加剧,或将导致 DeepSeek 数据使用遭受审查,对于公司产品迭代造成潜在负面影响。
本研报中涉及到未上市公司或未覆盖个股内容,均系对其客观公开信息的整理,并不代表本研究团队对该公司、该股票的推荐或覆盖。
免责声明
分析师声明
本人,何翩翩,兹证明本报告所表达的观点准确地反映了分析师对标的证券或发行人的个人意见;彼以往、现在或未来并无就其研究报告所提供的具体建议或所表迖的意见直接或间接收取任何报酬。
一般声明及披露
本报告由华泰证券股份有限公司(已具备中国证监会批准的证券投资咨询业务资格,以下简称“本公司”)制作。本报告所载资料是仅供接收人的严格保密资料。本报告仅供本公司及其客户和其关联机构使用。本公司不因接收人收到本报告而视其为客户。
本报告基于本公司认为可靠的、已公开的信息编制,但本公司及其关联机构(以下统称为“华泰”)对该等信息的准确性及完整性不作任何保证。
本报告所载的意见、评估及预测仅反映报告发布当日的观点和判断。在不同时期,华泰可能会发出与本报告所载意见、评估及预测不一致的研究报告。同时,本报告所指的证券或投资标的的价格、价值及投资收入可能会波动。以往表现并不能指引未来,未来回报并不能得到保证,并存在损失本金的可能。华泰不保证本报告所含信息保持在最新状态。华泰对本报告所含信息可在不发出通知的情形下做出修改,投资者应当自行关注相应的更新或修改。
本公司不是 FINRA 的注册会员,其研究分析师亦没有注册为 FINRA 的研究分析师/不具有 FINRA 分析师的注册资格。
华泰力求报告内容客观、公正,但本报告所载的观点、结论和建议仅供参考,不构成购买或出售所述证券的要约或招揽。该等观点、建议并未考虑到个别投资者的具体投资目的、财务状况以及特定需求,在任何时候均不构成对客户私人投资建议。投资者应当充分考虑自身特定状况,并完整理解和使用本报告内容,不应视本报告为做出投资决策的唯一因素。对依据或者使用本报告所造成的一切后果,华泰及作者均不承担任何法律责任。任何形式的分享证券投资收益或者分担证券投资损失的书面或口头承诺均为无效。
除非另行说明,本报告中所引用的关于业绩的数据代表过往表现,过往的业绩表现不应作为日后回报的预示。华泰不承诺也不保证任何预示的回报会得以实现,分析中所做的预测可能是基于相应的假设,任何假设的变化可能会显著影响所预测的回报。
华泰及作者在自身所知情的范围内,与本报告所指的证券或投资标的不存在法律禁止的利害关系。在法律许可的情况下,华泰可能会持有报告中提到的公司所发行的证券头寸并进行交易,为该公司提供投资银行、财务顾问或者金融产品等相关服务或向该公司招揽业务。
华泰的销售人员、交易人员或其他专业人士可能会依据不同假设和标准、采用不同的分析方法而口头或书面发表与本报告意见及建议不一致的市场评论和/或交易观点。华泰没有将此意见及建议向报告所有接收者进行更新的义务。华泰的资产管理部门、自营部门以及其他投资业务部门可能独立做出与本报告中的意见或建议不一致的投资决策。投资者应当考虑到华泰及/或其相关人员可能存在影响本报告观点客观性的潜在利益冲突。投资者请勿将本报告视为投资或其他决定的唯一信赖依据。有关该方面的具体披露请参照本报告尾部。
本报告并非意图发送、发布给在当地法律或监管规则下不允许向其发送、发布的机构或人员,也并非意图发送、发布给因可得到、使用本报告的行为而使华泰违反或受制于当地法律或监管规则的机构或人员。
本报告版权仅为本公司所有。未经本公司书面许可,任何机构或个人不得以翻版、复制、发表、引用或再次分发他人(无论整份或部分)等任何形式侵犯本公司版权。如征得本公司同意进行引用、刊发的,需在允许的范围内使用,并需在使用前获取独立的法律意见,以确定该引用、刊发符合当地适用法规的要求,同时注明出处为“华泰证券研究所”,且不得对本报告进行任何有悖原意的引用、删节和修改。本公司保留追究相关责任的权利。所有本报告中使用的商标、服务标记及标记均为本公司的商标、服务标记及标记。
中国香港
本报告由华泰证券股份有限公司制作,在香港由华泰金融控股(香港)有限公司向符合《证券及期货条例》及其附属法律规定的机构投资者和专业投资者的客户进行分发。华泰金融控股(香港)有限公司受香港证券及期货事务监察委员会监管,是华泰国际金融控股有限公司的全资子公司,后者为华泰证券股份有限公司的全资子公司。在香港获得本报告的人员若有任何有关本报告的问题,请与华泰金融控股(香港)有限公司联系。
香港-重要监管披露
• 华泰金融控股(香港)有限公司的雇员或其关联人士没有担任本报告中提及的公司或发行人的高级人员。• 有关重要的披露信息,请参华泰金融控股(香港)有限公司的网页 https://www.htsc.com.hk/stock_disclosure其他信息请参见下方 “美国-重要监管披露”。
美国
在美国本报告由华泰证券(美国)有限公司向符合美国监管规定的机构投资者进行发表与分发。华泰证券(美国)有限公司是美国注册经纪商和美国金融业监管局(FINRA)的注册会员。对于其在美国分发的研究报告,华泰证券(美国)有限公司根据《1934 年证券交易法》(修订版)第 15a-6 条规定以及美国证券交易委员会人员解释,对本研究报告内容负责。华泰证券(美国)有限公司联营公司的分析师不具有美国金融监管(FINRA)分析师的注册资格,可能不属于华泰证券(美国)有限公司的关联人员,因此可能不受 FINRA 关于分析师与标的公司沟通、公开露面和所持交易证券的限制。华泰证券(美国)有限公司是华泰国际金融控股有限公司的全资子公司,后者为华泰证券股份有限公司的全资子公司。任何直接从华泰证券(美国)有限公司收到此报告并希望就本报告所述任何证券进行交易的人士,应通过华泰证券(美国)有限公司进行交易。
美国-重要监管披露
• 分析师何翩翩本人及相关人士并不担任本报告所提及的标的证券或发行人的高级人员、董事或顾问。分析师及相关人士与本报告所提及的标的证券或发行人并无任何相关财务利益。本披露中所提及的“相关人士”包括 FINRA 定义下分析师的家庭成员。分析师根据华泰证券的整体收入和盈利能力获得薪酬,包括源自公司投资银行业务的收入。
• 华泰证券股份有限公司、其子公司和/或其联营公司, 及/或不时会以自身或代理形式向客户出售及购买华泰证券研究所覆盖公司的证券/衍生工具,包括股票及债券(包括衍生品)华泰证券研究所覆盖公司的证券/衍生工具,包括股票及债券(包括衍生品)。
• 华泰证券股份有限公司、其子公司和/或其联营公司, 及/或其高级管理层、董事和雇员可能会持有本报告中所提到的任何证券(或任何相关投资)头寸,并可能不时进行增持或减持该证券(或投资)。因此,投资者应该意识到可能存在利益冲突。
新加坡
华泰证券(新加坡)有限公司持有新加坡金融管理局颁发的资本市场服务许可证,可从事资本市场产品交易,包括证券、集体投资计划中的单位、交易所交易的衍生品合约和场外衍生品合约,并且是《财务顾问法》规定的豁免财务顾问,就投资产品向他人提供建议,包括发布或公布研究分析或研究报告。华泰证券(新加坡)有限公司可能会根据《财务顾问条例》第 32C 条的规定分发其在华泰内的外国附属公司各自制作的信息/研究。本报告仅供认可投资者、专家投资者或机构投资者使用,华泰证券(新加坡)有限公司不对本报告内容承担法律责任。如果您是非预期接收者,请您立即通知并直接将本报告返回给华泰证券(新加坡)有限公司。本报告的新加坡接收者应联系您的华泰证券(新加坡)有限公司关系经理或客 户主管,了解来自或与所分发的信息相关的事宜。
评级说明
投资评级基于分析师对报告发布日后 6 至 12 个月内行业或公司回报潜力(含此期间的股息回报)相对基准表现的预期(A 股市场基准为沪深 300 指数,香港市场基准为恒生指数,美国市场基准为标普 500 指数,台湾市场基准为台湾加权指数,日本市场基准为日经 225 指数,新加坡市场基准为海峡时报指数,韩国市场基准为韩国有价证券指数,英国市场基准为富时 100 指数),具体如下:
行业评级
增持:预计行业股票指数超越基准 中性:预计行业股票指数基本与基准持平 减持:预计行业股票指数明显弱于基准
公司评级
买入:预计股价超越基准 $15%$ 以上
增持:预计股价超越基准 5%~15%
持有:预计股价相对基准波动在-15%~5%之间
卖出:预计股价弱于基准 $15%$ 以上
暂停评级:已暂停评级、目标价及预测,以遵守适用法规及/或公司政策
无评级:股票不在常规研究 覆盖范围内。投资者不应期待华 泰提供该等证券及/或公司相关的持续或补充信息
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除
行业报告资源群
- 进群福利:进群即领万份行业研究、管理方案及其他学
习资源,直接打包下载 - 每日分享:6份行研精选报告、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

微信扫码,长期有效
知识星球 行业与管理资源
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。

法律实体披露
中国:华泰证券股份有限公司具有中国证监会核准的“证券投资咨询”业务资格,经营许可证编号为:91320000704041011J
香港:华泰金融控股(香港)有限公司具有香港证监会核准的“就证券提供意见”业务资格,经营许可证编号为:AOK809
美国:华泰证券(美国)有限公司为美国金融业监管局(FINRA)成员,具有在美国开展经纪交易商业务的资格,经营业务许可编号为:CRD#:298809/SEC#:8-70231
新加坡:华泰证券(新加坡)有限公司具有新加坡金融管理局颁发的资本市场服务许可证,并且是豁免财务顾问。公司注册号:202233398E
华泰证券股份有限公司
南京
南京市建邺区江东中路228 号华泰证券广场1 号楼/邮政编码:210019
电话:86 25 83389999/传真:86 25 83387521
电子邮件:[email protected]
北京
北京市西城区太平桥大街丰盛胡同28 号太平洋保险大厦A 座18 层/
邮政编码:100032
电话:86 10 63211166/传真:86 10 63211275
电子邮件:[email protected]
深圳
深圳市福田区益田路5999 号基金大厦10 楼/邮政编码:518017
电话:86 755 82493932/传真:86 755 82492062
电子邮件:[email protected]
上海
上海市浦东新区东方路18 号保利广场E 栋23 楼/邮政编码:200120
电话:86 21 28972098/传真:86 21 28972068
电子邮件:[email protected]
华泰金融控股(香港)有限公司
香港中环皇后大道中 99 号中环中心 53 楼
电话:+852-3658-6000/传真:+852-2567-6123
电子邮件:[email protected]
http://www.htsc.com.hk
华泰证券(美国)有限公司
美国纽约公园大道 280 号 21 楼东(纽约 10017)
电话:+212-763-8160/传真:+917-725-9702
电子邮件: [email protected]
http://www.htsc-us.com
华泰证券(新加坡)有限公司
滨海湾金融中心 1 号大厦, #08-02, 新加坡 018981
电话: $+65$ 68603600
传真: $+65$ 65091183
$\circledcirc$ 版权所有2025年华泰证券 股份有限公司
文章作者 大模型
上次更新 2025-03-09