传媒互联网_DeepSeek_R1颠覆性在于实现AI平权_重估资产价值
文章目录
传媒
报告日期:2025 年 02 月 04 日
DeepSeek-R1 颠覆性在于实现 AI 平权,重估资产价值传媒互联网行业专题报告
投资要点
中国公司深度求索 DeepSeek 于 25 年 1 月 20 日发布其最新开源模型 DeepSeek-R1,用较低的成本达到了接近于 OpenAI 开发的 GPT-o1 的性能。我们认为,DeepSeek 模型正在激发一波全球性的 AI 浪潮,推动 AI 继续进步。DeepSeek-R1 特点在于:强化学习技术、蒸馏技术、对用户开放思维链输出等。根据 DeepSeek-R1 的基准集表现,我们认为 R1 模型的综合性能已经能并肩OpenAI-o1-1217 版本,综合能力:DeepSeek-R1≈OpenAI O1-1217 $>$ DeepSeek-V3。根据 DeepSeek-R1 蒸馏小模型表现,32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果,其中数学能力、多模态理解能力等测试中都一定程度上优于 OpenAI o1-mini。
在性能并肩的情况下,DeepSeek-R1 的成本优势尤为突出。DeepSeek-R1 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元。性价比完爆 OpenAI o1 以及其 mini 版本:
缓存命中的条件下,每百万输入 tokens 是 OpenAI o1-mini 成本的 1/11,是o1 成本的 1/55。
缓存未命中的条件下,每百万输入 tokens 是 OpenAI o1-mini 成本的 $18%$ ,是 o1 成本的 $3.6%$ 。
输出 API 价格,每百万输出 tokens 是 OpenAI o1-mini 成本的 $18%$ ,是 o1成本的 $3.6%$ 。
我们对 OpenAI 最新推出的 o3-mini 进行成本测算,相较 DeepSeek-R1 几无优势。OpenAI 迅速应对 DeepSeek 挑战,相继推出两款重要的 AI 模型——北京时间 2 月 1 日凌晨推出 o3-mini 和 2 月 3 日晚上推出 Deep Research 智能体。但相较我们分析的 DeepSeek-R1 价格,o3-mini 性价比相较 DeepSeek-R1 几无优势:
缓存命中的条件下,每百万输入 tokens 是 DeepSeek-R1 的 4 倍。
缓存未命中的条件下,每百万输入 tokens 是 DeepSeek-R1 的 2 倍。
输出 API 价格,每百万输出 tokens 是 DeepSeek-R1 的 2 倍。
投资建议:DeepSeek-R1 的颠覆性在于第一次实现中国模型对海外模型,尤其是代表全球领先 AI 水平的 OpenAI 模型的一次成功追赶,通过算法的优化实现 AI平权,打破在算力和芯片上“大力出奇迹”的既定格局,将促使全球 AI 资产的价值重估,尤其是对中国互联网资产有显著的价值提升作用,前期中国互联网资产受中美芯片限售、模型发展略逊等影响估值承压,如港股互联网龙头【腾讯控股、阿里巴巴-W、小米集团-W】、以及其他港股 AI 核心标的【百度集团-SW、第四范式、商汤-W】等。A 股方面,除明确与 DeepSeek 有一定关系的【每日互动、天娱数科】,重点关注偏软的 AI 应用标的价值重估,关注【昆仑万维、视觉中国、盛天网络、掌阅科技】等的投资机会,同时继续重点提示端侧AI 也有望受益于推理成本下降【实丰文化、趣睡科技、博士眼镜、英派斯】等。
风险提示:AI 技术迭代不及预期、AI 应用落地不及预期、政策不确定性、中美关系不确定性等的风险。
行业评级: 看好(维持)
分析师:冯翠婷执业证书号:[email protected]
相关报告
1 《24Q4 业绩预期稳定,25 年
看 AI 产业趋势》 2025.01.17
2 《小红书迎来新一轮国际化发
展起点》 2025.01.15
3 《字节概念年度主线,关注端
侧 AI、AI 应用、红果短剧》
2025.01.12
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除
行业报告资源群
- 进群福利:进群即领万份行业研究、管理方案及其他学
习资源,直接打包下载 - 每日分享:6份行研精选报告、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

微信扫码,长期有效
知识星球 行业与管理资源
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。

正文目录
1 DeepSeek 推出 R1 模型激发新一波全球性的 AI 浪潮
1.1 DeepSeek 采用强化学习技术,基准表现并肩OpenAI-O1正式版. 4
1.2 蒸馏小模型超越OpenAIol.-mini….. . 6
1.3 在性能并肩的情况下,DeepSeek-R1 的成本优势尤为突出 . . 6
OpenAI连续推出两款模型,应对 DeepSeek 挑战, . 8
2.12月1日推出 03-mini,但性价比相较 DeepSeek-R1几无优势, . 8
2.2 2 月3日再推出 Deep Research,专注深度学习和专业信息处理.. 9
3 DeepSeek-R1 颠覆性在于实现 AI 平权,重估资产价值 . 10
图表目录
图 1:DeepSeek-R1 的基准集表现..
图 2: DeepSeek-R1 蒸馏小模型表现 . . 6
图 3: o1 类推理模型输入输出价格(元/1M Tokens) 7
图 4: o3-mini 在数学性能上与 OpenAI 其他模型的对比,与上文提到的 DeepSeek-R1 为 $79.8%$ . 8
图 5: o3-mini 模型输入输出价格(元/1M Tokens) 9
图 6: 人类终极考试评估相关模型表现… 10
表 1: 港股互联网 DeepSeek 及 AI 模型、应用部分相关标的表2:A股传媒互联网 DeepSeek及 AI应用部分相关标的
1 DeepSeek 推出 R1 模型激发新一波全球性的 AI 浪潮
中国公司深度求索 DeepSeek 于 25 年 1 月 20 日发布其最新开源模型 DeepSeek-R1,用较低的成本达到了接近于 OpenAI 开发的 GPT-o1 的性能。这一进展破解了全球人工智能产业长期以来在算力上“大力出奇迹”的路径依赖,其影响波及资本市场。我们认为,DeepSeek 模型正在激发一波全球性的 AI 浪潮,推动 AI 继续进步。
1.1 DeepSeek 采用强化学习技术,基准表现并肩 OpenAI-O1 正式版
1 月 20 日 DeepSeek 官网及 APP 同步上线、正式发布 DeepSeek-R1,并同步开源模型权重。根据 R1 论文,该模型特点在于:强化学习技术、蒸馏技术、对用户开放思维链输出等,即:(1)DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAIol 正式版。(2)DeepSeek-R1 遵循 MITLicense,允许用户通过蒸馏技术借助R1训练其他模型。(3)DeepSeek-R1上线API,对用户开放思维链输出。
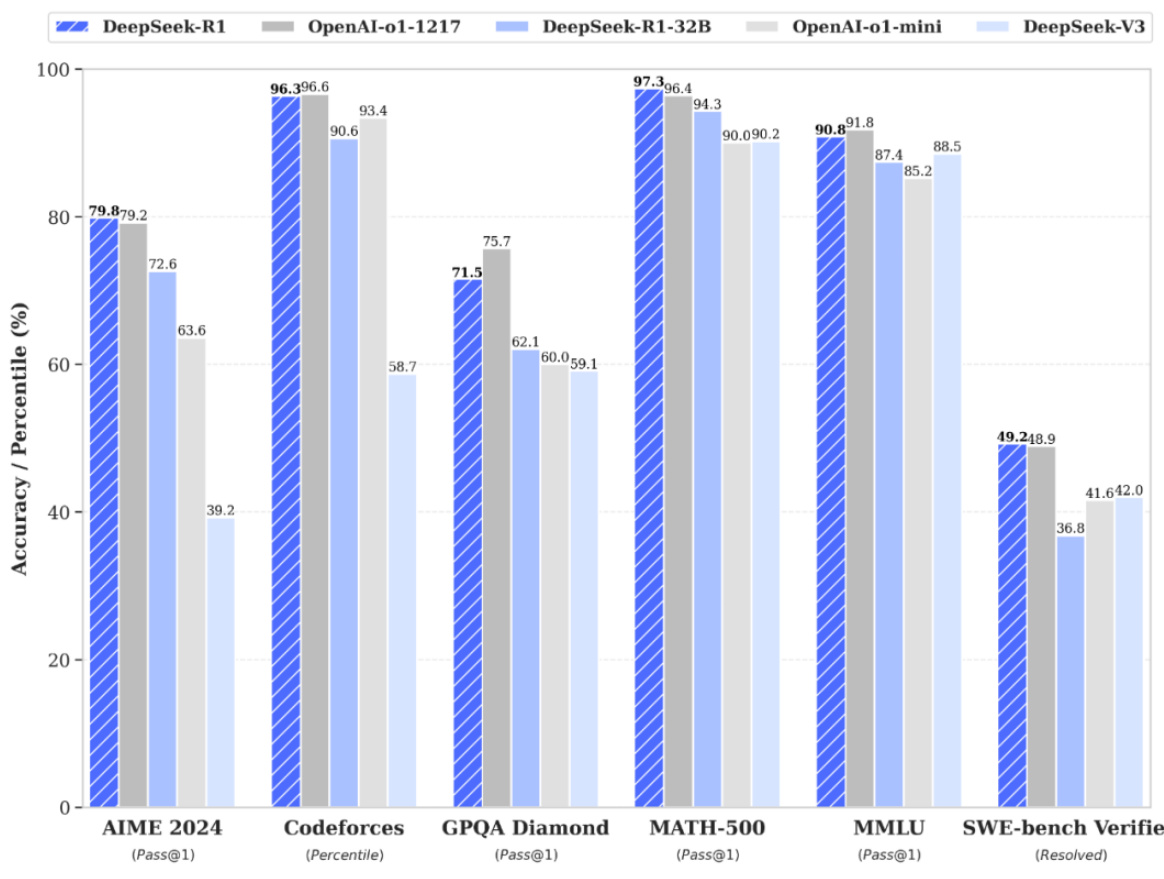
图1: DeepSeek-R1 的基准集表现
资料来源:DeepSeek 官网、浙商证券研究所
根据官网给出的基准集表现,我们认为 R1 模型的综合性能已经能并肩 OpenAI-o1-1217 版本,综合能力:DeepSeek-R1 $\approx$ OpenAI O1-1217 $>$ DeepSeek-V3。
(1)AIME 2024 美国数学邀请赛 2024
DeepSeek-R1: $79.8%$
OpenAI-o1 1217: 79.2%
DeepSeek-V3: $39.2%$
分析:在美国数学邀请赛 2024 测试中,DeepSeek-R1 和 OpenAI-o1 1217 表现非常接近,显示出它们在处理类似任务时具有相似的准确率,但相较 DeepSeek-V3 有非常大的进步,迭代速度和效果非常显著。
(2)Codeforces 编程比赛
DeepSeek-R1: $96.3%$
OpenAI-o1 1217: 96.6%
DeepSeek-V3: $58.7%$
分析:在编程相关的任务上,DeepSeek-R1 和 OpenAI-o1 1217 表现非常接近,显示出它们在处理类似任务时具有相似的准确率,但相较 DeepSeek-V3 有非常大的进步,迭代速度和效果非常显著。
(3)GPQA Diamond 多模态理解
DeepSeek-R1: $71.5%$
OpenAI-o1 1217: $75.7%$
DeepSeek-V3: $59.1%$
分析:在多模态理解任务上,OpenAI-o1 1217 表现最佳,其次是 DeepSeek-R1,但相较 DeepSeek-V3 有非常大的进步,迭代速度和效果非常显著。
(4) MATH-500 数学专项
DeepSeek-R1: $97.3%$
OpenAI-o1 1217: 96.4%
DeepSeek-V3: $90.2%$
分析:在 MATH-500 数学专项测试上,三个模型的表现都非常出色,显示出它们在数学领域的强大能力,DeepSeek-V3 略差一点。
(5)MMLU 自然语言理解
DeepSeek-R1: $90.8%$
OpenAI-o1 1217: 91.8%
DeepSeek-V3: $88.5%$
分析:在自然语言理解任务上,三个模型的表现都非常出色,显示出它们在数学领域的强大能力,DeepSeek-V3 略差一点。
(6)SWE-bench Verified 软件工程
DeepSeek-R1: $49.2%$
OpenAI-o1 1217: 48.9%
DeepSeek-V3: $42.0%$
分析:在软件工程相关任务上,DeepSeek-R1 表现最佳,其次是 OpenAI-o1 1217,DeepSeek-V3 的表现相对较低。
1.2 蒸馏小模型超越 OpenAI o1-mini
DeepSeek-R1 在开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini的效果。
图2: DeepSeek-R1 蒸馏小模型表现
| AIME 2024 pass@1 | AIME 2024 cons@64 | MATH- 500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating | |
| GPT-40-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759.0 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717.0 |
| 01-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820.0 |
| QwQ-32B | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316.0 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954.0 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189.0 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481.0 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691.0 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205.0 |
| DeepSeek-R1-Distill-Llama-7OB | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633.0 |
资料来源:DeepSeek 官网、浙商证券研究所
根据官网给出的 DeepSeek-R1 蒸馏小模型表现,32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果,其中数学能力、多模态理解能力等测试中都一定程度上优于OpenAI o1-mini,而 OpenAI o1-mini 的编程能力依然突出。
1.3 在性能并肩的情况下,DeepSeek-R1 的成本优势尤为突出
DeepSeek 此次推出的推理大模型 DeepSeek-R1,其不仅性能比肩 OpenAI-o1,并且其所需的训练成本可能只有后者的约 1/20(仅用了 2048 个 H800GPU,花了两个月的时间训练完成,仅花费了约 558 万美元),API 的定价更是只有后者的约 1/28,相当于使用成本降低了约 $97%$ 。
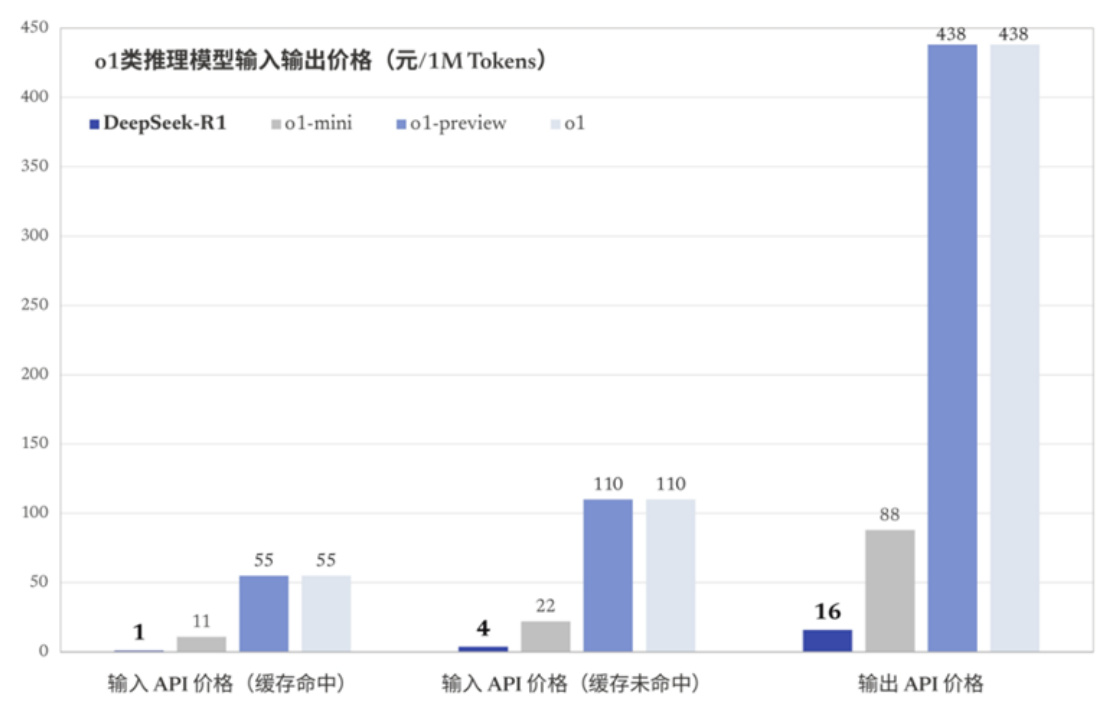
图3: o1 类推理模型输入输出价格(元/1M Tokens)
资料来源:DeepSeek 官网、浙商证券研究所
根据官网,DeepSeek-R1 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元。性价比完爆OpenAI ol以及其 mini 版本。
缓存命中的条件下,每百万输入 tokens 是 OpenAI o1-mini 成本的 1/11,是 o1 成本的 1/55。
缓存未命中的条件下,每百万输入 tokens 是 OpenAI o1-mini 成本的 $18%$ ,是 o1成本的 $3.6%$ 。
输出 API 价格,每百万输出 tokens 是 OpenAI o1-mini 成本的 $18%$ ,是 o1 成本的$3.6%$ 。
DeepSeek 官方公布的数据来看,其 DeepSeek-V3 的训练仅用了约 2080 张英伟达 H800加速卡,这部分的芯片投资大约为 4000 万美元左右。而且,DeepSeek 训练其 AI 模型也并不一定非要拥有庞大的自有的硬件基础设施,其完全可以通过租用第三方的硬件基础设施来对自己的大模型进行训练。
也就是说,DeepSeek 采用并不先进的 AI 芯片,以更低的算力要求和更低的成本,达到了 OpenAI 等美国 AI 技术厂商的顶级 AI 大模型的效果。这一成就被认为对美国的人工智能领导地位构成威胁,不仅引发了 OpenAI、Meta、谷歌等众多大模型厂商恐慌,还引发了英伟达等 AI 芯片企业的价值重估和股价大跌。
2 OpenAI 连续推出两款模型,应对 DeepSeek 挑战
OpenAI 迅速响应市场变化、保持在 AI 领域的领先地位,推出了两款重要的 AI 模型o3-mini 和 Deep Research 智能体以应对 DeepSeek 的挑战。
2.1 2 月 1 日推出 o3-mini,但性价比相较 DeepSeek-R1 几无优势
北京时间 2 月 1 日凌晨,为应对 DeepSeek-R1 所带来的竞争,OpenAI 正式发布了 o3-mini 模型,这也是 OpenAI 推理系列中最新、最具成本效益的模型,并且已在 ChatGPT 和API 中开放使用。
o3-mini 是一款轻量级版本的 o3 模型,专注于提供高效能的同时大幅降低使用成本。这款模型特别适合需要频繁调用且对计算资源有限制的应用场景。此外,o3-mini 在多项基准测试中表现优异,尤其是在编码、逻辑处理等任务上,显示出了其优于原来版本 o1-mini及 o3 模型的性价比优势。
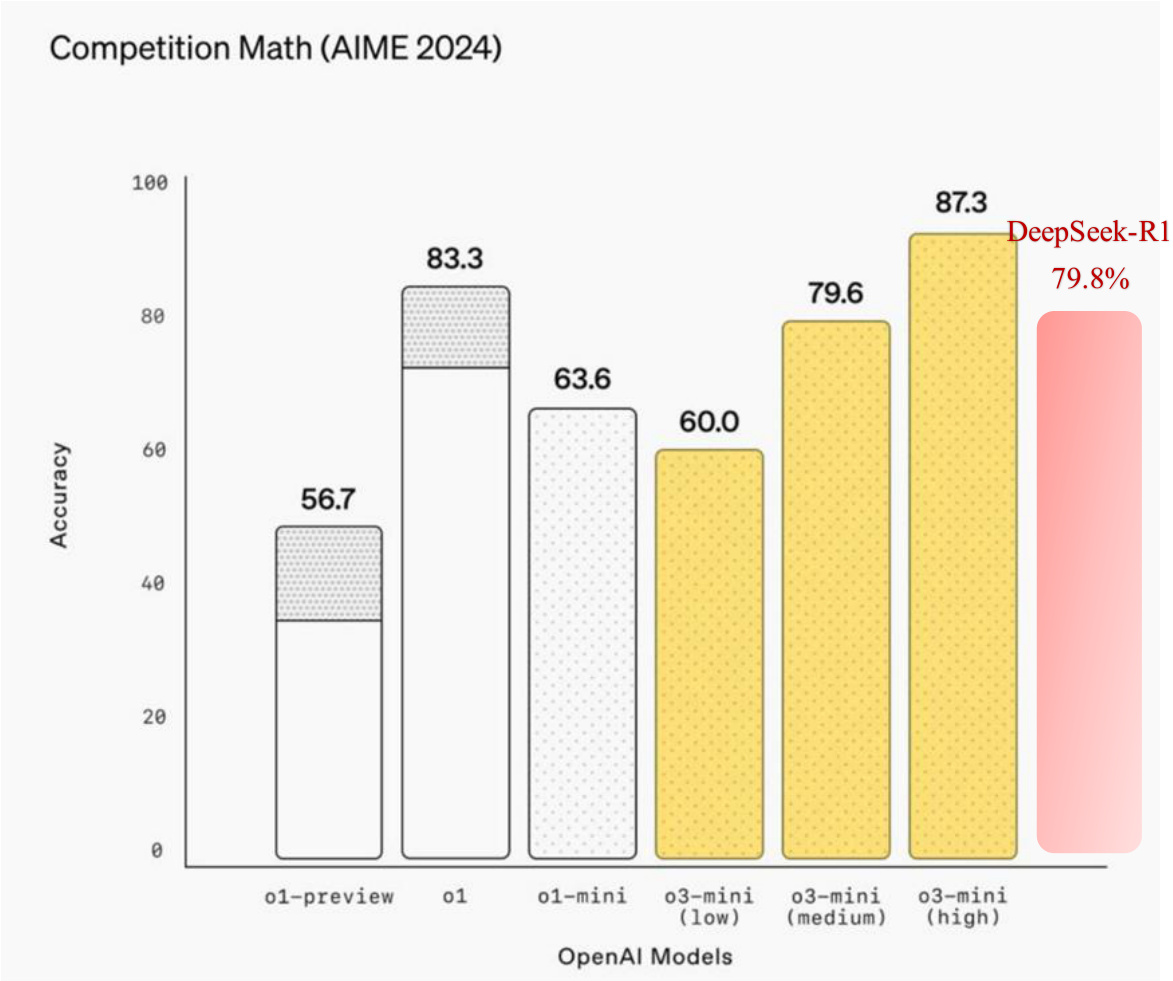
图4: o3-mini 在数学性能上与 OpenAI 其他模型的对比,与上文提到的 DeepSeek-R1 为 $79.8%$
资料来源:OpenAI 官网、浙商证券研究所
图5: o3-mini 模型输入输出价格(元/1M Tokens)
| Model | Pricing | PricingwithBatchAPi*** |
| o3-mini | $1.10/1Minputtokens | $0.55/1Minputtokens |
| $0.55/1Mcached*inputtokens | ||
| $4.40/1Moutput**tokens | $2.20/1Moutput**tokens |
资料来源:OpenAI 官网、浙商证券研究所
备注:
*Cached prompts are offered at a $50%$ discount compared to uncached prompts.
**Output tokens include internal reasoning tokens generated by the model that are not visible in API responses.
$\ast\ast\ast$ Batch API pricing requires requests to be submitted as a batch. Responses will be returned within 24 hours for a $50%$ discount.
据 OpenAI 官网介绍,o3-mini 的价格比 OpenAI o1-mini 便宜 $63%$ ,比正式版 o1 便宜$93%$ 。开发者可根据需求选择高、中、低三种推理强度,让 o3-mini 在处理复杂问题时进行深度思考,平衡速度和准确性。
具体来说,目前 ChatGPT 免费用户首次可以体验一个有限速率的 o3-mini 版本,速率限制与现有的 GPT-4o 限制类似;Plus 用户可选择 o3-mini-high 更高智能版本;每月支付200 美元的 Pro 用户可无限使用 o3-mini 和 o3-mini-high;API 层面,o3-mini 输入 1.10 美元/百万 token、输出 4.40 美元/百万 token,价格比 o1-mini 便宜 $63%$ ,比正式版 o1 便宜$93%$ ,但仍是 GPT-4o mini 的 7 倍左右。
但相较我们上文分析的 DeepSeek-R1 价格,性价比相较 DeepSeek-R1 几无优势。我们以 2 月 4 日美元兑人民币汇率 1 美元 $=7.25$ 元人民币进行测算:
缓存命中的条件下,每百万输入 tokens 是 DeepSeek-R1 的 4 倍。
缓存未命中的条件下,每百万输入 tokens 是 DeepSeek-R1 的 2 倍。
输出 API 价格,每百万输出 tokens 是 DeepSeek-R1 的 2 倍。
2.2 2 月 3 日再推出 Deep Research,专注深度学习和专业信息处理
2 月 3 日晚上,OpenAI 再推出 Deep Research 模型,这是一个使用推理来综合大量在线信息并为用户完成多步骤研究任务的智能体,旨在帮助用户进行深入、复杂的信息查询与分析。目前,Pro 用户现已可用,接下来还将开放给 Plus 和 Team 用户使用。
对于最近发布的「人类终极考试」评估,在专家级问题上对广泛学科的人工智能进行了测试,支持 DeepResearch 的模型以 $26.6%$ 的准确率创下了新高。
这项测试包括 3,000 多个多项选择题和简答题,涵盖了从语言学到火箭科学、古典文学到生态学的 100 多个学科。与 o1 相比,进步最大的是化学、人文和社会科学以及数学。支持 DeepResearch 的模型展示了一种类人方法,可以在必要时有效地寻找专业信息。
图6: 人类终极考试评估相关模型表现
| Model Accuracy (%) |
| GPT-40 3.3 |
| Grok-2 3.8 |
| Claude3.5Sonnet 4.3 |
| Gemini Thinking 6.2 |
| OpenAlo1 16 |
| DeepSeek-R1* 9.4 |
| OpenAlo3-mini(medium)* 10.5 |
| OpenAlo3-mini(high)* 13.0 |
| OpenAl deep research** 26.6 |
| *Model is not multi-modal,evaluated on text-only subset. **withbrowsing+pythontools |
资料来源:OpenAI 官网、浙商证券研究所
3 DeepSeek-R1 颠覆性在于实现 AI 平权,重估资产价值
DeepSeek-R1 的最大价值在于第一次实现中国模型对海外模型,尤其是代表全球领先AI 水平的 OpenAI 模型的一次成功追赶,通过算法的优化实现 AI 平权。面对越来越大的模型,训练模型所需的 AI 算力不断飙升,“大力出奇迹”这一算力霸权开始左右人工智能的发展。英伟达创始人兼首席执行官黄仁勋就据此提出过“黄氏定律”:在计算架构改进的推动下,人工智能芯片的性能每年可提升 1 倍,速度远超摩尔定律。
根据我们上文的分析,DeepSeek-R1 已经实现性能上的追赶和性价比上的超越,同时从两个维度极大地推进了 AI 发展的进程:
一是从算力到应用,继续大幅降低模型的使用成本,使AI 应用的爆发加快落地。
二是盘活了整个国产 AI 市场,从国产芯片到国产大模型,再到国产 AI 应用,大幅提升了市场对整个国产 AI 产业链的信心。
DeepSeek-R1 打破在算力和芯片上“大力出奇迹”的既定格局,将促使全球 AI 资产的价值重估,尤其是对中国互联网资产有显著的价值提升作用,因为前期中国互联网资产受中美芯片限售、模型发展略逊等影响估值承压,例如港股互联网龙头【腾讯控股、阿里巴巴-W、小米集团-W】、以及其他港股 AI 核心标的【百度集团-SW、第四范式、商汤-W】等。A 股方面,除明确与 DeepSeek 有一定相关性的【每日互动(幻方量化的创始合伙人之一徐进是每日互动的联合创始人之一)、天娱数科(为 DeepSeek提供投放业务)】,重点关注偏软的 AI 应用标的价值重估,关注【昆仑万维、视觉中国、盛天网络、掌阅科技】等的投资机会,同时继续重点提示端侧 AI 也有望受益于推理成本下降【实丰文化、趣睡科技、博士眼镜、英派斯】等。
表1: 港股互联网 DeepSeek 及 AI 模型、应用部分相关标的
| 证券代码 | 证券名称 | 股价 (单位:元人民币) | 2024EPSAdj. | 2025EPSAdj | 2024PE | 2025PE |
| 0700.HK | 腾讯控股 | 376.27 | 22.06 | 24.61 | 17.05 | 15.29 |
| 9988.HK | 阿里巴巴-W | 87.50 | 7.90 | 8.89 | 11.08 | 9.85 |
| 1810.HK | 小米集团-W | 35.33 | 0.92 | 1.12 | 38.40 | 31.43 |
| 9888.HK | 百度集团-SW | 78.61 | 9.01 | 9.07 | 8.72 | 8.67 |
| 6682.HK | 第四范式 | 53.90 | -0.71 | -0.03 | ||
| 0020.HK | 商汤-W | 1.57 | -0.11 | -0.07 |
资料来源:Bloomberg、浙商证券研究所备注:数据日期为 2025 年 2 月 3 日收盘价,盈利预测及估值统一使用 Bloomberg 一致预期
表2: A 股传媒互联网 DeepSeek 及 AI 应用部分相关标的
| 证券代码 | 证券名称 | 总市值/亿元 | 24E净利 | 25E净利 | 24E PE | 25E PE | 相关概念 |
| 300766.SZ | 每日互动 | 94.51 | DeepSeek相关+数据要素 | ||||
| 002354.SZ | 天娱数科 | 100.93 | 0.02 | 0.42 | 242.91 | DeepSeek相关+Al营销 | |
| 300418.SZ | 昆仑万维 | 454.30 | -2.08 | 3.23 | 140.71 | AI模型+AI应用(AI社交、AI音乐等) | |
| 000681.SZ | 视觉中国 | 169.40 | 1.37 | 1.65 | 123.65 | 102.67 | 字节概念+小米概念+端侧AI |
| 002862.SZ | 实丰文化 | 47.52 | 字节概念+端侧AI | ||||
| 301336.SZ | 趣睡科技 | 23.52 | 字节概念+端侧 AI | ||||
| 002292.SZ | 奥飞娱乐 | 144.32 | 1.04 | 1.86 | 138.77 | 77.59 | 端侧AI |
| 300459.SZ | 汤姆猫 | 200.40 | 端侧 AI | ||||
| 300494.SZ | 盛天网络 | 58.32 | -0.04 | 1.41 | 41.36 | AI应用(AI社交、AI音乐等) | |
| 603533.SH | 掌阅科技 | 93.22 | -0.15 | 0.70 | 133.17 | AI应用 | |
| 301110.SZ | 青木科技 | 64.77 | 1.44 | 1.94 | 45.14 | 33.39 | 电商代运营、AI电商 |
| 301171.SZ | 易点天下 | 154.68 | 2.76 | 3.38 | 56.12 | 45.76 | AI营销、营销出海 |
| 002400.SZ | 省广集团 | 142.78 | AI营销 | ||||
| 300058.SZ | 蓝色光标 | 229.94 | 3.41 | 5.39 | 67.42 | 42.65 | AI营销 |
| 603598.SH | 引力传媒 | 55.79 | 0.42 | 0.97 | 132.83 | 57.51 | AI营销 |
| 301052.SZ | 果麦文化 | 26.01 | AI应用(AI文字校对) | ||||
| 300805.SZ | 电声股份 | 45.99 | AI零售 | ||||
| 300654.SZ | 世纪天鸿 | 47.55 | 0.54 | 0.65 | 88.05 | 73.15 | AI教育 |
| 300785.SZ | 值得买 | 74.89 | 0.79 | 1.27 | 94.98 | 58.97 | AI电商 |
| 300688.SZ | 创业黑马 | 52.11 | -0.61 | 0.63 | 82.71 | 字节概念+AI企业服务 |
资料来源:同花顺 iFind、浙商证券研究所备注:数据日期为 2025 年 1 月 28 日收盘价,盈利预测(单位:亿元)及估值(单位:倍)统一使用同花顺 iFind 一致预期
风险提示:AI 技术迭代不及预期、AI 应用落地不及预期、政策不确定性、中美关系不确定性等的风险。
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除
行业报告资源群
- 进群福利:进群即领万份行业研究、管理方案及其他学
习资源,直接打包下载 - 每日分享:6份行研精选报告、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

微信扫码,长期有效
知识星球 行业与管理资源
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。

股票投资评级说明
以报告日后的 6 个月内,证券相对于沪深 300 指数的涨跌幅为标准,定义如下:
1.买入:相对于沪深 300 指数表现+ $20%$ 以上;
2.增持:相对于沪深 300 指数表现 $\vdash10%\sim+20%$ ;
3.中性:相对于沪深 300 指数表现 $-10%\sim+10%$ 之间波动;
4.减持:相对于沪深 300 指数表现- $10%$ 以下。
行业的投资评级:
以报告日后的 6 个月内,行业指数相对于沪深300 指数的涨跌幅为标准,定义如下:
1.看好:行业指数相对于沪深 300 指数表现 $+10%$ 以上;
2.中性:行业指数相对于沪深 300 指数表现- $-10%\sim+10%$ 以上;
3.看淡:行业指数相对于沪深 300 指数表现- $10%$ 以下。
我们在此提醒您,不同证券研究机构采用不同的评级术语及评级标准。我们采用的是相对评级体系,表示投资的相对比重。
建议:投资者买入或者卖出证券的决定取决于个人的实际情况,比如当前的持仓结构以及其他需要考虑的因素。投资者不应仅仅依靠投资评级来推断结论。
法律声明及风险提示
本报告由浙商证券股份有限公司(已具备中国证监会批复的证券投资咨询业务资格,经营许可证编号为:Z39833000)制作。本报告中的信息均来源于我们认为可靠的已公开资料,但浙商证券股份有限公司及其关联机构(以下统称“本公司”)对这些信息的真实性、准确性及完整性不作任何保证,也不保证所包含的信息和建议不发生任何变更。本公司没有将变更的信息和建议向报告所有接收者进行更新的义务。
本报告仅供本公司的客户作参考之用。本公司不会因接收人收到本报告而视其为本公司的当然客户。
本报告仅反映报告作者的出具日的观点和判断,在任何情况下,本报告中的信息或所表述的意见均不构成对任何人的投资建议,投资者应当对本报告中的信息和意见进行独立评估,并应同时考量各自的投资目的、财务状况和特定需求。对依据或者使用本报告所造成的一切后果,本公司及/或其关联人员均不承担任何法律责任。
本公司的交易人员以及其他专业人士可能会依据不同假设和标准、采用不同的分析方法而口头或书面发表与本报告意见及建议不一致的市场评论和/或交易观点。本公司没有将此意见及建议向报告所有接收者进行更新的义务。本公司的资产管理公司、自营部门以及其他投资业务部门可能独立做出与本报告中的意见或建议不一致的投资决策。
本报告版权均归本公司所有,未经本公司事先书面授权,任何机构或个人不得以任何形式复制、发布、传播本报告的全部或部分内容。经授权刊载、转发本报告或者摘要的,应当注明本报告发布人和发布日期,并提示使用本报告的风险。未经授权或未按要求刊载、转发本报告的,应当承担相应的法律责任。本公司将保留向其追究法律责任的权利。
浙商证券研究所
上海总部地址:杨高南路 729 号陆家嘴世纪金融广场 1 号楼 25 层
北京地址:北京市东城区朝阳门北大街 8 号富华大厦E 座 4 层
深圳地址:广东省深圳市福田区广电金融中心33 层
上海总部邮政编码:200127
上海总部电话:(8621)80108518
上海总部传真:(8621)80106010
浙商证券研究所:https://www.stocke.com.cn
文章作者 大模型
上次更新 2025-03-09