计算机_一文读懂DeepSeek_大模型行业专题报告
文章目录
计算机
报告日期:2025 年 02 月 03 日
一文读懂 DeepSeek大模型行业专题报告
投资要点
❑ DeepSeek 是坚持技术创新的中国大模型,中国模型出圈。
DeepSeek 成立于 2023 年 7 月,由知名量化资管巨头幻方量化创立,其掌门人梁文锋是 DeepSeek 的创始人,在暗涌专访中,梁文峰谈到:“这一波浪潮里,我们的出发点,就不是趁机赚一笔,而是走到技术的前沿,去推动整个生态发展。”根据 2 月 3 日 AI 产品榜数据,DeepSeek APP 上线 20 天日活超 2000 万。根据Appfigures 的数据显示(不包括中国的第三方应用商店),DeepSeek App 于 1 月 26日登上苹果 AppStore 全球下载榜榜首。根据 Sensor Tower 的研究,该应用在谷歌Play 商店美国区下载排行榜中位居榜首。Sensor Tower 数据显示,DeepSeek 在发布的前 18 天内累计下载量达 1600 万次。
DeepSeek 是搅动全球模型市场的一条鲶鱼,带来性能、价格、开源三重冲击。
1)性能比肩国际顶尖模型:DeepSeek R1 在数学、代码、自然语言推理等任务上的性能可比肩 OpenAI o1 模型正式版。在 AIME 2024 数学基准测试中,DeepSeek R1 得分率为 $79.8%$ ,OpenAI o1 的得分率为 $79.2%$ ;在 MATH-500 基准测试中,DeepSeek R1 得分率为 $97.3%$ ,OpenAI o1 的得分率为 $96.4%$ 。
2)低成本颠覆市场格局:DeepSeek V3 整个训练过程仅用了不到 280 万个 GPU小时,相比之下,Llama 3 405B 的训练时长是 3080 万 GPU 小时。DeepSeek-V3的训练成本仅为约 557.6 万美元,而 GPT-4 等模型的训练成本则高达数亿美元。DeepSeek API 服务定价远低于 OpenAI,以输出为例,每百万输出 tokens 16 元(约 2.2 美元),GPT - o1 每百万输出 tokens 60 美元。
3)践行开源理念:DeepSeek-V3 和推理模型 DeepSeek-R1 均开源,R1 同步开源了其模型权重,并允许用户利用模型输出,通过模型蒸馏等方式训练其他模型。Meta 首席科学家杨立昆(Yann Lecun)对 DeepSeek 评论“开源模型正在超越专有模型”。
ToB 端应用、AI 端侧应用将最受益于大模型的开源趋势、成本降低、迭代加速。
春节期间,华为云、微软、英伟达、AWS 等厂商均已上线 DeepSeek 的模型服务。大模型是应用软件的基础设施之一,随着基础设施的能力提升和成本下降,我们将看到应用侧的百花齐放。除了 DeepSeek,豆包、Qwen、Kimi 等近 2 月都在快速升级迭代,月活提升,成本降低。我们认为,首先现有的 B 端应用将最先迎来 AI Agent,B 端应用有成熟的数据、场景,例如客服、营销类场景会较快布局活跃有效的智能代理服务。其次,随着低参数模型性能翻倍,将更适用于追求低能耗的端侧 AI 创新产品。
❑ 相关标的
AI 应用:金山办公、科大讯飞、焦点科技、彩讯股份、泛微网络、鼎捷数智、汉得信息、致远互联等。港股:迈富时、金蝶国际、明源云等
AI 端侧:中科创达、虹软科技、中兴通讯、润欣科技、乐鑫科技、兆易创新、移远通信、恒玄科技;
行业评级: 看好(维持)
分析师:刘雯蜀
执业证书号:S1230523020002
[email protected]
分析师:郑毅
执业证书号:S1230524070002
[email protected]
分析师:叶光亮
执业证书号:S1230524080010
[email protected]
分析师:陶韫琦
执业证书号:S1230524090010
[email protected]
❑ 风险提示
相关报告
1 《DeepSeek 领衔,国产大模型竞争力加速迭代》 2025.02.032 《OpenAI 发布 Operator,AI智能体实现跨越式进步》2025.01.243 《机构持股比例拐点向上 算力、鸿蒙获得增持》 2025.01.24
产品研发不及预期、市场需求不及预期、大模型商业落地不及预期。
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除
行业报告资源群
- 进群福利:进群即领万份行业研究、管理方案及其他学
习资源,直接打包下载 - 每日分享:6份行研精选报告、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

微信扫码,长期有效
知识星球 行业与管理资源
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。

正文目录
1 版本有序落地,Deepseek-R1 性能比肩 OpenAI o1 正式版
2 DeepSeek产品技术特点..2.1 模型蒸馏增强小模型推理能力,视觉解耦统一多模态理解和生成 5
3 英伟达、微软等巨头携手 DeepSeek,推动 AI 落地革新 . 63.1 各科技巨头上线 DeepSeek,提供开发和推理服务 63.2 国产大模型推理能力提升,加速在应用端落地.
4 相关标的 ……….. 8
5 风险提示 8
图表目录
图 1:基于 DeepSeek-R1 输出蒸馏的小模型性能表现优异.
图 2:模型蒸馏技术架构… 5
图 3:基于 DeepSeek-R1 蒸馏的模型效果优于强化学习方法 5
图 4:基于 DeepSeek-R1 输出蒸馏的小模型性能表现优异. 6
图 5:秘塔 AI接入满血版 DeepSeek R1 推理模型… 8
图6:秘塔可通过数学建模预测“哪吒”电影票房.. 8
表 1: DeepSeek 模型各版本一览
1 版本有序落地,Deepseek-R1 性能比肩 OpenAI o1 正式版
模型厚积薄发,技术能力不断突破。DeepSeek(中文名为深度求索)成立于 2023年,是一家位于杭州的人工智能公司,为量化巨头幻方量化的子公司。公司自成立以来就不断研发迭代大模型,幻方目前拥有 1 万枚英伟达 A100 芯片,2023 年 4 月幻方宣布成立新组织,集中资源和力量,探索 AGI(通用人工智能)的本质,在一年多时间里进展迅速。
表1: DeepSeek 模型各版本一览
| 版本 | 推出时间 | 优点 | 缺点 | 竞品对标 |
| DeepSeek- 2025/1/20 R1 | 推理能力强:通过强化学习技术,推理能力比肩多模态任务支持有限:对多模态任务的支 OpenAl o1。 持仍不完善。 开源生态完善:遵循MITLicense,支持模型蒸应用场景受限:主要适用于科研、技术开 | OpenAl o1-mini | ||
| V3 | DeepSeek- 2024/12/26 | 馏。 性能卓越:6710亿参数,激活370亿参数,在 知识类任务和数学推理上表现优异。 生成速度快:生成吐字速度从20TPS提升至 60TPS. | 发和教育。 训练资源要求高:尽管成本降低,但训练Qwen2.5、 仍需大量GPU资源。 多模态能力不足:未专门针对多模态任务 | Llama 3.1、 Claude 3.5、 |
| V2.5 | 开源与本地部署:开源原生FP8权重,支持本优化。 地部署。 性能强劲:2360亿参数,每个token激活210 亿个参数,性能优于前代。 的近百分之一。 | 多模态能力有限:主要专注于语言任务。 | GPT-40 | |
| DeepSeek-2024年上 V2 | 开源商用:完全开源,免费商用。 性能强劲:2360亿参数,每个token激活210 亿个参数,性能优于前代。 成本低:训练成本大幅降低,仅为GPT-4-Turbo推理速度有待提升:相比后续版本,推理: | 速度较慢。 多模态能力有限:主要专注于语言任务。 | ||
| DeepSeek-2024 年1 V1 月 | 半年 | 的近百分之一。 开源商用:完全开源,免费商用。 强大的编码能力:预训练于2T标记,其中87%多模态能力有限:主要专注于编码和自然 1为代码,支持多种编程语言。 | 速度较慢。 语言处理。 长上下文支持:支持高达128K标记的上下文窗推理能力不足:无法处理复杂逻辑推理任 |
资料来源:彩云之南公众号,浙商证券研究所
DeepSeek 的产品体系不断丰富,每个模型都在不同的领域和任务中展现出了独特的优势和性能特点。随着时间的推移,DeepSeek 在不断优化模型性能的同时,也在推动着人工智能技术的发展和应用。
从版本迭代来看,公司历经一年已然迭代多个版本,目前模型能力可比肩 OpenAI o1-mini,从下载量来看,根据 AI 产品榜数据显示,DeepSeek 成为全球增速最快 AI 应用,上线 20 天日活突破 2000 万。
2 DeepSeek 产品技术特点
2.1 模型蒸馏增强小模型推理能力,视觉解耦统一多模态理解和生成
DeepSeek 采用模型蒸馏技术,极大提升模型推理能力。DeepSeek 官方技术文档显示,研究人员使用 DeepSeek 模型遴选了 80 万个样本,并且基于 DeepSeek-R1 模型的输出对阿里 Qwen 和 Meta 的 Llama 开源大模型进行微调。评测结果显示,基于 DeepSeek-R1 模型蒸馏的 32B 和 70B 模型在多项能力上可对标 OpenAI o1-mini 的效果。DeepSeek 研究结果表明,蒸馏方法可以显著增强小模型的推理能力。
图1: 基于 DeepSeek-R1 输出蒸馏的小模型性能表现优异
| AIME 2024 pass@1 | AIME 2024 cons@64 | MATH- 500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating | |
| GPT-40-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759.0 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717.0 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820.0 |
| QwQ-32B | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316.0 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954.0 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189.0 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481.0 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691.0 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205.0 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633.0 |
资料来源:DeepSeek 官网,浙商证券研究所
DeepSeek 采用蒸馏技术得到的模型效果优于同等条件下使用强化学习(RL)的效果。技术文档显示,DeepSeek-R1-Zero-Qwen-32B 模型是研究人员在 Qwen-32B-Base 模型基础上使用数学、代码、STEM 数据进行超过 10,000 步的 RL 训练得到,其各项测评结果均差于 DeepSeek-R1 模型通过蒸馏得到的 DeepSeek-R1-Distill-Qwen-32B 模型。考虑 RL 方法需要大量的计算资源,蒸馏方法在性能和性价比方面均呈现出显著的优势。
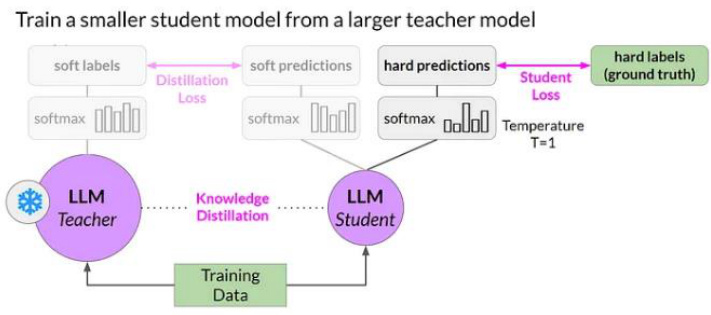
图2: 模型蒸馏技术架构
资料来源:Medium,浙商证券研究所
图3: 基于 DeepSeek-R1 蒸馏的模型效果优于强化学习方法
| Model | AIME2024 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | |
| pass@1 | cons@64 | ||||
| QwQ-32B-Preview | 50.0 | 60.0 | 90.6 | 54.5 | 41.9 |
| DeepSeek-R1-Zero-Qwen-32B | 47.0 | 60.0 | 91.6 | 55.0 | 40.2 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 |
资料来源:DeepSeek 官方技术文档,浙商证券研究所
Janus-Pro 是 DeepSeek 发布的一款统一多模态理解与生成的创新框架,通过解耦视觉编码的方式,极大提升了模型在不同任务中的适配性与性能。其中,Janus-Pro 的 SigLIP编码器专门负责理解图像,能提取图像的高层语义特征,并关注图像的整体含义和场景关系;而 VQ tokenizer 编码器,专门用于创作,将图像转换为离散的 token 序列,这样架构创新使得 Janus-Pro 在 7B 参数规模下,仅用 32 个节点、256 张 A100 和 14 天的时间就完成训练并取得出色性能表现。
图4: 基于 DeepSeek-R1 输出蒸馏的小模型性能表现优异
资料来源:和讯网,浙商证券研究所
3 英伟达、微软等巨头携手 DeepSeek,推动 AI 落地革新
3.1 各科技巨头上线 DeepSeek,提供开发和推理服务
国内外芯片厂商和云服务厂商迅速响应,纷纷接入 DeepSeek 模型,在海外,以英伟达、微软、亚马逊为首的科技巨头率先采用 DeepSeek,在国内,腾讯云和华为云已经上线DeepSeek 相关服务。
英伟达:2025 年 1 月 31 日,英伟达(NVIDIA)宣布,NVIDIA NIM 已支持使用 DeepSeek - R1。英伟达官网同日发文指出,为助力开发者安全试验这些功能并构建专属代理,DeepSeek - R1 模型已作为 NVIDIA NIM 微服务预览版上线。
微软:2025 年 1 月 30 日,微软宣布已将 DeepSeek - R1 正式纳入 Azure AIFoundry,成为该企业级 AI 服务平台的一部分。微软强调,DeepSeek - R1 模型已通过 “严格的红队测试与安全评估”,并历经 “模型行为自动化检测与广泛的安全审查” 以降低潜在风险。后续,微软还会持续评估该模型,或进行调整优化以提升其准确度和审查机制。
亚马逊:2025 年 1 月 31 日,亚马逊表示 DeepSeek - R1 模型已可在 AmazonWeb Services 上使用,这一合作彰显了 DeepSeek 模型在云计算场景中的价值,有助于亚马逊为用户提供更具创新性和高效性的 AI 技术,提升用户在电商、数据分析等领域的体验,推动业务发展。
腾讯云:2025 年 2 月 2 日,腾讯云宣布将 DeepSeek-R1 大模型一键部署至其HAI 平台,开发者仅需 3 分钟即可完成接入。这一举措降低了开发者使用DeepSeek-R1 模型的门槛,使得更多基于该模型的创新应用能够快速开发和部署。借助腾讯云 HAI 平台的强大算力和丰富的生态资源,DeepSeek-R1 模型有望在内容创作、智能客服、数据分析等多个领域发挥更大的作用,为腾讯云的用户提供更加智能化的服务。
华为云:2025 年 2 月 1 日,硅基流动和华为云团队联合首发并上线基于华为云昇腾云服务的 DeepSeekR1/V3 推理服务。基于华为云昇腾云服务强大的算力支持,此次合作推出的推理服务能够充分发挥 DeepSeekR1/V3 模型的优势,为科研、医疗、工业制造等多个行业提供高效、精准的 AI 推理能力。
3.2 国产大模型推理能力提升,加速在应用端落地
DeepSeek 最新版模型展现出来的优异能力,表明国内大模型推理能力提升到一个新的阶段,大模型在各领域的应用有望加速加速落地。我们认为,DeepSeek 给 AI 研究和企业端应用都将带来革新。
在 AI 研究与学术领域:DeepSeek AI 推动大规模语言模型的进化,为未来的 AI 研究提供了新方向;提升 AI 可解释性,使开发者更容易理解模型的决策逻辑;加速自然语言处理(NLP)任务的突破,如文本生成、情感分析、机器翻译等。
在企业应用端,我们认为:首先现有的 B 端应用将最先迎来 AI Agent,B 端应用有成熟的数据、场景,例如客服、营销类场景会较快布局活跃有效的智能代理服务。其次,随着低参数模型性能翻倍,将更适用于追求低能耗的端侧 AI 创新产品。
以秘塔 AI 搜索为例,在融合 DeepSeek-R1 后,实现了 “国产最强推理 $^+$ 全网实时搜索 $^+$ 高质量知识库” 的结合,在多个方面利用 DeepSeek 技术提升用户体验:
处理复杂问题:借助 DeepSeek-R1 强大的复杂推理能力,结合自身的联网检索和海量知识库 / 论文数据,处理复杂查询。在预测《哪吒 2》票房成绩时,能结合海量搜索材料,考虑多个变量因素,确定基准数据和关键影响因素,构建数学模型进行预测 ,还能实时联网获取最新票房及各方预测结果。
提升专业知识查询能力:在查询专业知识时,如 OpenAI 模型进展相关问题,秘塔 AI 搜索可利用 DeepSeek 的推理能力深入分析资料。它能准确找出 2024 年以来 OpenAI 发布的模型及其技术突破,并总结出推理能力、多模态交互、效率优化、视频生成技术等四大技术突破方向,还提及市场竞争态势等信息,且提供具体引用细节。
优化搜索结果质量:对接 DeepSeek-R1 的推理能力后,秘塔 AI 搜索可以更准确地理解用户查询意图,处理多条件筛选、语义模糊等复杂查询,返回更快速、相关、精准的信息结果。同时,通过分析信息来源和内容逻辑性,过滤谣言等虚假信息,增强搜索结果的真实性和可靠性。
助力深度知识挖掘:让 DeepSeek-R1 拥有 AI 联网搜索及背后的高质量索引库,能够实时查询最新资料,全网搜罗、分析各种论文并形成思维导图汇总,满足用户从查询一项研究 / 技术的最新进展到纵观一个学科技术发展历程等多样需求。
图5: 秘塔 AI 接入满血版 DeepSeek R1 推理模型
资料来源:秘塔 AI 搜索官网,浙商证券研究所

图6: 秘塔可通过数学建模预测“哪吒”电影票房
资料来源:秘塔 AI 搜索官网,浙商证券研究所
4 相关标的
AI 应用:金山办公、科大讯飞、焦点科技、彩讯股份、泛微网络、鼎捷数智、汉得信息、致远互联等。港股:迈富时、金蝶国际、明源云等
AI 端侧:中科创达、虹软科技、中兴通讯、润欣科技、乐鑫科技、兆易创新、移远通信、恒玄科技;
5 风险提示
产品研发不及预期:如果 DeepSeek 大模型或者大模型应用研发不及预期,可能影响对算力的需求和应用的落地
市场需求不及预期:如果市场需求不足,则影响对算力需求及 AI 应用推广。
大模型商业落地不及预期:如果大模型未能找到足够多的商业落地场景,则可能影响大模型的盈利并影响产业界对大模型乃至算力的投资。
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除
行业报告资源群
- 进群福利:进群即领万份行业研究、管理方案及其他学
习资源,直接打包下载 - 每日分享:6份行研精选报告、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

微信扫码,长期有效
知识星球 行业与管理资源
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。

股票投资评级说明
以报告日后的 6 个月内,证券相对于沪深 300 指数的涨跌幅为标准,定义如下:
1.买 入 :相对于沪深 300 指数表现 $+20%$ 以上;
2.增 持 :相对于沪深 300 指数表现 $+10%\sim+20%$ ;
3.中 性 :相对于沪深 300 指数表现 $-10%\sim+10%$ 之间波动;
4.减 持 :相对于沪深 300 指数表现 $-10%$ 以下。
行业的投资评级:
以报告日后的 6 个月内,行业指数相对于沪深 300 指数的涨跌幅为标准,定义如下:
1.看 好 :行业指数相对于沪深 300 指数表现 $+10%$ 以上;
2.中 性 :行业指数相对于沪深 300 指数表现 $-:10%\sim:+:10%$ 以上;
3.看 淡 :行业指数相对于沪深 300 指数表现 $-10%$ 以下。
我们在此提醒您,不同证券研究机构采用不同的评级术语及评级标准。我们采用的是相对评级体系,表示投资的相对比重。
建议:投资者买入或者卖出证券的决定取决于个人的实际情况,比如当前的持仓结构以及其他需要考虑的因素。投资者不应仅仅依靠投资评级来推断结论。
法律声明及风险提示
本报告由浙商证券股份有限公司(已具备中国证监会批复的证券投资咨询业务资格,经营许可证编号为:Z39833000)制作。本报告中的信息均来源于我们认为可靠的已公开资料,但浙商证券股份有限公司及其关联机构(以下统称“本公司”)对这些信息的真实性、准确性及完整性不作任何保证,也不保证所包含的信息和建议不发生任何变更。本公司没有将变更的信息和建议向报告所有接收者进行更新的义务。
本报告仅供本公司的客户作参考之用。本公司不会因接收人收到本报告而视其为本公司的当然客户。
本报告仅反映报告作者的出具日的观点和判断,在任何情况下,本报告中的信息或所表述的意见均不构成对任何人的投资建议,投资者应当对本报告中的信息和意见进行独立评估,并应同时考量各自的投资目的、财务状况和特定需求。对依据或者使用本报告所造成的一切后果,本公司及/或其关联人员均不承担任何法律责任。
本公司的交易人员以及其他专业人士可能会依据不同假设和标准、采用不同的分析方法而口头或书面发表与本报告意见及建议不一致的市场评论和/或交易观点。本公司没有将此意见及建议向报告所有接收者进行更新的义务。本公司的资产管理公司、自营部门以及其他投资业务部门可能独立做出与本报告中的意见或建议不一致的投资决策。
本报告版权均归本公司所有,未经本公司事先书面授权,任何机构或个人不得以任何形式复制、发布、传播本报告的全部或部分内容。经授权刊载、转发本报告或者摘要的,应当注明本报告发布人和发布日期,并提示使用本报告的风险。未经授权或未按要求刊载、转发本报告的,应当承担相应的法律责任。本公司将保留向其追究法律责任的权利。
浙商证券研究所
上海总部地址:杨高南路 729 号陆家嘴世纪金融广场 1 号楼 25 层
北京地址:北京市东城区朝阳门北大街 8 号富华大厦 E 座 4 层
深圳地址:广东省深圳市福田区广电金融中心 33 层
上海总部邮政编码:200127
上海总部电话:(8621) 80108518
上海总部传真:(8621) 80106010
浙商证券研究所:https://www.stocke.com.cn
文章作者 大模型
上次更新 2025-03-09