计算机_DeepSeek_R1深度解析及算力影响几何
文章目录
证券研究报告行业动态研究
DeepSeek R1深度解析及算力影响几何
分析师:于芳博[email protected]编号:S1440522030001
分析师:庞佳军[email protected] 编号:S1440524110001
分析师:辛侠平[email protected]编号:S1440524070006
研究助理:孟龙飞
[email protected]
010-56135277
发布日期:2025年2月3日
报告由中信建投证券股份有限公司在中华人民共和国(仅为本报告目的,不包括香港、澳门、台湾)提供。在遵守适用的法律法规情况下,本报告亦可能由中信建投(国际)证券有限公司在香港提供。同时请务读正文之后的免责条款和声明。
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除。
行业报告资源群

- 进群福利:进群即领万份行业研究、管理方案及其他
学习资源,直接打包下载 - 每日分享: $6+$ 份行研精选、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

知识星球 行业与管理资源

微信扫码 行研无忧
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。
摘要
核心观点: Deepseek发布深度推理能力模型。R1-Zero采用纯粹的强化学习训练,证明了大语言模型仅通过强化学习也可以有强大的推理能力,DeepSeek-R1经历微调和强化学习取得了与OpenAI-o1-1217相媲美甚至超越的成绩。DeepSeek R1训练和推理算力需求较低,主要原因是DeepSeek R1实现算法、框架和硬件的优化协同。过去的预训练侧的scaling law正逐步迈向更广阔的空间,在深度推理的阶段,模型的未来算力需求依然会呈现爆发式上涨,充足的算力需求对于人工智能模型的性能进步依然至关重要。
Deepseek发布深度推理能力模型,性能和成本方面表现出色。Deepseek发布两款具备深度推理能力的大模型R1-Zero和DeepSeek-R1。R1-Zero采用纯粹的强化学习训练,模型效果逼近OpenAI o1模型,证明了大语言模型仅通过RL,无SFT,大模型也可以有强大的推理能力。但是R1-Zero也存在可读性差和语言混合的问题,在进一步的优化过程中,DeepSeek-V3-Base经历两次微调和两次强化学习得到R1模型,主要包括冷启动阶段、面向推理的强化学习、拒绝采样与监督微调、面向全场景的强化学习四个阶段,R1在推理任务上表现出色,特别是在AIME 2024、MATH-500和Codeforces等任务上,取得了与OpenAI-o1-1217相媲美甚至超越的成绩。
国产模型迈向深度推理,策略创新百花齐放。在Deepseek R1-Zero模型中,采用的强化学习策略是GRPO策略,取消价值网络,采用分组相对奖励,专门优化数学推理任务,减少计算资源消耗; KIMI 1.5采用Partial rollout的强化学习策略,同时采用模型合并、最短拒绝采样、DPO 和long2short RL策略实现短链推理;Qwen2.5扩大监督微调数据范围以及两阶段强化学习,增强模型处理能力。
DeepSeek R1通过较少算力实现高性能模型表现,主要原因是DeepSeek R1实现算法、框架和硬件的优化协同。 DeepSeek R1在诸多维度上进行了大量优化,算法层面引入专家混合模型、多头隐式注意力、多token预测,框架层面实现FP8混合精度训练,硬件层面采用优化的流水线并行策略,同时高效配置专家分发与跨节点通信,实现最优效率配置。当前阶段大模型行业正处于从传统的生成式模型向深度推理模型过渡阶段,算力的整体需求也从预训练阶段逐步过渡向后训练和推理侧,通过大量协同优化,DeepSeek R1在特定发展阶段通过较少算力实现高性能模型表现,算力行业的长期增长逻辑并未受到挑战。过去的预训练侧的scaling law正逐步迈向更广阔的空间,在深度推理的阶段,模型的未来算力需求依然会呈现爆发式上涨,充足的算力需求对于人工智能模型的性能进步依然至关重要。
| 第一章 | 国内模型深度推理发展现状 4 |
| 第二章 | 低算力需求缘起及长期算力观点 20 |
| 第三章 | |
| 相关问答案例 27 | |
| 第四章 | 风险提示 33 |
R1-Zero验证了大模型仅通过RL就可实现强大推理能力
Deepseek发布两款具备深度推理能力的大模型R1-Zero和DeepSeek-R1。
R1-Zero的训练,证明了仅通过RL,无SFT,大模型也可以有强大的推理能力。在AIME 2024上,R1-Zero的pass@1指标从15.6%提升至 $71.0%$ ,经过投票策略(majority voting)后更是提升到了 $86.7%$ ,与OpenAI-o1-0912相当。
架构思路:没有任何SFT数据的情况下,通过纯粹的强化学习。
算法应用:直接在DeepSeek-V3-Base模型上应用GRPO算法进行强化学习训练。
奖励机制:使用基于规则的奖励机制,包括准确性奖励和格式奖励,来指导模型的学习。
训练模板:采用了简洁的训练模板,要求模型首先输出推理过程(置于标签内),然后给出最终答案(置于标签内)
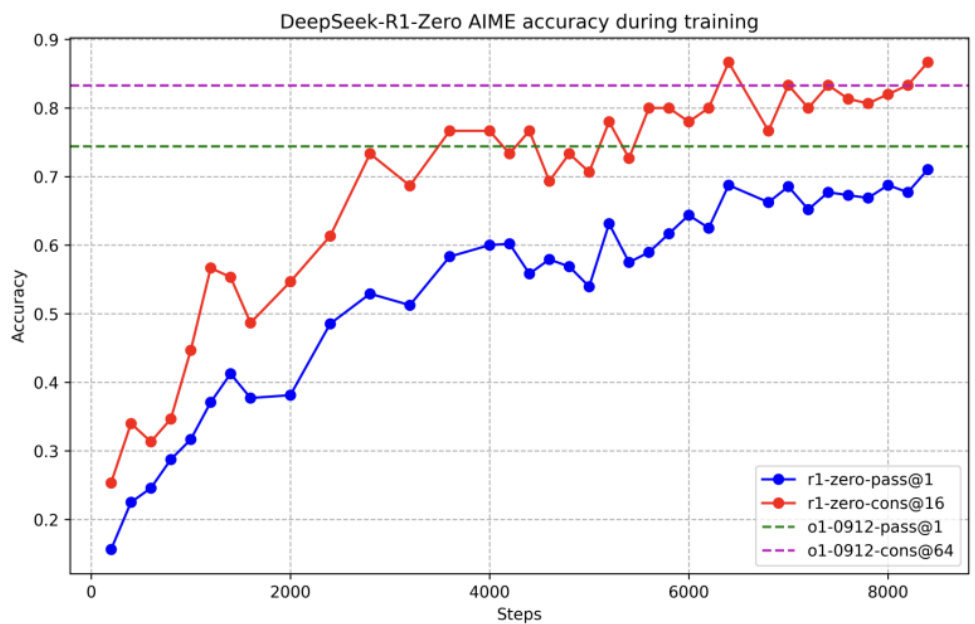
图:R1-Zero在AIME 2024基准测试上的性能测试
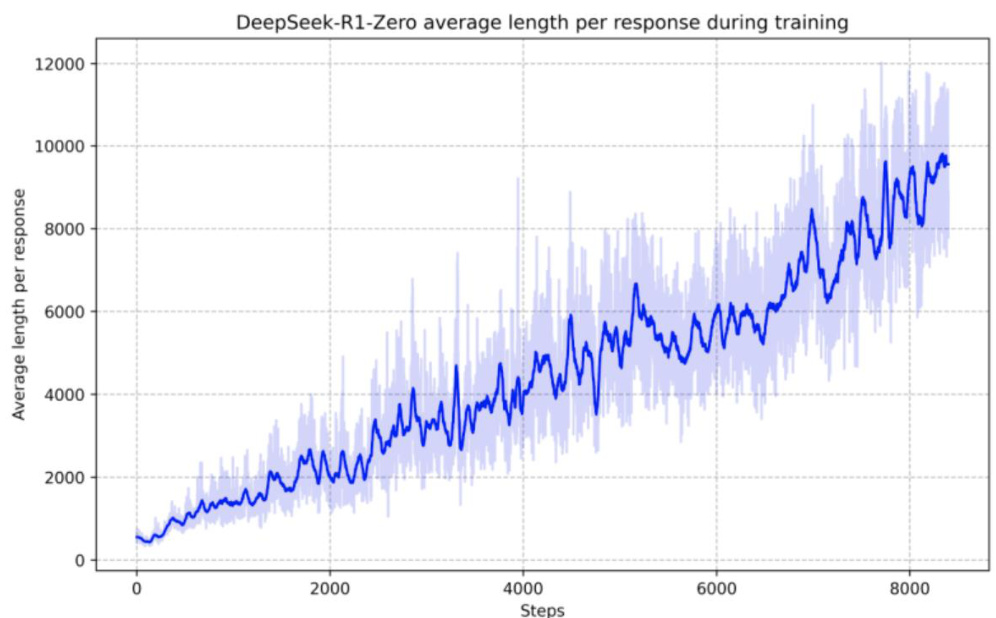
图:强化学习过程中的scaling law
DeepSeek-R1:长CoT数据微调基础上应用强化学习
为了解决R1-Zero可读性差和语言混合的问题,构建了R1。
架构思路:在DeepSeek-V3-Base模型的基础上,经历两次微调和两次强化学习得到R1模型。
Step 1.冷启动阶段:使用数千个高质量的长Cot人工标注样本对DeepSeek-V3-Base模型进行微调,作为强化学习的初始模型。
Step 2.面向推理的强化学习:在冷启动阶段之后,R1采用了与R1-Zero类似的强化学习训练,但针对推理任务进行了特别优化。为了解决训练过程中可能出现的语言混杂问题,R1引入了语言一致性奖励,该奖励根据CoT中目标语言单词的比例来计算。
Step 3.拒绝采样与监督微调:当面向推理的强化学习收敛后,R1利用训练好的RL模型进行拒绝采样,生成新的SFT数据。
Step 4.面向全场景的强化学习:在收集了新的SFT数据后,R1会进行第二阶段的强化学习训练,这一次,训练的目标不再局限于推理任务,而是涵盖了所有类型的任务。此外,R1采用了不同的奖励信号和提示分布,针对不同的任务类型进行了优化。
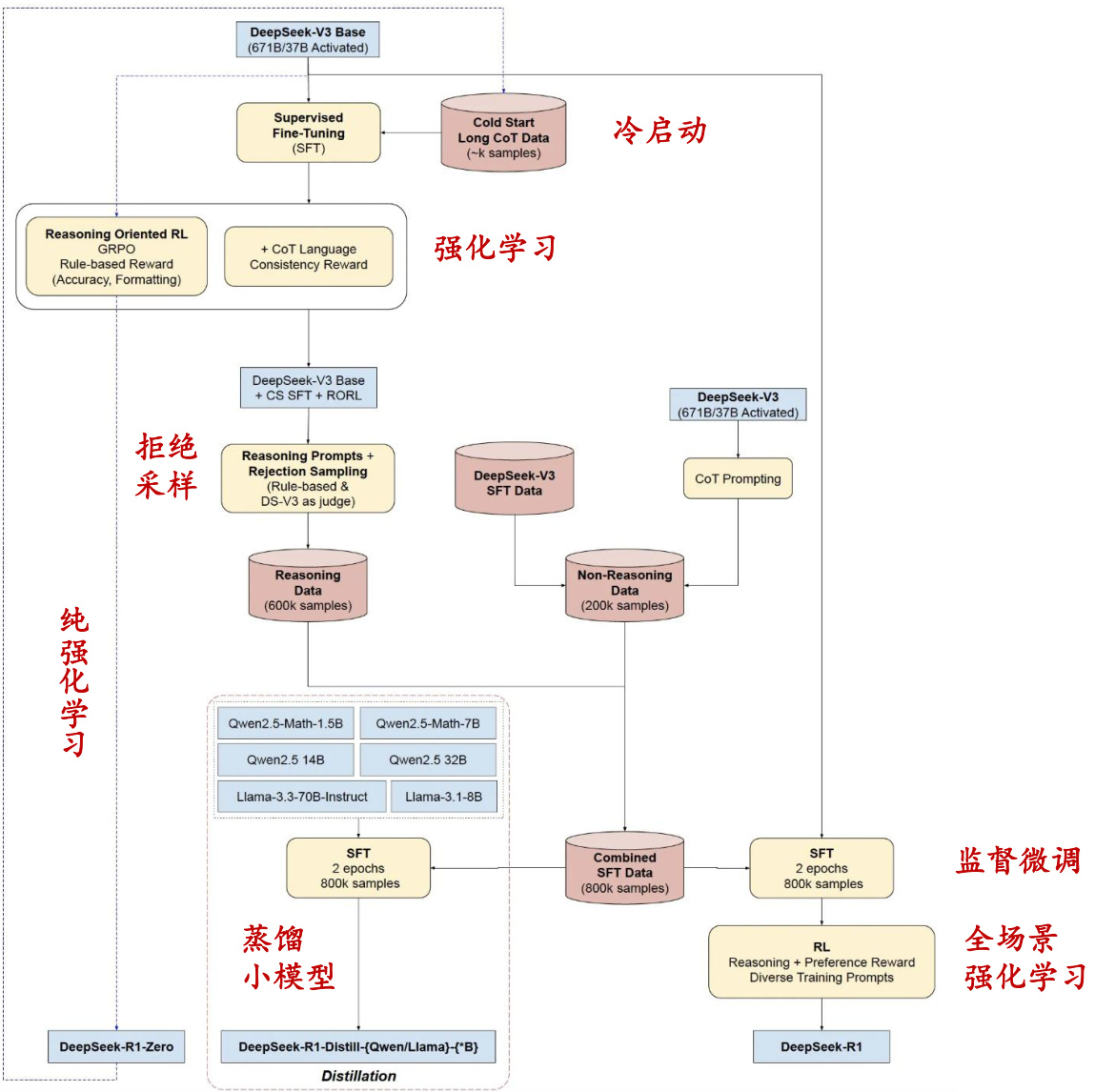
图:DeepSeek-R1训练过程
R1模型推理任务表现出色
R1在推理任务上表现出色,特别是在AIME 2024(美国数学邀请赛)、MATH-500(数学竞赛题)和Codeforces(编程竞赛)等任务上,取得了与OpenAI-o1-1217相媲美甚至超越的成绩。在MMLU( $90.8%$ )、MMLU-Pro(84. $0%$ )和GPQADiamond( $71.5%$ )等知识密集型任务基准测试中,性能显著超越了DeepSeek-V3模型。在针对长上下文理解能力的FRAMES数据集上,R1的准确率达到了 $82.5%$ ,优于DeepSeek-V3模型。在开放式问答任务AlpacaEval 2.0和Arena-Hard基准测试中,R1分别取得了 $87.6%$ 的LC-winrate和92. $3%$ 的GPT-4-1106评分,展现了其在开放式问答领域的强大能力。
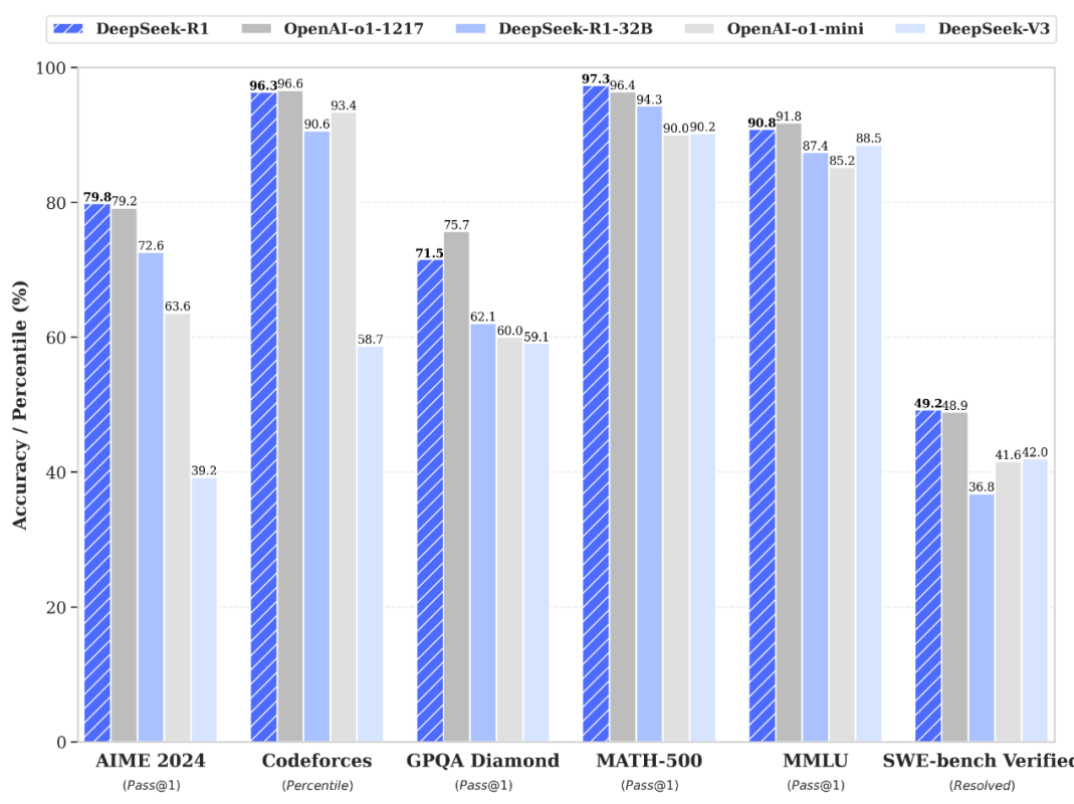
图表:R1在数学、代码、自然语言推理等任务的性能测试结果
| Benchmark (Metric) | Claude-3.5- Sonnet-1022 | GPT-4oDeepSeek 0513 | V3 | OpenAIOpenAI|DeepSeek 01-mini o1-1217 | R1 | ||
| Architecture #Activated Params | MoE | MoE | |||||
| #Total Params | 37B 671B | - | 37B | ||||
| English | 671B | ||||||
| MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 | |
| MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | 92.9 | ||
| MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | 84.0 | ||
| DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 | |
| IF-Eval (Prompt Strict) | 86.5 | 84.3 | 86.1 | 84.8 | 83.3 | ||
| GPQA Diamond (Pass@1) | 65.0 28.4 | 49.9 38.2 | 59.1 24.9 | 60.0 7.0 | 75.7 47.0 | 71.5 | |
| SimpleQA (Correct) FRAMES (Acc) | 72.5 | 80.5 | 73.3 | 76.9 | 30.1 | ||
| 52.0 | 51.1 | 70.0 | 57.8 | 82.5 | |||
| AlpacaEval2.0 (LC-winrate) ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | 87.6 | ||
| 92.3 | |||||||
| Code | LiveCodeBench (Pass@1-COT) Codeforces (Percentile) | 38.9 20.3 | 32.9 | 36.2 | 53.8 | 63.4 | 65.9 |
| 717 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | ||
| Codeforces (Rating) | 759 | 1134 | 1820 | 2061 | 2029 | ||
| SWE Verified (Resolved) | 50.8 45.3 | 38.8 | 42.0 49.6 | 41.6 | 48.9 | 49.2 | |
| Aider-Polyglot (Acc.) | 16.0 | 32.9 | 61.7 | 53.3 | |||
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | 78.8 | ||
| Chinese C-Eval (EM) | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 |
| 76.7 | 76.0 | 86.5 | 68.9 | 91.8 | |||
| C-SimpleQA (Correct) | 55.4 | 58.7 | 68.0 | 40.3 | 63.7 | ||
资料来源:DeepSeek-Rl:Incentivizing Reasoning CapabilityinLLMsviaReinforcementLearning,中信建投
通过蒸馏实现推理能力迁移
DeepSeek团队进一步探索了将R1的推理能力蒸馏到更小的模型中的可能性。他们使用R1生成的800K数据,对Qwen和Llama系列的多个小模型(1.5B、7B、8B、14B、32B、70B)进行了微调。经过R1蒸馏的小模型,在推理能力上得到了显著提升,甚至超越了在这些小模型上直接进行强化学习的效果。
推理成本来看,R1模型价格只有OpenAI o1模型的几十分之一。训练成本来看,DeepSeek-V3在一个配备2048个NVIDIAH800 GPU的集群上进行训练,预训练阶段在不到两个月内完成,并消耗了2664K GPU小时,总训练成本为557.6万美元。
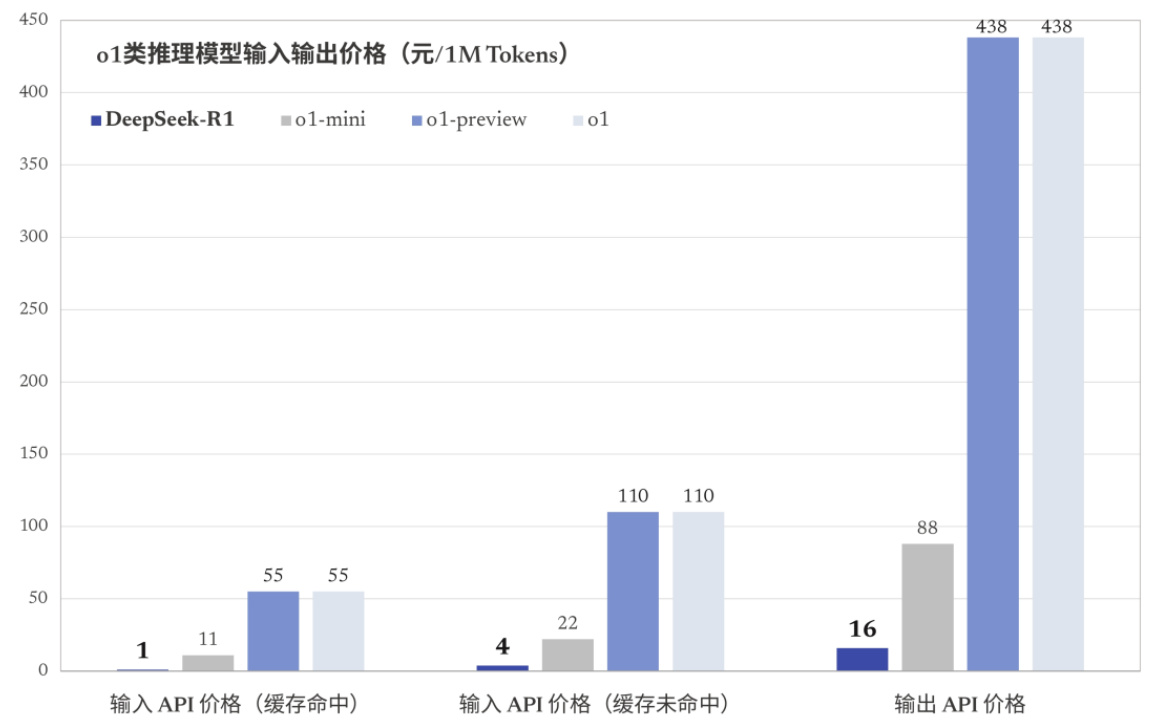
图:o1类推理模型输入输出价格(元/1M Tokens)
图:蒸馏模型表现
| AIME 2024 pass@1 | AIME 2024 cons@64 | MATH- 500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench CodeForces pass@1 | rating | |
| GPT-40-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759.0 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717.0 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820.0 |
| QwQ-32B | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316.0 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954.0 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189.0 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481.0 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691.0 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205.0 |
| DeepSeek-R1-Distill-Llama-7OB | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633.0 |
Deepseek强化学习策略GRPO
epSeek中强化学习的核心策略是GRPO策略,GRPO是PPO的改进版本,专门优化数学推理任务,减少计算资源消耗。
GRPO关键改进:
取消价值网络,降低计算资源。PPO需要一个额外的价值网络来估计优势,但GRPO直接用样本组的平均奖励作为基线。这样,GRPO不需要额外训练价值网络,减少GPU计算成本。采用分组相对奖励,GRPO用多个样本的奖励来计算相对优势,而不是用价值网络估计优势。

图:GRPO策略和PPO策略中的价值网络
PPO中的价值估算:
GRPO中的价值估算:

图:GRPO策略和PPO策略的比较
| 对比项 | PPO (Proximal Policy Optimization) | GRPO (Group Relative Policy Optimization) |
| 是否有Critic(值函 数) | 有(需要单独的Critic网络) | ×没有 |
| 是否有价值网络 (ValueNetwork) | 有 (用于计算V(s)) | ×没有 |
| 如何计算Advantage | 采用GAE(GeneralizedAdvantage Estimation): At = rt + V(st+1) - V(st) | 直接用一组样本的相对奖励计 算Advantage |
| 计算复杂度 | 高(需要额外训练Critic 网络) | 低(只需要Reward Model) |
| 适用任务 | 适用于一般RL任务,如RLHF | 适用于数学推理任务 |
KIMI 1.5:最好的Short-CoT模型,出色的推理创新
2025年1月20日,kimi1.5版本模型发布,这是继2024年11月发布 k0-math 数学模型,12月发布 k1 视觉思考模型之后,Kimi连续第三个月带来 k 系列强化学习模型的重磅升级。
从基准测试成绩看,k1.5 多模态思考模型实现了 SOTA (state-of-the-art)级别的多模态推理和通用推理能力。
在 short-CoT 模式下,Kimi $k1.5$ 的数学、代码、视觉多模态和通用能力,大幅超越了全球范围内短思考 SOTA 模型 GPT-4o和 Claude 3.5 Sonnet 的水平,领先达到 $550%$ 。
在 long-CoT 模式下,Kimi k1.5 的数学、代码、多模态推理能力,也达到长思考 SOTA 模型 OpenAI o1 正式版的水平。这应该是全球范围内,OpenAI 之外的公司首次实现 o1 正式版的多模态推理性能。
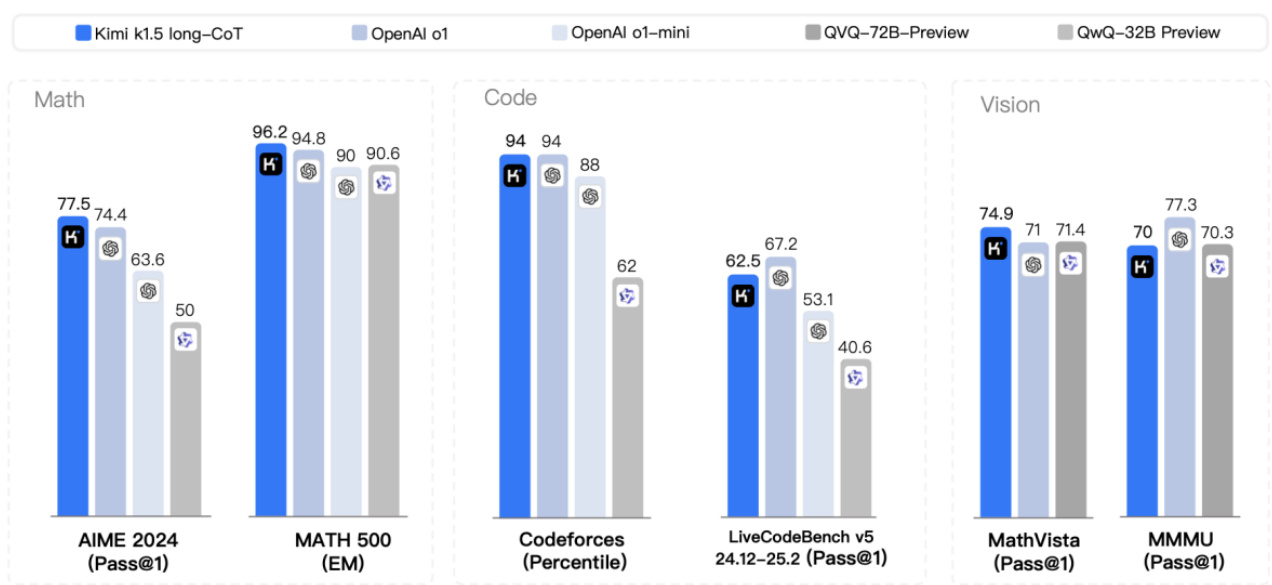
图:Kimi1.5 long-CoT模型能力
资料来源:Kimikl.5:Scaling Reinforcement Learning with LLMs,中信建投
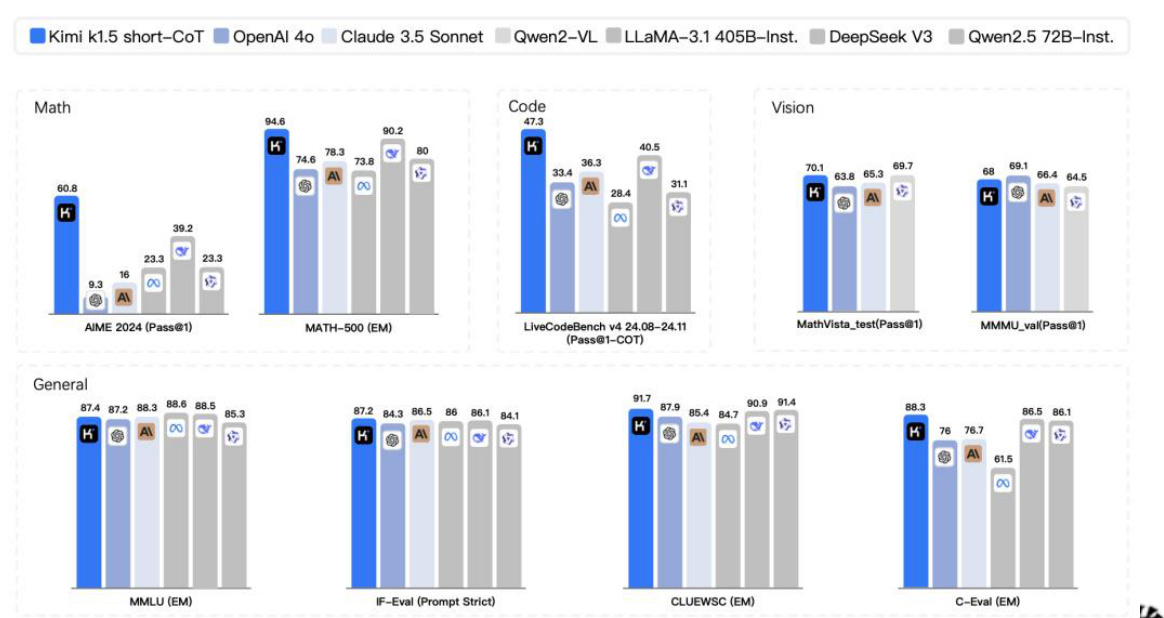
图:Kimi1.5 short-CoT模型能力
KIMI 1.5:四大创新
Kimi k1.5 通过几个关键技术实现了强化学习(RL)在大型语言模型(LLMs)中的有效扩展和性能提升:
1)长上下文扩展:通过将RL的上下文窗口扩展到 $128\upkappa$ ,Kimi k1.5能够处理更长的文本序列,从而在多个任务上提升性能。在推理过程中,也保证了更长的思维链,可以进行更多步骤,更深入的思考。
2)改进的策略优化:采用在线镜像下降法的变体进行策略优化,并结合有效的采样策略、长度惩罚和数据配方优化,进一步提升了模型的训练效果,进一步节约算力和思考时间。
3)简化的RL框架:通过长上下文扩展和改进的策略优化,Kimi k1.5建立了一个简化的RL学习框架,使得模型能够在不依赖复杂技术的情况下实现强大的性能,优化算力。
4)多模态处理能力:Kimi k1.5能够同时处理文本和视觉数据,展现了在多模态数据上进行联合推理的能力。(对比Deepseek R1仅为纯语言模型)
图:Kimi1.5 出色的多模态能力
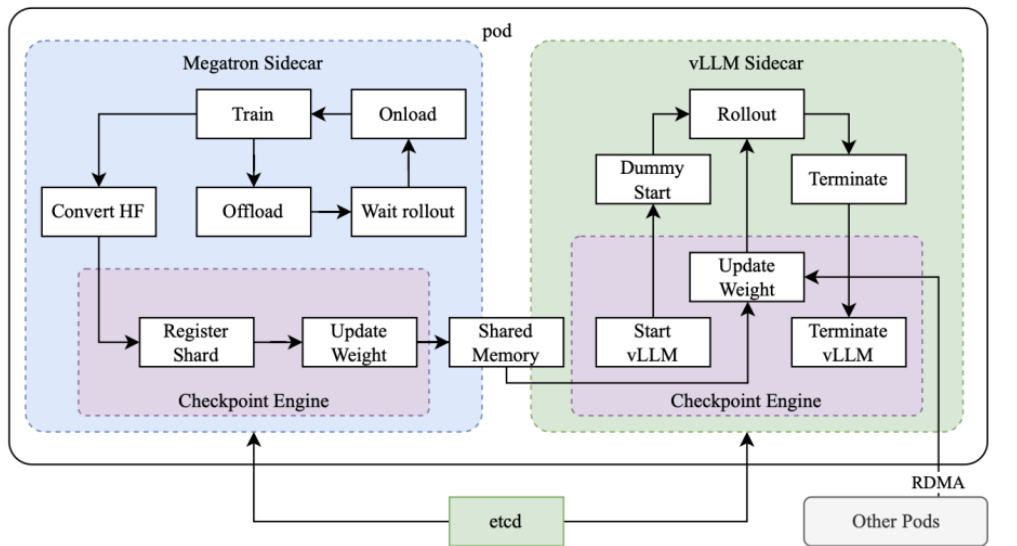
图:Kimi1.5 算力优化方案,合理分配训练和推理的算力资源
资料来源:Kimi kl.5:Scaling Reinforcement Learning withLLMs,中信建投
KIMI 1.5:Partial rollout的RL框架创新
mi k1.5的推理框架分为核心几块:1)Rollout 模块:理解为推理过程中的试错者和推演者,不断推演不同可能性,从而找到最优解。以想象成一群工人在生产线上进行实际的操作记录下每一步的结果。根据当前的模型权重生成一系列的决策路径。
2)主管(Master)模块:理解为指挥中心。负责协调和管理整个训练过程,接收来自Rollout模块的轨迹数据,评估模型的表现,并向rainer Workers发送训练数据。主管还负责管理Replay Buffer(缓冲区),确保推理数据的高效利用。
3)训练模块:负责根据Rollout模块提供的数据来训练模型。使用策略模型(Policy Model)和参考模型(Reference Model)来计算梯度更新(gradient update),从而优化模型的性能。模型和缓冲区:前者是 “裁判”,负责评估模型表现并给出奖励信号。后者是“记忆库”,用于存储Rollout生成的轨迹数据。
Partial Rollout创新:在Rollout模块的推理中,不需要每次都从头开始,可以从缓冲区中读取之前的轨迹后继续推理。类似于1)下棋中,每次只需要思考最关键的步骤,而不用思考前面简单的步骤。2)设计方案时,可以复用地基的设计,只考虑顶层的不同设计方案。
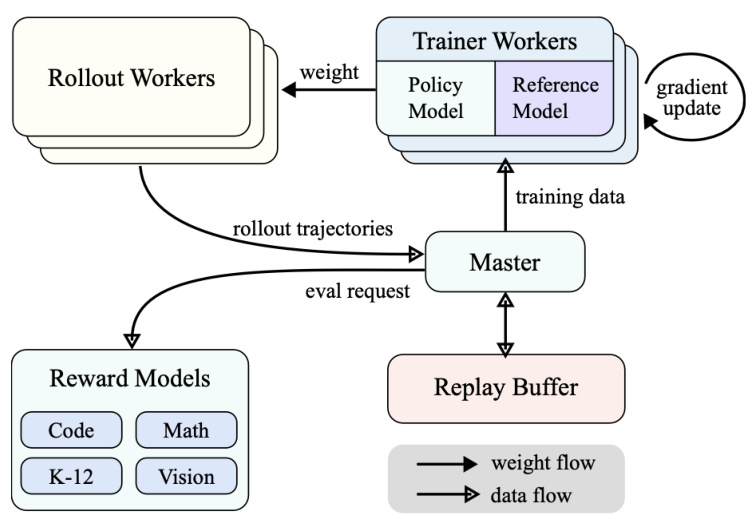
图:Kimi1.5 的模型架构创新
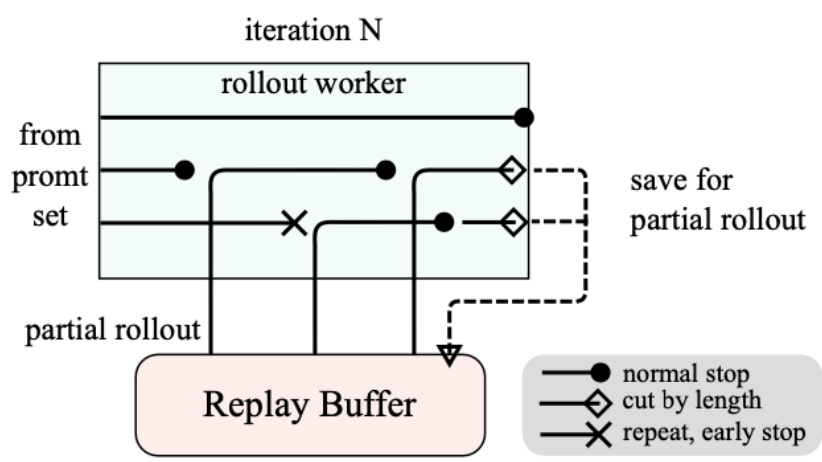
图:Kimi1.5 创新性的Partial Rollout 方案
(a) System overview
KIMI 1.5:Long2short技术保证了最强的短推理模型
尽管长链推理模型能够实现强大的性能,但消耗tokens更多。通过将长链推理模型的思维先验转移到短链推理模型中,从而在有限算力下提高性能。kimi1.5提出了几种解决长链到短链(long2short)问题的方法,包括模型合并、最短拒绝采样、DPO 和long2short RL。
1)模型合并:通过平均长链推理模型和短链推理模型的权重,合并两个模型,提高令牌效率。2)最短拒绝采样:对同一个问题进行多次采样,选择最短的正确响应进行微调。3)DPO:利用长链推理模型生成的多个响应样本,构建正负样本对进行训练。4)long2short RL:在标准 RL 训练后,选择一个性能和效率平衡的模型,应用长度惩罚并减少最大展开长度,进一步优化短链推理模型。
long2short RL:在标准的RL后,再加一个长度RL,从而选出所有正确答案中,思考步数最短的,进而优化算力。鼓励在相同在强化学习中,模型会生成多个响应(responses),每个响应都有一个长度。为了鼓励模型生成更短的响应,同时惩罚过长的响应,引入了长度奖励机制。这个机制通过计算每个响应的长度奖励,将其添加到原始奖励中,从而影响模型的训练过程。
图:Kimi1.5 Long2Short RL 引入的长度惩罚机制
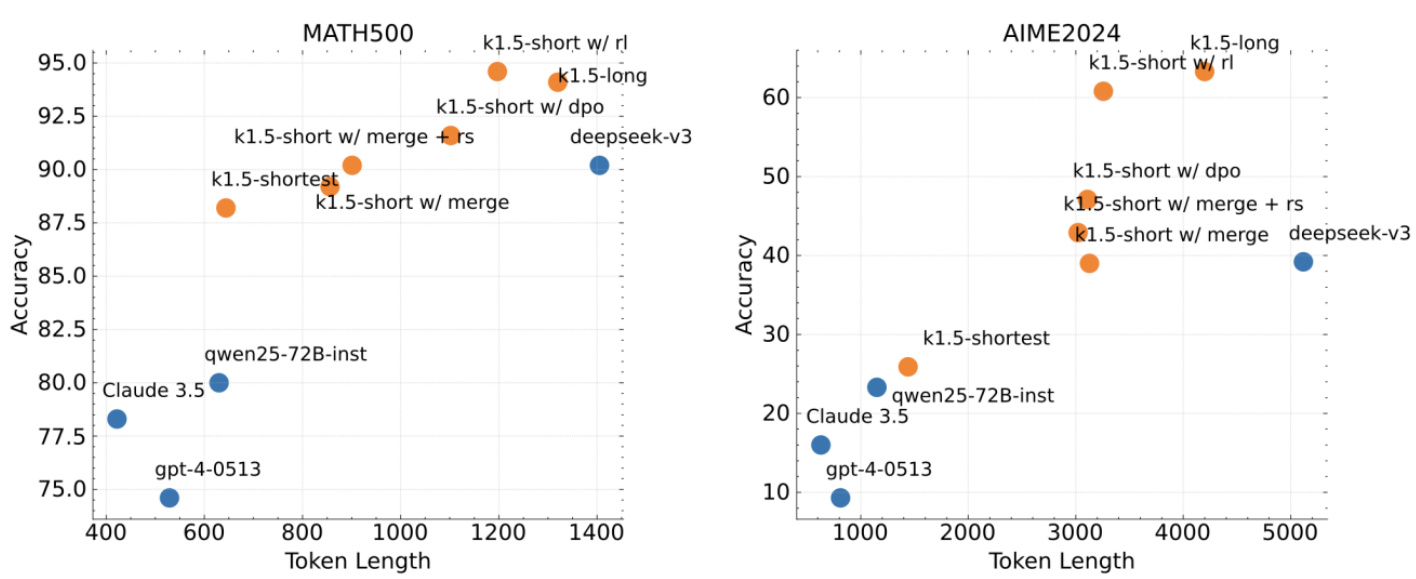
图:Kimi1.5 short-CoT 性能出色(特别是RL方法)
$$ \operatorname{len_reward}(\mathrm{i})=\left{\operatorname*{min}{\mathbf{\alpha}}(0,\lambda)&{\mathrm{If}}r(x,y{i},y^{*})=1\right. $$
阿里千问发布Qwen2.5系列模型,性能水平顶尖
2024年09月19日,阿里发布Qwen2.5系列,包括0.5B,1.5B,3B,7B,14B,32B以及72B,以及专门针对编程的 $\mathsf{Q w e n2.5^{-}}$ Coder和数学的 $\mathtt{Q w e n2.5{-}M a t h}$ 模型。Qwen2.5所有系列模型都在18Ttokens的数据集上进行了预训练,相较于Qwen2,Qwen2.5获得了更多的知识(MMLU: $85+$ ),并在编程和数学方面有了大幅提升。
用于编程的Qwen2.5-Coder和用于数学的 $\mathtt{Q w e n2.5{-}M a t h}$ ,相比其前身CodeQwen1.5和Qwen2-Math有了实质性的改进:Qwen2.5-Coder在包含5.5Ttokens编程相关数据上进行了训练,使即使较小的编程专用模型也能在编程评估基准测试中表现出媲美大型语言模型的竞争力。同时, $\mathtt{Q w e n2.5{-}M a t h}$ 支持中文和英文,并整合了多种推理方法,包括CoT(ChainofThought)、PoT(ProgramofThought)和TIR(Tool-IntegratedReasoning)。
图:Qwen2.5系列模型参数
| ModeIs | Layers | Heads (Q/KV) | Tie Embedding | Context/Generati on Length | License |
| 0.5B | 24 | 14/2 | Yes | 32K/8K | Apache 2. 0 |
| 1.5B | 28 | 12/2 | Yes | 32K/8K | Apache 2. 0 |
| 3B | 36 | 16/2 | Yes | 32K/8K | Qwen Resea rch |
| 7B | 28 | 28/4 | No | 128K/8K | Apache 2. 0 |
| 14B | 48 | 40/8 | No | 128K/8K | Apache 2.0 |
| 32B | 64 | 40/8 | No | 128K/8K | Apache 2.0 |
| 72B | 80 | 64/8 | No | 128K/8K | Qwen |
资料来源:阿里千问,中信建投
图:Qwen2.5-72B在多个领域领先Llama-3
| Datasets | Llama-3-70B | 3Mixtral-8x22BLlama-3-405B | Qwen2-72B | Qwen2.5-72B | Qwen2.5-Plus | ||
| General Tasks | |||||||
| MMLU | 79.5 | 77.8 | 85.2 | 84.2 | 86.1 | 85.4 | |
| MMLU-Pro | 52.8 | 51.6 | 61.6 | 55.7 | 58.1 | 64.0 | |
| MMLU-redux | 75.0 | 72.9 | 80.5 | 83.9 | 82.8 | ||
| BBH | 81.0 | 78.9 | 85.9 | 82.4 | 86.3 | 85.8 | |
| ARC-C | 68.8 | 70.7 | 68.9 | 72.4 | 70.9 | ||
| TruthfulQA | 45.6 | 51.0 | 54.8 | 60.4 | 55.3 | ||
| WindoGrande | 85.3 | 85.0 88.7 | 86.7 | 85.1 | 83.9 | 85.5 | |
| HellaSwag | 88.0 | - | 87.3 | 87.6 | 89.2 | ||
| Mathematics&ScienceTasks | |||||||
| GPQA | 36.3 | 34.3 | 37.4 | 45.9 | 43.9 | ||
| TheoremQA | 32.3 | 35.9 | 42.8 | 42.4 | 48.5 | ||
| MATH | 42.5 | 41.7 | 53.8 | 50.9 | 62.1 | 64.4 | |
| MMLU-stem | 73.7 | 71.7 83.7 | 79.6 | 82.7 | 81.2 | ||
| GSM8K | 77.6 | 89.0 | 89.0 | 91.5 | 93.0 | ||
| CodingTasks | |||||||
| HumanEval | 48.2 | 46.3 | 61.0 | 64.6 | 59.1 | 59.1 | |
| HumanEval+ | 42.1 | 40.2 | 56.1 | 51.2 | 52.4 | ||
| MBPP | 70.4 | 71.7 | 73.0 | 76.9 | 84.7 | 79.7 | |
| MBPP+ MultiPL-E | 58.4 | 58.1 | 63.9 | 69.2 60.5 | 66.9 | ||
| 46.3 | 46.7 | 59.6 | 61.0 | ||||
| MultilingualTasks | |||||||
| Multi-Exam Multi-Understanding | 70.0 79.9 | 63.5 | 76.6 | 78.7 | 78.5 89.2 | ||
| Multi-Mathematics | 67.1 | 77.7 | 80.7 76.0 | 89.6 76.7 | 82.4 | ||
| Multi-Translation | 38.0 | 62.9 23.3 | 37.8 | 39.0 | 40.4 | ||
Qwen2.5预训练阶段构建了更高质量数据集及专门的上下文训练方式
在预训练方面,Qwen2.5通过多种方式,进行高质量数据集构建,例如更好的数据过滤:引入 Qwen2-Instruct 模型对数据进行把关,不仅大幅提升了高质量训练数据的留存比例,还能更高效地筛除多语种低质样本。此外还使用Qwen2.5-Math和Qwen2.5-Coder的训练数据、借助Qwen2-72B-Instruct与Qwen2Math-72B-Instruct模型催生高质量合成数据以及启用Qwen2-Instruct模型对不同领域的内容进行分类梳理与均衡调配。Qwen2.5将高质量的预训练数据集从之前的 7 万亿个 token 扩展到了 18 万亿个 token。
预训练上下文方面,通过两阶段调节上下文长度,进而达到最优训练效果。Qwen2.5还采用了YARN 和双块注意力 DCA,实现了序列长度容量四倍的飞跃式增长,使得 Qwen2.5-Turbo 能够从容处理多达 100 万个token的序列,而其他模型也具备处理多达 131072 个token序列的能力。
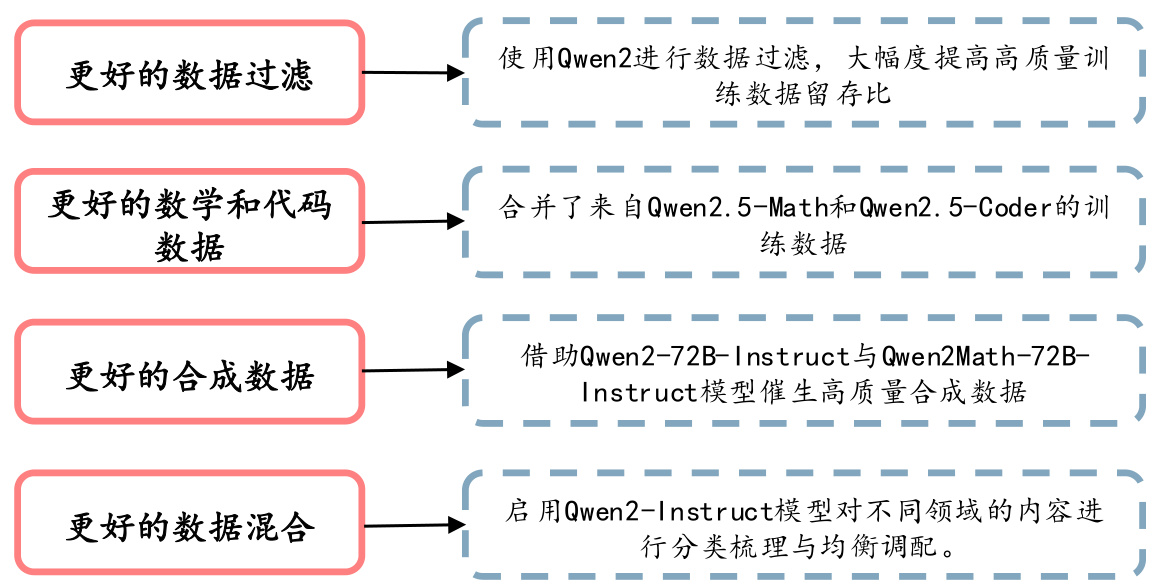
图:QWen2.5通过多种方式构建高质量数据集
资料来源:阿里千问,中信建投

图:使用专门的上下文训练方式,增强处理序列能力
通过扩大监督微调数据范围以及两阶段强化学习,增强模型处理能力
Qwen2.5监督微调通过多种方式,在长序列生成、数学问题解决、编码、指令遵循、结构化数据理解、逻辑推理、跨语言迁移和强大的系统指令等领域进行了微调数据覆盖,构建了一个包含超过 100 万个 SFT 示例的数据集,解决了先前模型在以上关键领域显示的局限性。
强化学习阶段,采用两阶段强化学习:离线 RL 和在线 RL。离线RL:主要针对推理、事实性和遵循指令等领域的能力开发。在线RL:在线强化学习阶段利用奖励模型检测输出质量细微差别的能力,包括真实性、有用性、简洁性、相关性、无害性和去偏差。
图:Qwen2.5在后训练阶段扩大监督微调数据覆盖范围
| 监督微调数据领域 | 增强方式 |
| 长序列生成 | 采用反向翻译技术从预训练语料库中生成长文本数据的查询, 施加输出长度限制,并使用Qwen2过滤掉低质量的配对数据。 |
| 数学 | 引入了Qwen2.5-Math的思想链数据,采用拒绝抽样以及奖励 建模和带注释的答案作为指导。 |
| 编码 | 深度融合Qwen2.5Coder的指令调优数据。 |
| 指令遵循 | 实施了严格的基于代码的验证框架。 |
| 结构化数据理解 | 开发了一个全面的结构化理解数据集。 |
| 逻辑推理 | 引入了一组跨越不同领域的70000个新查询。 |
| 跨语言迁移 | 采用翻译模型将指令从高资源语言转换为各种低资源语言。 |
| 强大的系统指令 | 构建了数百个通用系统提示。 |
| 回复过滤 | 采用了专用的评论家模型和多智能体协作评分系统。 |
资料来源:阿里千问,中信建投
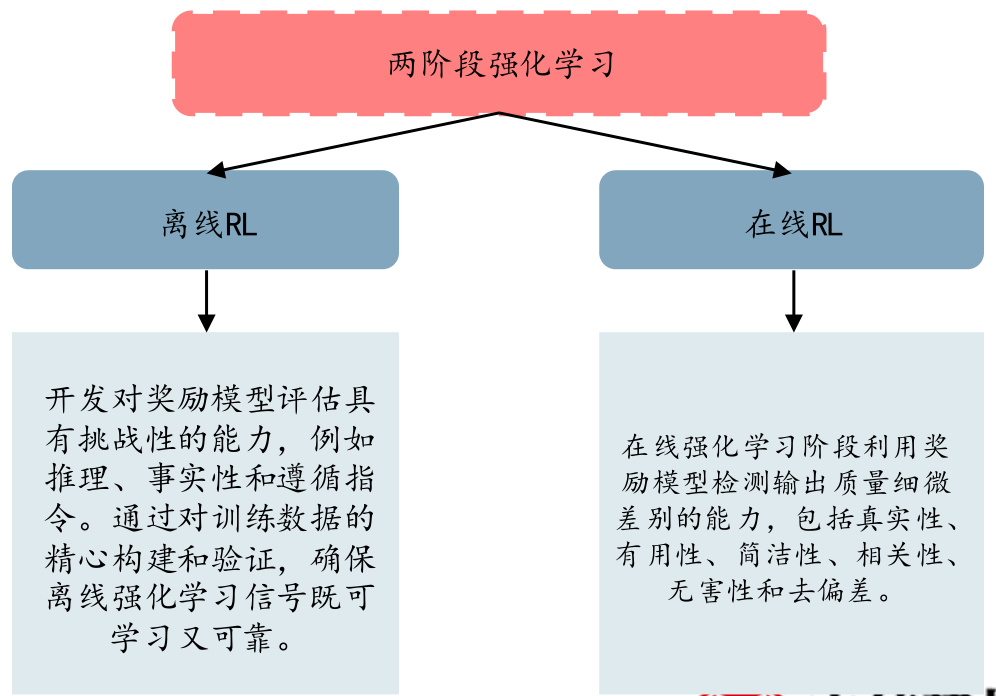
图:采用两阶段强化学习
Qwen2.5-1M和Qwen2.5 VL发布,进一步拓展Qwen2.5家族系列
阿里千问发布Qwen2.5-1M,通过逐步拓展上下文训练长度、长度外推和稀疏注意力机制等方式,将开源Qwen模型的上下文扩展到1M长度,在处理长文本任务中都已经实现稳定超越GPT-4o-mini。阿里千问还通过分块预填充、集成长度外推方案、稀疏性优化等优化,将处理1M长度输入序列的预填充速度提升了3.2倍到6.7倍。
阿里Qwen开源全新的视觉模型 $\mathsf{Q}\mathrm{wen2.5\mathrm{-}V L}$ ,推出3B、7B和72B三个尺寸版本。其中,旗舰版Qwen2.5-VL-72B在13项权威评测中夺得视觉理解冠军,全面超越GPT-4o与Claude3.5。
图:Qwen2.5-1M超越GPT-4o-mini
| Model | Claimed Length | RULER | |||||||
| Avg. | 4K | 8K | 16K | 32K | 64K | 128K | |||
| GLM4-9b-Chat-1M | 1M | 89.9 | 94.7 | 92.8 | 92.1 | 89.9 | 86.7 | 83.1 | |
| Llama-3-8B-Instruct-Gradient-1048k Llama-3.1-70B-Instruct | 1M 128K | 88.3 | 95.5 | 93.8 | 91.6 | 87.4 | 84.7 | 77.0 | |
| GPT-4o-mini | 128K | 89.6 87.3 | 96.5 95.0 | 95.8 | 95.4 | 94.8 | 88.4 | 66.6 | |
| GPT-4 | 128K | 91.6 | 96.6 | 92.9 96.3 | 92.7 95.2 | 90.2 93.2 | 87.6 87.0 | 65.8 81.2 | |
| Qwen2.5-32B-Instruct | RoPE | ||||||||
| DCA+YaRN | 32K 128K | 88.0 92.9 | 96.9 | 97.1 | 95.5 | 95.5 | 85.3 | 57.7 82.0 | |
| Qwen2.5-72B-Instruct | RoPE | 32K | 90.8 | 90.3 88.5 | 67.0 | ||||
| DCA+YaRN | 128K | 95.1 | 97.7 | 97.2 | 97.7 | 96.5 | 93.0 | 88.4 | |
| Qwen2.5-7B-Instruct | RoPE | 32K | 80.1 | 96.7 | 95.1 | 93.7 | 89.4 | 74.5 | 31.4 |
| Owen2.5-7B-Instruct-1M | DCA+YaRN RoPE/DCA+YaRN | 128K 1M | 85.4 91.8 | 96.8 | 95.3 | 93.0 | 91.1 | 82.3 90.4 | 55.1 84.4 |
| Qwen2.5-14B-Instruct | RoPE | 32K | 86.5 | 97.7 | 96.8 | 95.9 | 93.4 | 82.3 | 53.0 |
| Qwen2.5-14B-Instruct-1M | DCA+YaRN RoPE/DCA+YaRN | 128K 1M | 91.4 95.7 | 97.5 | 97.1 | 94.6 | 94.9 | 86.7 94.9 | 78.1 92.2 |
| Qwen2.5-Turbo | RoPE/DCA+YaRN | 1M | 93.1 | 97.5 | 95.7 | 95.5 | 94.8 | 90.8 | 84.5 |
资料来源:阿里千问,中信建投
图:Qwen2.5 VL全面超越GPT-4o与Claude3.5
| Qwen2.5-VL 72B | Gemini-2 Flash | GPT-40 | Claude3.5 Sonnet | Qwen2-VL 72B | OtherBest Open LVLM | ||
| College-level Problems Document and | MMMU | 70.2 | 70.7 | 70.3 | 70.4 | 64.5 | 70.1 |
| MMMU Pro | 51.1 | 57.0 | 54.5 | 54.7 | 46.2 | 52.7 | |
| DocVQA | 96.4 | 92.1 | 91.1 | 95.2 | 96.5 | 96.1 | |
| InfoVQA | 87.3 | 77.8 | 80.7 | 74.3 | 84.5 | 84.1 | |
| General Visual Question Answering | CC-OCR OCRBenchV2 | 79.8 | 73.0 | 66.6 46.5 | 62.7 45.2 | 68.7 47.8 | 68.7 |
| 61.5 | 47.8 | ||||||
| MegaBench MMStar | 51.3 | 55.2 69.4 | 54.2 64.7 | 52.1 65.1 | 46.8 | 47.4 | |
| MMBench1.1 | 70.8 88.0 | 83.0 | 82.1 | 83.4 | 68.3 86.6 | 69.5 87.4 | |
| Math | MathVista | 74.8 | 73.1 | 63.8 | 65.4 | 70.5 | 72.3 |
| MathVision | 38.1 | 41.3 | 30.4 | 38.3 | 25.9 | 32.2 | |
| Video Understanding | VideoMME | 73.3 | 71.9 | 60.0 | 71.2 | 72.1 | |
| MMBench-Video | 2.0 | 1.7 | 1.4 | 1.7 | 1.9 | ||
| LVBench | 47.3 | 30.8 | 43.6 | ||||
| CharadesSTA | 50.9 | 35.7 | 48.4 | ||||
| VisualAgent | AITZ | 83.2 | · | 35.3 | , | 53.3 | |
| Android Control | 67.4 | 66.4 | |||||
| ScreenSpot | 87.1 | 84.0 | 18.1 | 83.0 | 89.5 | ||
| ScreenSpot Pro | 43.6 | 17.1 | 38.1 | ||||
| AndroidWorld | 35.0 | 34.5 | 27.9 | 46.6 | |||
| OsWorld | 8.8 | 5.0 | 14.9 | 22.7 | |||
Qwen2.5-Max上线,性能超越DeepSeek V3
阿里千问发布大规模MoE模型 $\mathtt{Q w e n2.5–M a x}$ ,在超过20万亿个token上进行预训练,并使用精选的监督微调 (SFT) 和从人类反馈中强化学习 (RLHF) 方法进行了进一步的后训练。通过在包括 MMLU-Pro(通过大学级问题测试知识)、LiveCodeBench(评估编码能力)、LiveBench(全面测试一般能力)和 Arena-Hard(近似人类偏好)上进行测试,Qwen2.5-Max在大多数基准测试中都表现出了显著的优势,性能全面超越DeepSeek V3。
$_{\mathrm{Qwen2.5-max}}$ 多模态能力方面,在联网搜索、代码、游戏制作方面均有较好表现。
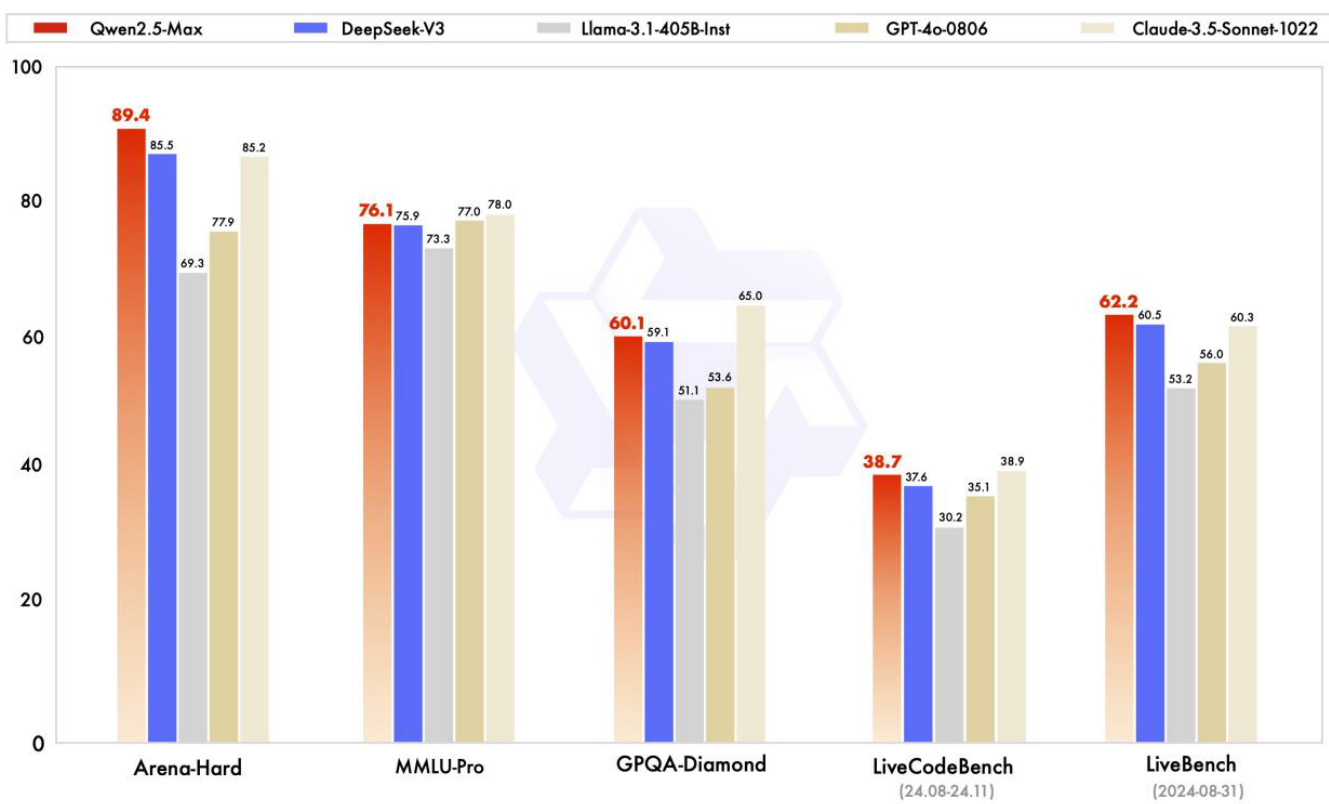
图:Qwen2.5-Max性能全面超越当前领先的先进模型
资料来源:阿里千问,中信建投
图:Qwen2.5-Max快速做出扫雷游戏
OpenAI o1模型可能采用PRM过程打分策略和蒙特卡洛搜索实现深度推理。
选择:从根节点开始,算法根据特定策略浏览有希望的子节点,直到到达叶节点为止。
扩展:在叶子节点处,除非它代表了博弈的终结状态,否则会添加一个或多个可行的新子节点,以说明未来可能采取的行动。
模拟或评估:从新添加的节点开始,算法进行随机模拟–通常称为 “滚动”–通过任意选择棋步直到博弈结束,从而评估节点的潜力。
反向传播:模拟后,结果(胜、负或和)会传播回根节点,更新每个遍历节点的统计数据(如胜、负),为未来决策提供依据。
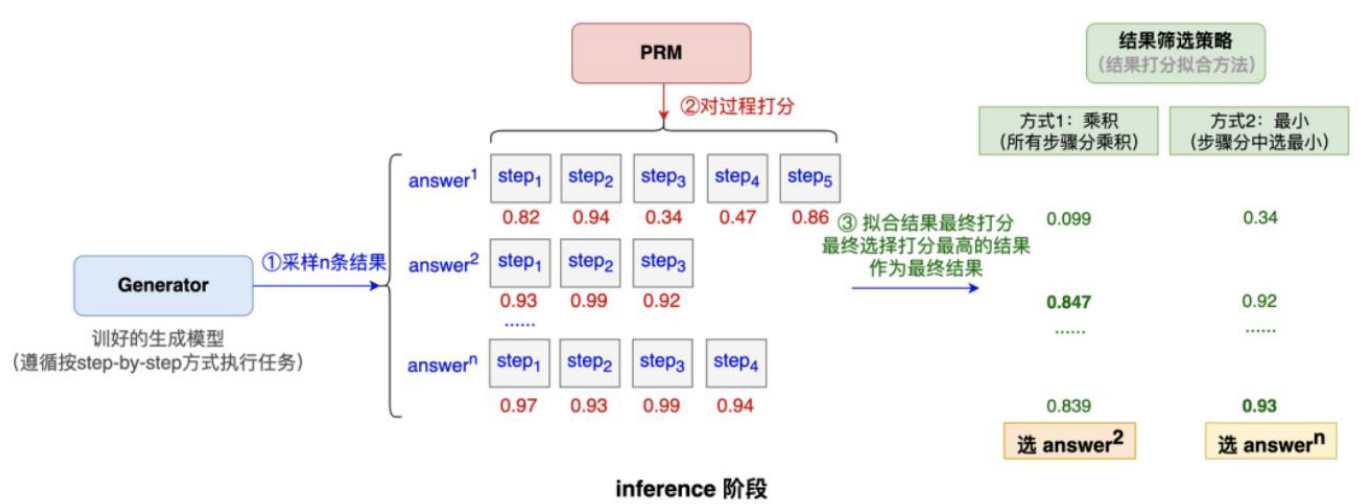
图:PRM过程

图:蒙特卡洛过程
资料来源:深度学习自然语言处理,UnderstandingTransformerReasoningCapabilitiesvia Graph Algorithms,Deepmind,中信建投
低成本缘由一:高度稀疏的模型架构
DeepSeekMoE在专家模型的设计上引入了共享专家 $^+$ 路由专家的架构,并采用无辅助损失的负载均衡策略,使得计算资源分配更加高效。DeepSeekMoE由256个路由专家组成,每个token在路由过程中会选择8个专家,其中共享专家始终被选中,其余7个专家通过门控机制选择。DeepSeek-V3共包含671B个参数,其中每个token激活37B个参数,训练数据量为14.8Ttoken。同时额外引入了一种无辅助损失的负载平衡策略以减轻因确保负载平衡而导致的性能下降。
Deepseek V2模型参数量达到236B,同时由于模型小专家混合的特性,模型每个token在推理时的激活参数为21B,可以实现高推理速度。模型的核心优化点多头隐式注意力显著降低了训练和推理成本。在成本效率方面,相比V1的稠密模型,V2模型节约了 $42.5%$ 的训练成本,减少了推理时 $93.3%$ 的KV-cache 显存占用,将生成的吞吐量也提升到了原来的5.76倍。
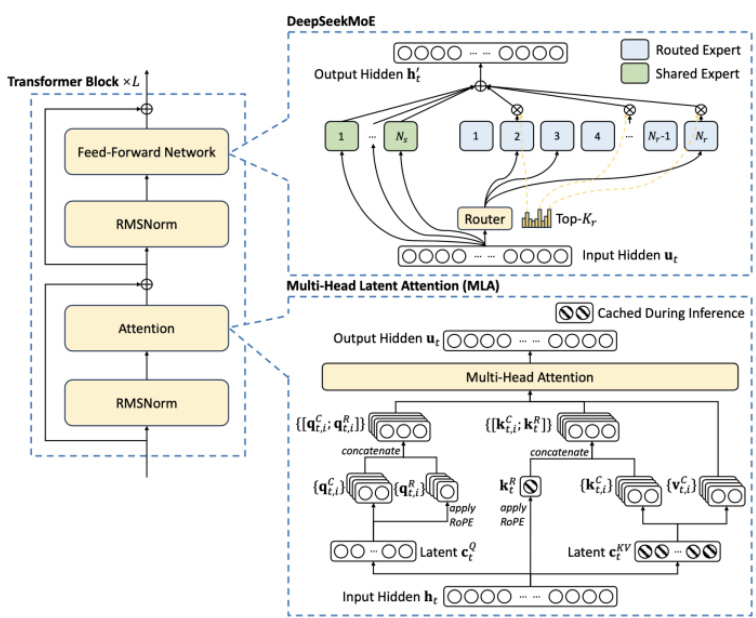
图:DeepSeek模型中的MOE架构
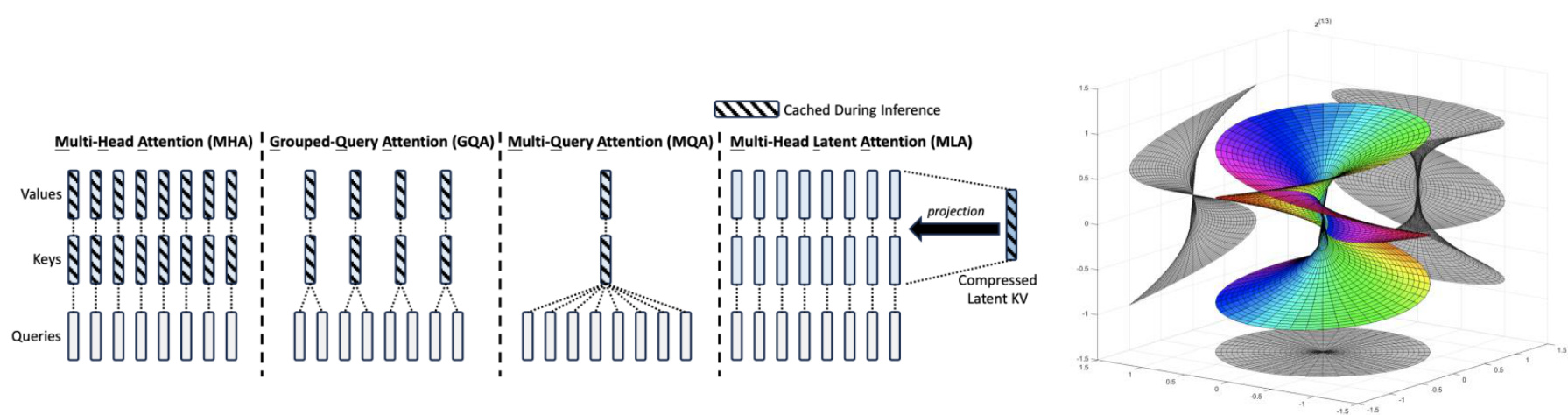
图:DeepSeek模型中的多头隐式注意力
低成本缘由二:FP8混合精度训练框架
Deepseek提出了一种用FP8训练的混合精度框架。在不同计算步骤中使用 FP8、BF16、FP32 三种不同的数值格式,以在计算效率和数值稳定性之间取得平衡。大多数计算密集型操作以FP8进行,与线性算子相关的所有三个核心计算内核操作,即Fprop(前向传播)、Dgrad(激活反向传播)和Wgrad(权重反向传播)均以FP8执行,而少数关键操作则策略性地保持其原始数据格式例如嵌入模块、输出头、MoE门控模块、归一化算子和注意力算子,以平衡训练效率和数值稳定性。
为了实现混合精度FP8训练,deepseek引入了多种策略来提升低精度训练的准确性,其中包括细粒度量化、提高累加精度、尾数优先于指数、在线量化等策略。细粒度量化的办法帮助FP8精度实现训练,传统的方法基于整个张量进行缩放,而细粒度量化则采用更小的分组单位,使得量化过程能够更好地适应离群值,从而提高训练的稳定性和精度。
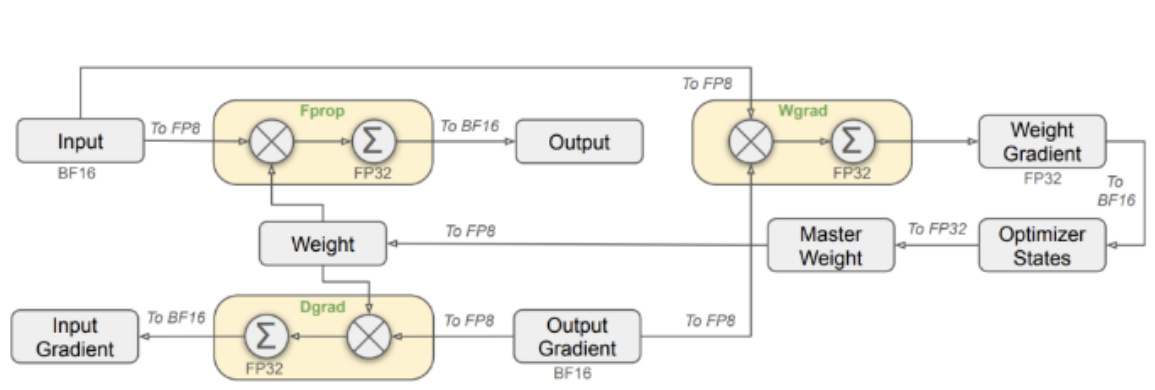
图:FP8训练框架
图:细粒度量化
原始矩阵
$$ X_{\mathrm{quantized}}={\left[\begin{array}{l l l l}{0}&{64}&{30}&{4}\ {-1}&{89}&{81}&{2}\ {38}&{-17}&{127}&{-51}\ {-25}&{8}&{-4}&{47}\end{array}\right]} $$
传统方法量化结果
$$ X_{\mathrm{quantized}}={\left[\begin{array}{l l l l}{\operatorname{round}(X_{1,1}/S_{1,1})}&{\operatorname{round}(X_{1,2}/S_{1,2})}&{\ldots\right]}\ {\ldots}&{}&{\qquadX_{\mathrm{quantized}}={\left[\begin{array}{l l l l}{0}&{127}&{127}&{9}\ {-2}&{127}&{127}&{3}\ {127}&{-32}&{127}&{-76}\ {-64}&{17}&{-9}&{73}\end{array}\right]}}\end{array}\right]} $$
低成本缘由三:流水线并行策略提升训练效率
DeepSeek-V3采用了16路管道并行(PP)、跨越8个节点的64路专家并行(EP)以及ZeRO-1数据并行(DP)。
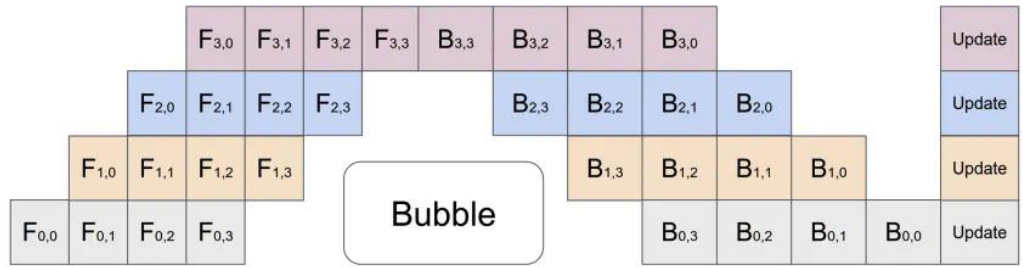
DualPipe是一种新型的流水线并行方法,旨在减少计算和通信之间的等待时间,提高训练效率。传统流水线并行方法的计算和通信比率通常接近 1:1,这意味着一半的时间可能被通信占据,导致GPU资源利用率低下。DualPipe通过计算-通信重叠来隐藏通信开销,使得模型在大规模分布式环境下的训练更加高效。在DualPipe中,前向传播的计算任务和反向传播的计算任务被重新排序,使它们能够互相重叠。具体来说,DualPipe 将前向传播和反向传播的不同计算阶段重新排列,并手动调整GPU计算单元在通信和计算之间的分配比例。

图: DualPipe训练方案
低成本缘由四:跨节点无阻通信设计
Deepseek高效配置专家分发与跨节点通信,实现最优效率。跨节点的GPU通过InfiniBand(IB)完全互连,节点内的通信则通过 NVLink 处理。NVLink提供160 GB/s的带宽,大约是IB(50 GB/s)的3.2倍。为了有效利用IB和NVLink的不同带宽,将每个token分发的节点数限制为最多4个,从而减少IB流量。具体而言每个token可以高效地选择每个节点平均3.2个专家,而不会产生NVLink的额外开销。
Deepseek采用了定制的PTX(并行线程执行)指令,并自动调整通信块大小,这显著减少了L2缓存的使用和对其他 SM的干扰。在模型训练的分发和合并过程中,通过warp专业化技术,并将20个SM划分为10个通信通道,实现了最佳的计算和通信资源配比。

图:专家分发设计
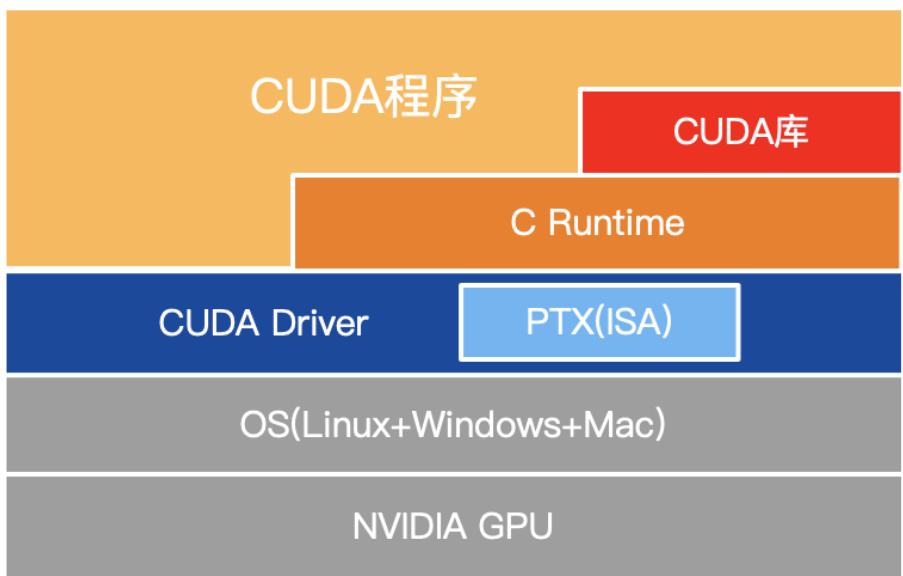
图:定制的PTX指令在CUDA中的位置
资料来源:中信建投
低成本缘由五:多token预测
DeepSeek-V3通过多token预测(MTP)技术不仅预测下一个token,还预测接下来的2个token,第二个token预测的接受率在不同生成主题中介于 $85%$ 到 $90%$ 之间。
一方面,多token预测目标增加了训练信号的密度,可能提高数据效率。另一方面,多token预测可能使模型能够预先规划其表示,以更好地预测未来token。
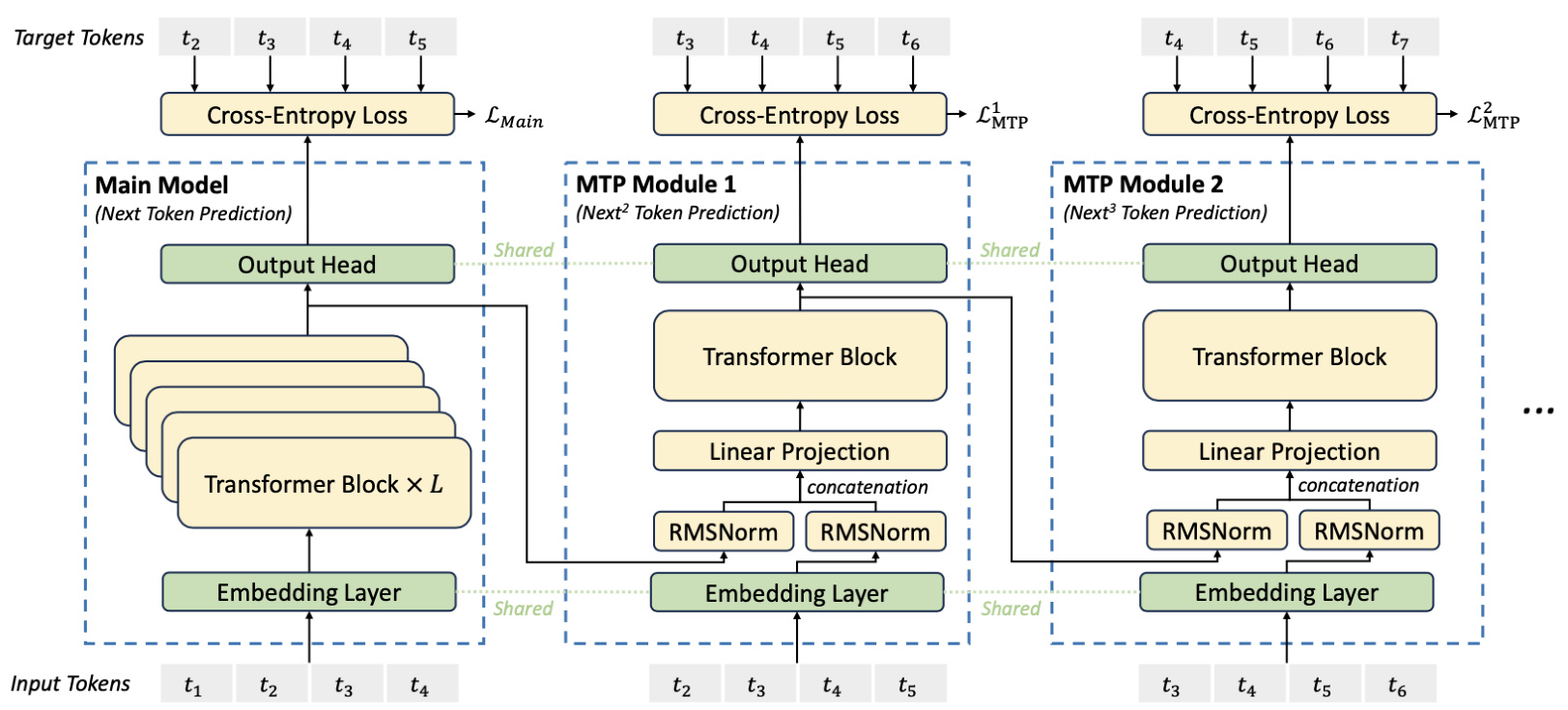
图:DeepSeek模型多token预测
深度推理激发长期算力需求
DeepSeek R1模型整体效果优异,同时训练和推理算力需求较低,主要原因是DeepSeek R1实现了算法、框架和硬件的优化协同,在诸多维度上进行了大量优化,算法层面引入专家混合模型、多头隐式注意力、多token预测,框架层面实现FP8混合精度训练,硬件层面采用优化的流水线并行策略,同时高效配置专家分发与跨节点通信,实现最优效率配置。
当前阶段大模型行业正处于从传统的生成式模型向深度推理模型过渡阶段,算力的整体需求也从预训练阶段逐步过渡向后训练和推理侧,通过大量协同优化,DeepSeek R1在特定发展阶段通过较少算力实现高性能模型表现,算力行业的长期增长逻辑并未受到挑战。过去的预训练侧的scaling law正逐步迈向更广阔的空间,在深度推理的阶段,模型的未来算力需求依然会呈现爆发式上涨,充足的算力需求对于人工智能模型的性能进步依然至关重要。

图:scaling law的延拓
图:OpenAI o3模型
模型案例对比——开关控制灯泡问题
开关控制灯泡问题:两个房子互为隔壁,一个房子中的三个开关控制另一个房子的三盏灯。你只能各进入这二个房子一次,怎么来判断哪个开关控制哪盖灯?
图:“开关控制灯泡问题”测试结果
Kimi 1.5
Deepseek R1 Qwen 2.5
GPT-o1
先在第一个房子里,依次打开开关1,保持几分钟后关掉;接着打开开关2,保持几分钟后关掉;最后打开开关3,保持几分钟后关掉。这样,每个开关都会在灯上留下不同的状态。然后,我进入第二个房子,检查每盏灯的状态。如果一盏灯是亮的,那它就是由最后一个被打开的开关控制的;如果一盏灯是暗的但摸起来是热的,那它就是由之前被打开的开关控制的;如果一盏灯是暗的且摸起来是凉的,那它就是由第一个被打开的开关控制的。
1.操作开关:
-进入开关房,打开开关A并保持足够时间(如5分钟)使灯泡发热。
-关闭开关A,立即打开开关B,然后离开开关房前往灯房。
2. 观察灯房:
-亮的灯:对应开关B(当前开启的开关)。-不亮但温热的灯:对应开关A(曾被长时间打开后关闭,余温尚存)。
-不亮且冷的灯:对应未操作的开关C。
首先,进入装有三个开关的房子。假设这三个开关分别为A、B和C。然后,打开开关A和B,并保持开关C关闭。在等待期间,不要立即进入另一个房子,确保给灯泡足够的时间变热。时间到了之后,进入装有灯泡的房子。通过这种方法,你可以准确地确定每个开关对应的是哪盏灯。具体来说,亮着且热的灯对应的是第一个被单独测试的开关(本例中为了说明设为B,但实际上你需要根据实际情况判断),热但熄灭的灯对应于中间被关闭的开关(A),而冷且熄灭的灯则是从未被打开过的那个开关(C)。
这是一个经典的灯泡—开关散热逻辑问题,常见的解决方法是利用灯泡“加热和”的时间差相互区分。具体步骤
1.先打开开关A一段时间,
2.到时间后,关闭开关A,并且打开开关B,保持开关C关闭不动
3.做完上述操作后,离开“切换所在的房间”
4.到达灯泡屋后,观察三盏灯:正在点亮的灯泡就是由开关B控制的;已经熄灭但仍然热的灯泡就是由开关A控制的;既不亮也不热的灯泡就是由开关C控制。这样,就在只进入灯泡房子一次。
模型案例对比——囚犯抓豆子博弈
囚犯抓豆子博弈:5个“囚犯”分别按 ${1\mathord{\sim}}5$ 号在装有100颗绿豆的麻袋里抓绿豆,规定每人至少抓一颗,而抓的最多和最少的人将被处死,若有重复的情况,则也算最大或最小,一并处死。他们之间不能交流,但在抓的时候,可以摸出剩下的豆子数。原则:100颗不必都分完;他们的原则是优先保命,再去多杀人;他们都足够聪明。最后,谁能活下来?
Kimi 1.5所以,我的结论是,最终可能会有几个人活下来,具体是谁取决于他们选择的豆子数,但因为每个人都很聪明,所以他们都会尽量避免成为最大或最小的那个,从而保命。最终,可能有几个人活下来。
Deepseek R1最终存活的是第3、4号囚犯,可能还包括第2号,具体分析如下:逆向推理:从最后一位(5号)开始,每位囚犯会尽量选择中间值以避免成为最大或最小。更优策略为:1号抓21颗(剩余79),2号抓20颗(剩余59),3号抓19颗(剩余40),4号抓18颗(剩余22),5号被迫抓17颗(剩余5)。结果:数量为21,20,19,18,17,最大21(1号),最小17(5号),处死1号和5号。关键逻辑:2、3、4号通过选择20、19、18颗,避开极端值。5号因剩余豆子数限制,无法逃脱最小值的命运。1号主动选择略高于平均值的21颗,触发后续递减链,确保自身成为唯一最大值。结论:第2、3、4号囚犯存活,1号和5号被处死。
qwen 2.5但在没有沟通的情况下,最合理和安全的做法可能是:1号:选择一个保守的数量,如20颗,因为他不知道别人的选择。2号:看到1号的选择后,选择比20稍少的数量,例如19颗。3号:看到前两者的行动后,可能会选择18颗。4号:根据前三者的行动,选择17颗。5号:最后,他将看到前面的所有选择,并选择一个保证他不成为最大或最小的数目。在这种情况下,每个人的策略都将依赖于之前人的选择,而最终结果将是每个人都选择了不同的数量,但差距不大,因此理论上,所有囚犯都有可能存活下来。
GPT-o1在“先保命、再多杀人”的共同理性与不能直接沟通的条件下,这个问题通常是最终答案是:2 号 、 3 号 人 数 ,1号、4号、5号被处死最常见、最稳妥的结论就是:1号和5号必死,4号也大概率跟随死,只有2号和3号才能找到一个安全且让别人去死的均衡策略。
模型案例对比——逻辑谜题
逻辑谜题:两个同学被老师出了一个题目,在限定时间,谁能够成功猜到是哪个日期会有奖励。首先老师给出了十个日期:5月16、5月17、5月19、6月15、6月18、7月14、7月16、8月14、8月15、8月17,然后告诉了A月份,告诉了B几号。老师知道他们不会将知道的告诉对方。限定时间准备到了的时候,A大笑说:“反正我是猜不出来,因为我很确定你也猜不出来”。突然b站起来开了门跑了出去,A才恍然大悟“我也猜出来了”,但是已经晚了。请问日期是多少?
图:“逻辑谜题”测试结果
Kimi 1.5
Deepseek R1
qwen 2.5
GPT-o1
A说他猜不出来,而且确定B也猜不出来。这意味着A知道的月份里,所有的日期都不是唯一的。A知道的月份只能是7月或8月。B听到A的话后,突然逃了出去。这说明B根据A的话,猜出了日期。所以,B知道的日期只能是16、15或17中的一个。因为16只有7月有,15和17只有8月有。B听到A的话后,突然逃了出去,说明B确定了具体是哪一天。因此,日期应该是7月16、8月15或8月17中的一个。最终答案是:7月16、8月15或8月17中的一个。
5月19日和6月18日的日数(19、18)唯一,若B知道这些日数,可直接确定月份。因此,A的月份不可能是5月或6月。A知道月份是7月或8月,但无法确定具体日期。B根据A的陈述,知A的月份为7月或8月。A的最终确认:若B猜出的是7月16日:A知道月份是7月,剩余日期为14和16。因B已确定,故排除14日,锁定7月16日。若B猜出的是8月15或17日,A无法唯一确定(因8月仍有多个可能)。因此,唯一符合逻辑的是7月16日。
A说的这句话意味着A知道的月份中包含的所有日子都不是唯一的(即在其他月份也出现),否则如果A知道的月份中的某天是独一无二的(比如只有某个月有这个日期),那么A不能确定地说B不知道答案。由于B能够确定具体日期,所以B知道的日期只能是16日或17日。而A听到B的回答后也明白了日期,说明A知道的月份里只剩下一种可能性。如果我们看剩下的日期,5月有两个可能(16日和17日),而7月只有一个16日。因此,A能明确知道日期必须是在7月16日。
这是一个著名的“猜测日期”类逻辑题,常被称为“谢丽尔的生日”变体。给出了10个可能的日期:>5月16日、5月17日、5月19日>6月15日、6月18日>7月14日、7月16日>8月14日、8月15日、8月17日老师告诉A“月份”,告诉B“几号”然后依次发生了对话:1.A说:“我肯定猜不出来,而且我也确定你(B)猜不出来。”2.B听完后说:“现在我知道是哪一天了。”3.A又说:“我现在也知道了!”根据这个推理,答案是7月16日。
模型案例对比——盲人分袜
盲人分袜:有两位盲人,他们都各自买了两对黑袜和两对白袜,八对袜子的布质、大小完全相同,而每对袜子都有一张商标纸连着。两位盲人不小心将八对袜子混在一起。他们每人怎样才能分别取回两对黑袜和两对白袜呢?
| Kimi 1.5 我觉得这个问题的关键在于如 何确保每个人拿到的黑袜和白 袜数量相等。既然每对袜子都 有商标纸连着,他们可以先将 八对袜子分成两组,每组四对。 然后,每个人检查自己组中的 黑袜和白袜数量,如果某组中 黑袜或白袜数量不对,他们可 以交换一些袜子,直到每组都 有两对黑袜和两对白袜。这样, 每个人都能确保拿到两对黑袜 和两对白袜,而且不需要多次 交换,比较方便。所以,最终 的方法是:将八对袜子分成两 组,每组四对,然后通过交换 确保每组都有两对黑袜和两对 白袜。 (分配不成立) | Deepseek R1 两位盲人各自取四对 袜子(共八对),将 每对袜子拆开成单只 每人获得八只袜子 (四黑四白),随机 重新配对后,必然形 成两对黑袜和两对白 袜。 答案:每位盲人各取 四对袜子,拆开后重 新随机配对,每人即 可得到两对黑袜和两 对白袜。 |
qwen 2.5
将所有八对袜子分成两个相等的组,每组包含四对袜子。在分配过程中,重要的是要确保每一对袜子(由商标纸连在一起的两只袜子组成)不被拆散。这样,每个组都将包含4对袜子。因为总共有8对袜子,分为两组后,每一组自然就会有4对袜子。由于原始设定是每位盲人原本应拥有两对黑袜和两对白袜,所以无论怎么随机分组,在最终分配给每位盲人的四对袜子里,都会满足至少含有两对黑袜和两对白袜的要求。最终分配:让两位盲人各自拿走一组(四对袜子)。根据上述分析,这意味着每位盲人都会得到他们需要的两对黑袜和两对白袜。(分配不成立)
GPT-o1
给出一种“经典拆对-重组” 的方法来解决这个“不可能”的难题。其要点是:虽然两个盲人都看不见颜色,但每个“对”袜子上都带有一份可以摸到的商标纸上,让他们在操作时始终知道“哪只袜子到底和哪只图案对应”通过把几对袜子拆开、打乱、重新安装,并按一定规则交换,最后便可保证每个人都拿回“2对黑袜+2”对白袜”(当然,不一定是自己理解的那几对,但数量和颜色都对)
模型案例对比——数字推理
数字推理:2,1,32,249,()。幂次数列,1的1次方 $+1$ ,2的2次方-3,3的3次方 $+5$ ,4的4次方-7,依次类推,下位数字为5的5次方 $+9$ ,即3134。
图:“数字推理”测试结果
Kimi 1.5
Deepseek R1
qwen 2.5
递推规律:
第n项与底数 $(\mathrm{n}^{-1}$ )的5次方相关,
并加上递增的修正值:$\mathrm{n=1:2{=}2\hat{}1}$ $\mathrm{n}{=}2:1{=}1\hat{\mathbf{\alpha}}1$ $\mathrm{n=3:32{=}2\hat{}5}$ $\mathrm{n}{=}4:249{=}3{\widehat{\cdot}}5{+}6$ $\mathrm{n}=5:4\hat{\textmd{5}}+12=1024+12=1036$
计算差值->计算第二次差值->计算第三次差值->假设多项式->建立方程组->从方程1中减去方程2->从方程2中减去方程3->从方程3中减去方程4->从方程A中减去方程B->从方程B中减去方程 $\mathrm{C}-$ >从方程D中减去方程E->将 a代入方程 $.\mathrm{D}\substack{-}\rangle$ 将a和b代入方程A->将a、b和c代入方程 $1->$ 多项式为:$f\left(n\right)=\left({77/3}\right)n3\mathrm{-}138n2\mathrm{+}\left({700/3}\right)n\mathrm{-}1$ 19
直接从这些数字中找到一个明显的数学规律可能不容易,因此我们可以尝试不同的方法来解析这个序列。一种常见的策略是考虑数字是否可以通过某种运算或者公式从它们的位置(即在序列中的索引)计算得出。……但在实际情况下,如果这是一个逻辑推理题,最可能的情况是设计者期望我们发现一个特定但不易察觉的规律。鉴于当前的信息,我们无法提供一个确切的答案。如果你有更多的上下文或者是这个序列属于某一类特殊数列,请提供更多信息以便于更准确地解答。
GPT-o1•第1项: $11+1=21\hat{1}1+1=211+1=2$ •第2项: $22-3{=}4-3{=}12^{\circ}2{-}3{=}4{-}$ $3{=}122{-}3{=}4{-}3{=}1$ •第3项: $33+5=$ 二十七 $+5=$ 三十二$3^{\circ}3+5{=}27+5{=}3233{+}5{=}.$ 二十七 $+5=$ 三十二•第4项: $44-7{=}256-7{=}2494^{\circ}4^{-}$ $7=256-7=24944-7=256-7=249$ 可以看出,“奇数项”为 $\mathrm{nn+}$ (2n−1) $\hat{\mathrm{n}\mathrm{n+(2n-1)\thinspacenn+}}$ (2n−1),“偶nn−(2n−1)$\mathrm{\hat{nn-}(2n{-1})}}5\mathrm{+}(2\backslash}\end{array}$ $\pm55+\times5-1)=3125+9=3134$ 。所以中间的数字是 $3134.$ 。n n-(2n{-1})}$ )因此。$55+$ ( $2\times5\mathrm{-}1)$ )= $\begin{array}{r l r}{3125\mathrm{+}9}&{{}=}&{3134.5\hat{\mathrm{
答案:括号内应填1036。
风险提示
大模型技术发展不及预期:大模型属于先进AI算法,若后续大模型算法更新迭代效果不及预期,则会影响大模型演进及拓展,进而会影响其商业化落地等;
商业化落地不及预期:大模型的商业落地模式在业界中普遍处于探索阶段,用户对于大模型的接受程度和商业化变现能力可能不及预期;
算力基础设施支持不及预期:美国制裁中国高科技企业,对中国形成芯片、算力的封锁,大语言模型训练过程中需要大量算力资源,需要关注中美关系带来的算力的压力;
政策监管力度不及预期:大语言模型带来新的网络生态商业,尚属于前期成长阶段,政策监管难度加大,相关法律法规尚不完善,政策监管力度可能不及预期;
数据数量与数据质量不及预期:大型语言模型需要大量的高质量数据进行训练,若数据数量和质量存在短板,则会影响大语言模型效果。
感谢樊文辉、陈思玥、孟龙飞对本报告的贡献。
分析师介绍
于芳博:中信建投人工智能组首席分析师,北京大学空间物理学学士、硕士,2019年7月加入中信建投,主要覆盖人工智能等方向,下游重点包括智能汽车、CPU/GPU/FPGA/ASIC、EDA和工业软件等方向。
庞佳军:电子行业联席首席分析师、人工智能组联席首席分析师,东南大学硕士,7年半导体行业经验,曾在Marvell、Nvidia、平头哥半导体、乐鑫科技等公司从事芯片研发和管理,2022年加入中信建投电子团队,专注研究CPU、GPU、EDA等领域。
辛侠平:中信建投证券人工智能行业分析师,中央财经大学硕士,2022年加入中信建投人工智能团队,重点覆盖人工智能、AI芯片、智能驾驶等领域。
研究助理
评级说明
| 投资评级标准 | 评级 | 说明 |
| 报告中投资建议涉及的评级标准为报告发布日后6个 月内的相对市场表现,也即报告发布日后的6个月内 公司股价(或行业指数)相对同期相关证券市场代 表性指数的涨跌幅作为基准。A股市场以沪深300指 数作为基准;新三板市场以三板成指为基准;香港 市场以恒生指数作为基准;美国市场以标普500指 数为基准。 | 买入 股票评级 | 相对涨幅15%以上 |
| 增持 | 相对涨幅5%—15% | |
| 中性 | 相对涨幅-5%—5%之间 | |
| 减持 | 相对跌幅5%—15% | |
| 卖出 | 相对跌幅15%以上 | |
| 强于大市 行业评级 中性 | 相对涨幅10%以上 | |
| 相对涨幅-10-10%之间 | ||
| 弱于大市 | 相对跌幅10%以上 |
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除。
行业报告资源群

- 进群福利:进群即领万份行业研究、管理方案及其他
学习资源,直接打包下载 - 每日分享: $6+$ 份行研精选、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

知识星球 行业与管理资源

微信扫码 行研无忧
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。
分析师声明
本报告署名分析师在此声明:(i)以勤勉的职业态度、专业审慎的研究方法,使用合法合规的信息,独立、客观地出具本报告, 结论不受任何第三方的授意或影响。(ii)本人不曾因,不因,也将不会因本报告中的具体推荐意见或观点而直接或间接收到任何形式的补偿。
法律主体说明
本报告由中信建投证券股份有限公司及/或其附属机构(以下合称“中信建投”)制作,由中信建投证券股份有限公司在中华人民共和国(仅为本报告目的,不包括香港、澳门、台湾)提供。中信建投证券股份有限公司具有中国证监会许可的投资咨询业务资格,本报告署名分析师所持中国证券业协会授予的证券投资咨询执业资格证书编号已披露在报告首页。
用的法律法规情况下,本报告亦可能由中信建投(国际)证券有限公司在香港提供。本报告作者所持香港证监会牌照的中央编号已披露在报告首页
一般性声明
本报告由中信建投制作。发送本报告不构成任何合同或承诺的基础,不因接收者收到本报告而视其为中信建投客户。本报告的信息均来源于中信建投认为可靠的公开资料,但中信建投对这些信息的准确性及完整性不作任何保证。本报告所载观点、评估和预测仅反映本报告出具日该分析师的判断,该等观点、评估和预测可能在不发出通知的情况下有所变更,亦有可能因使用不同假设和标准或者采用不同分析方法而与中信建投其他部门、人员口头或书面表达的意见不同或相反。本报告所引证券或其他金融工具的过往业绩不代表其未来表现。报告中所含任何具有预测性质的内容皆基于相应的假设条件,而任何假设条件都可能随时发生变化并影响实际投资收益。中信建投不承诺、不保证本报告所含具有预测性质的内容必然得以实现。
本报告内容的全部或部分均不构成投资建议。本报告所包含的观点、建议并未考虑报告接收人在财务状况、投资目的、风险偏好等方面的具体情况,报告接收者应当独立评估本报告所含信息,基于自身投资目标、需求、市场机会、风险及其他因素自主做出决策并自行承担投资风险。中信建投建议所有投资者应就任何潜在投资向其税务、会计或法律顾问咨询。不论报告接收者是否根据本报告做出投资决策,中信建投都不对该等投资决策提供任何形式的担保,亦不以任何形过所去提在、公法现司律在提法或供规未或及来者监都争管不取规会为定直其允接提许或供的间投范接资围与银内其行,所、中撰做信写市建报交投告易可中、能的财持具务有体顾并观问交点或易相其本联他报系金告,融中分服所析务提师。公亦本司不报的会告股因内份撰容或写真其本实他报、财告准产而确权获、益取完,不整也当地可利反能益映在。了过署去名1分2个析月师、的目观前点或,者分将析来师为的本薪报酬告无中论为中信建投所有。未经中信建投事先书面许可,任何机构和/或个人不得以任何形式转发、翻版、复制、发布或引用本报告全部或部分内容,亦不得从投书面授权的任何机构、个人或其运营的媒体平台接收、翻版、复制或引用本报告全部或部分内容。版权所有,违者必究。
中信建投证券研究发展部
中信建投(国际)
北京
朝阳区景辉街16号院1号楼18层
电话:(8610)56135088
联系人:李祉瑶
邮箱:[email protected]
上海 深圳
浦东新区浦东南路528号南塔2103室 福田区福中三路与鹏程一路交汇处
电话:(8621)6882-1600 广电金融中心35楼
联系人:翁起帆 电话:(86755)8252-1369
邮箱:[email protected] 联系人:曹莹邮箱:[email protected]
香港
中环交易广场2期18楼
电话:(852)3465-5600
联系人:刘泓麟
邮箱:[email protected]
文章作者 大模型
上次更新 2025-03-09