通信_行业周报_DeepSeek_V3推进技术突破与创新_降低模型开发门槛_AI行业跟踪45期
文章目录
DeepSeek-V3 推进技术突破与创新,降低模型开发门槛
AI 行业跟踪 45 期(20241230-20250103)
核心结论
行业要闻跟踪
DeepSeek-V3 训练和使用成本大幅降低,或有望助力商业端落地算力优化。
性能提升结果:英语任务、代码评测、数学任务和中文任务等多项测评成绩领先。
性能提升途径:创新优化技术架构,利于提高模型能力。
训练成本优化:引入 FP8 训练和细粒度量化策略,大幅降低计算时间。相比于 Meta 的 Llama3 需要 16384 块 H100 GPU 训练,DeepSeek-V3 仅需2048 块 H800 GPU 即可完成相同规模的任务,训练成本低至约 557 万美元。
用户使用门槛降低:1)软硬件一体化支持,提升推理效率。DeepSeek 首发支持国内昇腾平台(Ascend)和 MindIE 推理引擎,这种软硬件一体化的支持使得用户能够在不同的硬件环境中灵活高效地部署模型。2)支持多种 主 流 框 架 、 全 面 开 源 策 略 。 模 型 支 持 SGLang 、 LMDeploy 和TensorRT-LLM 等多个主流框架,开发者可以根据自身需求选择合适的开发工具和框架。3)灵活的 API 定价模型,降低每百万 token 的处理成本。
我们认为,DeepSeek-V3 的表现给前沿 LLM 训练降本带来新的解决路径和可能性,模型端使用成本的下降有助于推动商业端落地的闭环。
行情回顾
2024 年 12 月 30 日-2025 年 1 月 3 日,我们构建的西部 AI 股票池中,其中 75家 A 股公司整体周平均跌幅 $12.1%$ ,60 家美股公司整体周平均涨幅 $1.27%$ 。A股公司中,算力租赁,AI 应用和液冷散热板块上跌幅度最小,分别下跌 $9.6%$ 、$10.3%$ 、 $10.3%$ 。美股公司中,液冷散热,高速 serdes 和存储芯片板块涨幅最大,分别上涨 $9.2%$ 、 $4.5%$ 、 $3%$ 。根据西部通信股票池,A 股市场中本周涨幅居前十的个股分别是共进股份( $+6.2%$ )、太辰光( $+3.4%$ )、寒武纪( $(-4.8%$ )、沪电股份( $(-4.9%$ )、鹏鼎控股 $(.5.5%)$ )、光云科技( $(-5.8%$ )、恒为科技 $(-6.1%)$ )、虹软科技 $(-6.7%)$ )、海康威视( $(-7.2%)$ )、云天励飞( $(-7.6%$ )。美股市场中本周涨幅居前五的个股分别是 Coherent( $+9.5%$ )、VERTIV( $+9.2%$ )、Snap( $+8.9%)$ )、BigBear.ai Holdings( $+7.6%$ )、Lumentum 控股( $+5.9%$ )。
投资建议:AIGC 和数字中国共振,算力托底。建议重点关注 AI 算力硬件,关注光模块(中际旭创、天孚通信、源杰科技等);散热领域(英维克)及 ICT 设备商等。
风险提示:技术落地不及预期、硬件设备市场接受度不及预期、监管政策风险。
| 分析师 |
| 陈彤 S0800522100004 |
| 18859272982 |
| [email protected] |
| 联系人 |
| 张璟 |
| 17521789238 |
| [email protected] |
相关研究
通信:豆包发布视觉理解模型,布局 AI 云原生 — AI 行 业 跟 踪 44 期(20241216-20241220) 2024-12-22通信:持续聚焦 AI 算力,关注低轨卫星互联网和出海成长股—2025 年通信行业投资策略报告 2024-12-22通信:从 Arista 看交换机行业投资逻辑—通信行业深度报告:交换机行业研究 2024-12-20
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除
行业报告资源群
- 进群福利:进群即领万份行业研究、管理方案及其他学
习资源,直接打包下载 - 每日分享:6份行研精选报告、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

微信扫码,长期有效
知识星球 行业与管理资源
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。

内容目录
AI 行业重点事件点评 31.1 DeepSeek-V3 训练和使用成本大幅降低,或有望助力商业端落地 …. 3
二、 AI 行业动态一览. 62.1 国外行业动态 6(1)AI大模型 6(2)应用 .62.2 国内行业动态.(1)AI大模型(2)应用..
三、 AI 行情回顾:A 股整体下跌,美股液冷散热板块领涨
四、 投资建议:持续关注 AI 应用和算力基础设施 8
五、 风险提示 8
图表目录
图 1:DeepSeek-V3 与主流模型在多领域测评任务中的表现对比 ..
图 2:DeepSeek-V3 模型训练成本
图 3:DeepSeek-V3 核心架构图(包含MoE和MLA) 5图 4:DualPipe 调度算法示意图… 5图 5:A 股 AI 行业细分板块周涨跌幅对比(12.30-01.03) ?图 6:美股 AI 行业细分板块周涨跌幅对比(12.30-01.03) 8
一、AI行业重点事件点评
1.1 DeepSeek-V3训练和使用成本大幅降低,或有望助力商业端落地
DeepSeek-V3 是由中国人工智能公司深度求索于 2024 年 12 月 26 日推出的一款自研混合专家(MoE)模型,旨在突破当前大语言模型的性能瓶颈。该模型拥有 6710 亿参数和370 亿激活参数,在 14.8 万亿 token 上完成了预训练,同时率先采用无辅助损失的负载均衡策略和多令牌预测训练目标以增强模型性能。作为一款开源模型,DeepSeek-V3 支持在线使用和本地部署,在多项评测中超越了其他开源模型,并在性能上与顶尖闭源模型相媲美。DeepSeek 公司通过创新的技术和架构设计推动了大模型的发展,DeepSeek-V3不仅在性能和成本控制方面实现了显著突破。
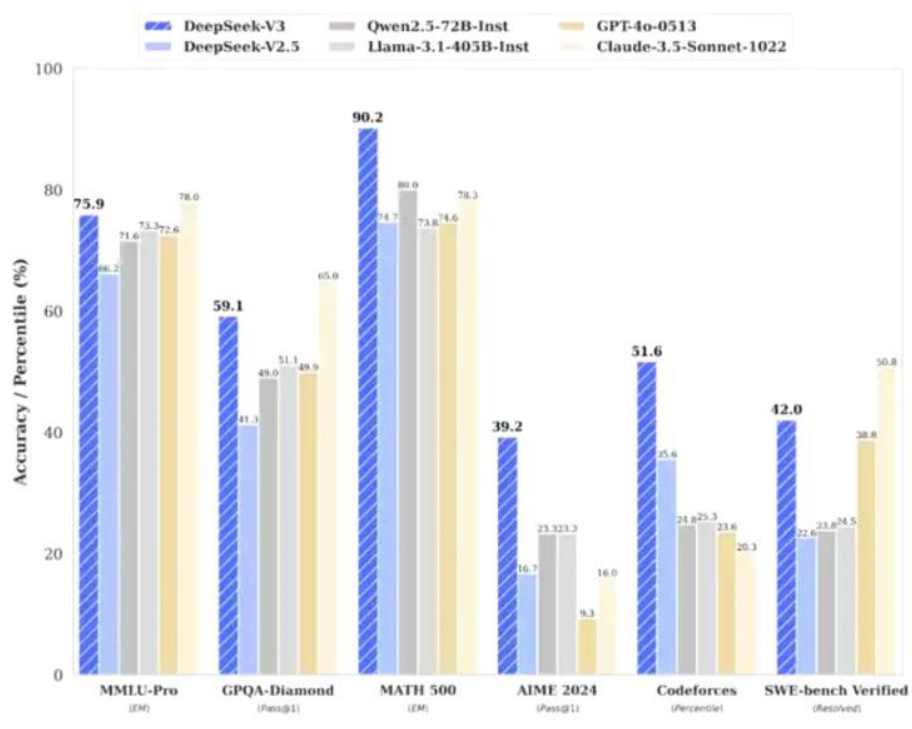
图 1:DeepSeek-V3 与主流模型在多领域测评任务中的表现对比
资料来源:51CTO,西部证券研发中心
性能提升结果:英语任务、代码评测、数学任务和中文任务等多项测评成绩领先。1)在英语任务中,模型在 MMLU (EM) 和 MMLU-Redux (EM) 中分别取得 $88.5%$ 和 $89.1%$ 的准确率,表现接近甚至超越部分闭源模型,并在 DROP (3-shot F1) 中以 $91.6%$ 领先所有对比模型。2)在代码评测中,DeepSeek-V3 在 HumanEval-Mul 和 LiveCodeBench 等测试中表现优异,生成与理解能力接近甚至超越 GPT-4o 和 Claude-3.5-Sonnet。3)在数学任务中,模型以 $39.2%$ (AIME 2024)和 $90.2%$ (MATH-500)的准确率位居前列,展现了强大的数学推理能力。在美国数学竞赛和全国高中数学联赛等专业任务中,DeepSeek-V3 的表现同样远超同类模型,包括 Meta 的 Llama-3.1-405B 和 OpenAI 的GPT-4o。4)在中文任务中,DeepSeek-V3 在 CLUEWSC、C-Eval 和 C-SimpleQA 测试中排名第一,显示了其深厚的中文处理实力。5)此外,在长文本任务中,模型在 DROP评测中以 $91.6%$ 的准确率领先。这些评测结果进一步证明了 DeepSeek-V3 在语言理解、生成和多任务适应性方面的先进性,展现了广泛的应用潜力。
图 7:DeepSeek-V3 与其他主流模型在多种基准测试中的对比表
| Benchmark(Metric) | DeepSeek- V3 | Qwen2.5 72B-Inst. | Llama3.1 405B-Inst. | Claude-3.5- Sonnet-1022 | GPT-40 0513 | |
| Architecture | MoE | Dense | Dense | |||
| #ActivatedParams | 37B | 72B | 405B | |||
| #TotalParams | 671B | 72B | 405B | |||
| MMLU (EM) | 88.5 | 85.3 | 88.6 | 88.3 | 87.2 | |
| MMLU-Redux(EM) | 89.1 | 85.6 | 86.2 | 88.9 | 88 | |
| MMLU-Pro(EM) | 75.9 | 71.6 | 73.3 | 78 | 72.6 | |
| DROP(3-shotF1) | 91.6 | 76.7 | 88.7 | 88.3 | 83.7 | |
| IF-Eval(Prompt Strict) | 86.1 | 84.1 | 86 | 86.5 | 84.3 | |
| GPQA-Diamond(Pass@1) | 59.1 | 49 | 51.1 | 65 | 49.9 | |
| SimpleQA(Correct) | 24.9 | 9.1 | 17.1 | 28.4 | 38.2 | |
| FRAMES(Acc.) | 73.3 | 69.8 | 70 | 72.5 | 80.5 | |
| LongBenchv2(Acc.) | 48.7 | 39.4 | 36.1 | 41 | 48.1 | |
| Code | HumanEval-Mul (Pass@1) | 82.6 | 77.3 | 77.2 | 81.7 | 80.5 |
| LiveCodeBench(Pass@1-COT) | 40.5 | 31.1 | 28.4 | 36.3 | 33.4 | |
| LiveCodeBench(Pass@1) | 37.6 | 28.7 | 30.1 | 32.8 | 34.2 | |
| Codeforces(Percentile) | 51.6 | 24.8 | 25.3 | 20.3 | 23.6 | |
| SWEVerified(Resolved) | 42 | 23.8 | 24.5 | 50.8 | 38.8 | |
| Aider-Edit(Acc.) | 79.7 | 65.4 | 63.9 | 84.2 | 72.9 | |
| Aider-Polyglot(Acc.) | 49.6 | 7.6 | 5.8 | 45.3 | 16 | |
| Math | AIME2024(Pass@1) | 39.2 | 23.3 | 23.3 | 16 | 9.3 |
| MATH-500(EM) | 90.2 | 80 | 73.8 | 78.3 | 74.6 | |
| CNMO2024(Pass@1) | 43.2 | 15.9 | 6.8 | 13.1 | 10.8 | |
| Chinese | CLUEWSC(EM) | 90.9 | 91.4 | 84.7 | 85.4 | 87.9 |
| C-Eval(EM) | 86.5 | 86.1 | 61.5 | 76.7 | 76 | |
| C-SimpleQA(Correct) | 64.1 | 48.4 | 50.4 | 51.3 | 59.3 | |
资料来源:MEO AI,西部证券研发中心
性能提升途径:创新优化技术架构,利于提高模型能力。作为一款拥有 6710 亿参数的混合专家(MoE)模型,其每个 Token 激活参数达到了 37B,通过 Auxiliary-Loss-Free LoadBalancing 和 Multi-Token Prediction(MTP)技术的引入,显著提高了模型在推测解码和数据使用效率上的能力。与传统 Transformer 架构不同,DeepSeek-V3 在架构设计中对专家路由和负载均衡进行了深度优化,确保每个 Token 的处理更加高效,同时减少了计算资源的浪费。
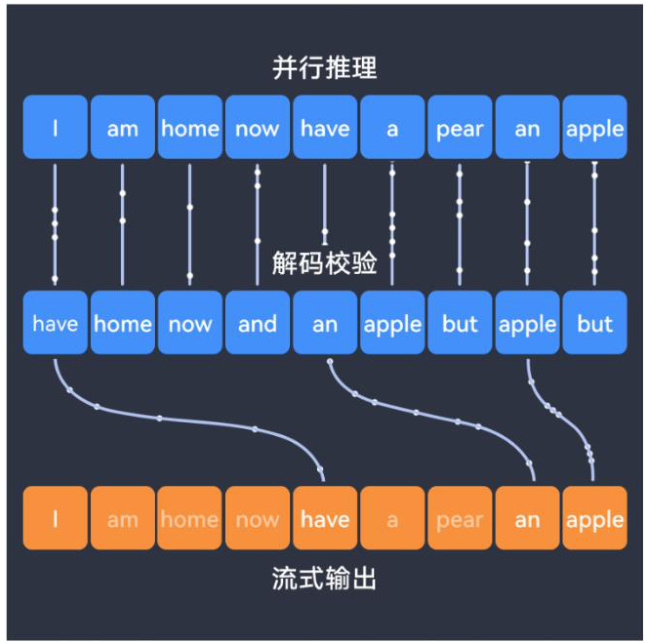
图 5:MindIE 解码优化示意图
资料来源:51CTO,西部证券研发中心
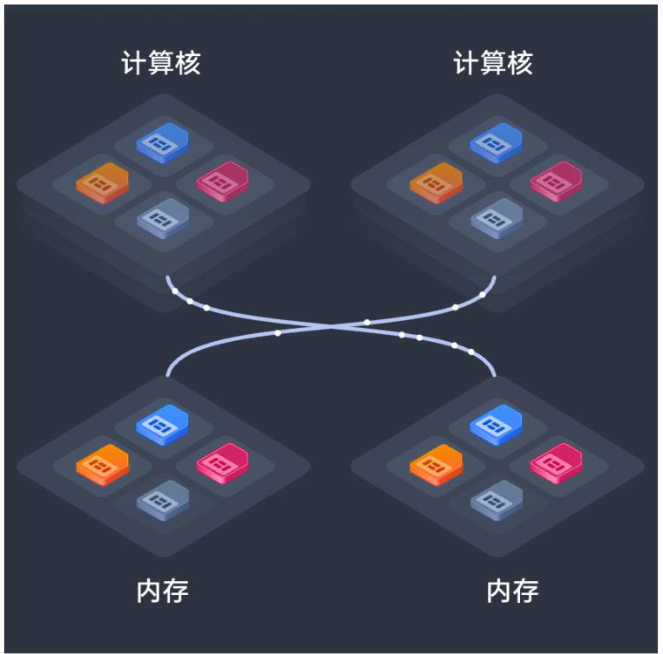
图 6:MindIE 通信加速示意图
资料来源:51CTO,西部证券研发中心
训练成本优化:引入 FP8 训练和细粒度量化策略,大幅降低计算时间。特别是 FP8 训练通过在 Tile 和 Block 级别引入分组缩放因子,改善了量化误差,并且进一步优化了矩阵乘法(GEMM)的累加精度,使其在大规模计算中依然保持高精度表现。此外,DualPipe算法的应用实现了计算和通信的高效重叠,大幅降低了跨节点通信的延迟,使得跨节点的专家路由变得更加顺畅和高效。相比于 Meta 的 Llama3 需要 16384 块 H100 GPU 训练,DeepSeek-V3 仅需 2048 块 H800 GPU 即可完成相同规模的任务,训练成本低至约 557万美元。
图 2:DeepSeek-V3 模型训练成本
| Training Costs | Pre-Training | ContextE Extension | Post-Training | Total |
| inH800GPUHours | 2664K | 119K | 5K | 2788K |
| inUSD | $5.328M | $0.238M | $0.01M | $5.576M |
Table1|Training costs ofDeepSeek-V3,assuming therental price of H00is $$2$ per GPU hour.
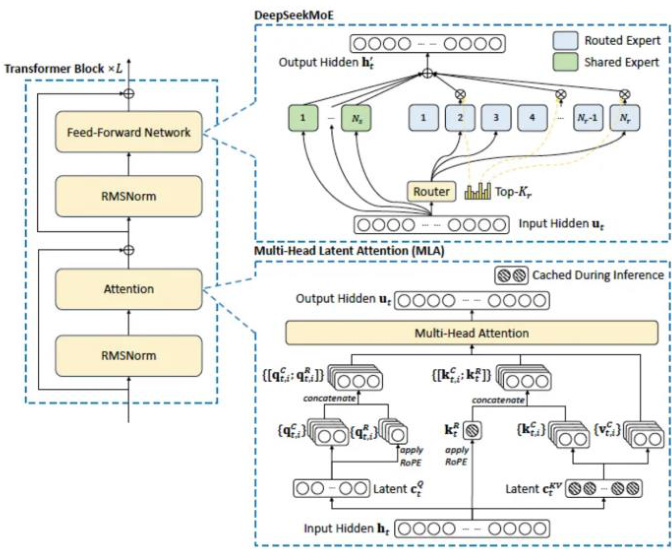
图 3:DeepSeek-V3 核心架构图(包含 MoE 和 MLA)
资料来源:zartbot,西部证券研发中心
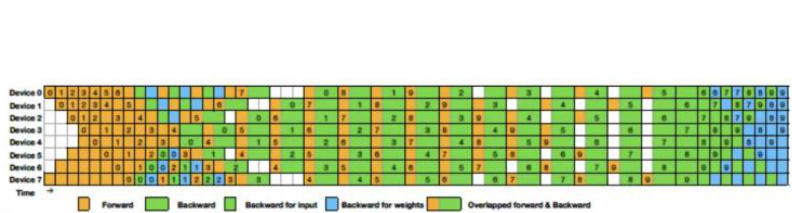
图 4:DualPipe 调度算法示意图
Figure5|ExampleDualPipe schedulingfor8PPranks and20micro-batchesintwodirections. Themicro-batchesinthereversedirectionaresymmetrictothoseintheforwarddirectionso weomittheirbatchIDforillustrationsimplicity.Twocellsenclosedbyasharedblackborder havemutuallyoverlappedcomputationandcommunication.
| Method | Bubble | Parameter | Activation |
| 1F1B | (PP-1)(F+B) | 1x | PP |
| ZB1P | (PP-1)(F+B-2W) | 1x | PP |
| DualPipe(Ours) | (P-1)(F&B+B-3W) | 2x | PP+1 |
资料来源:zartbot,西部证券研发中心
Table2|Comparisonofpipelinebubblesandmemoryusageacrossdifferent pipelineparallel methods.Fdenotestheexecutiontimeofaforwardchunk,Bdenotestheexecutiontimeofa fullbackwardchunkWdenotestheexecutiontimeofabackwardforweights”chunk,and& denotestheexecutiontimeof twomutuallyoverlappedforward andbackwardchunks.
资料来源:zartbot,西部证券研发中心
用户使用门槛降低:
软硬件一体化支持,提升推理效率。DeepSeek 首发支持国内昇腾平台(Ascend)和 MindIE 推理引擎,这种软硬件一体化的支持使得用户能够在不同的硬件环境中灵活高效地部署模型。特别是 MindIE 推理引擎通过通信加速、解码优化和量化压缩等核心技术,显著提升了推理效率和速度。在这种优化下,DeepSeek-V3 在复杂计算任务中的响应时间得到了大幅缩短,同时显著减少了计算资源的占用。
支持多种主流框架、全面开源策略。模型支持 SGLang、LMDeploy 和 TensorRT-LLM等多个主流框架,开发者可以根据自身需求选择合适的开发工具和框架。SGLang 在优化 FP8 精度和低延迟推理方面表现尤为突出,为高性能需求的企业提供了可靠的技术支持;而 LMDeploy 和 TensorRT-LLM 则通过灵活的离线和在线部署模式,扩展了模型的使用场景。此外,DeepSeek 通过开放模型权重和在 HuggingFace 平台上的部署,进一步支持了开发者进行本地化开发和定制化应用。
灵活的 API 定价模型,降低每百万 token 的处理成本。DeepSeek-V3 的 API 服务价格也极具吸引力,其价格区间从缓存命中时每百万输入 tokens 0.1 元到缓存未命中时的 1 元不等。
我们认为,DeepSeek-V3 的表现给前沿 LLM 训练降本带来新的解决路径和可能性,模型端使用成本的下降有助于推动商业端落地的闭环。
二、AI行业动态一览
2.1 国外行业动态
(1)AI大模型
【OpenBayes 倍式计算多模态模型落地】OpenBayes 推出了基于集群架构的多模态大模型服务,应用于遥感卫星遥控、医疗影像、法律文书翻译等多个场景。得益于多年的技术积累,其模型支持大规模数据的动态处理和分析,包括动态图像和动态视频。这种创新型服务已为国内多家企业和研究机构提供支持。此外,OpenBayes 因其高效计算集群与商用化潜力,被评为「大模型最具潜力创业企业 TOP 10」,显示出 AI 在商用化道路上的新方向。(来源:机器之心)
【Meta 探索大模型记忆层,扩展至 1280 亿参数,优于 MoE】Meta 推出了基于记忆层(Memory Layers)的全新语言模型架构,通过扩展参数数量至 1280 亿,显著提升了计算密集型任务中的性能。与传统的混合专家(MoE)模型相比,该记忆层采用稀疏激活策略,在保证计算效率的同时提升了模型的存储能力。通过训练的可查询机制,记忆层允许模型动态调取与任务相关的信息,从而提高推理的准确性。这项技术特别适用于深度神经网络的多层信息编码需求,并为大模型性能优化提供了新的方向。(来源:机器之心)
(2)应用
【Memory+: 记忆增强模型推动多场景任务扩展】Meta 的记忆增强模型(Memory+)在自然语言问答(QA)任务中表现卓越,尤其在扩展任务如 NQ(Natural Questions)和TQA(TriviaQA)中,其准确率随着记忆参数的增加而不断提升。在一个拥有 1280 亿记忆参数的模型中,Memory $^+$ 的性能接近 Llama 2 7B 模型,但所需的计算开销(FLOPs)大幅降低。该模型还展示了在多领域任务中,如信息检索、知识提取和生成任务中的广泛潜力,为复杂任务场景提供了高效解决方案。(来源:机器之心)
【记忆共享优化深度网络结构】Meta 研究进一步引入记忆共享机制,支持多个模型层共享记忆参数,以提升模型的通用性和节省存储资源。这种记忆共享策略通过层间关联性的优化,提升了大规模模型的参数效率,使其在处理超大规模任务(如知识图谱分析、文档摘要生成)时展现了更强的能力。(来源:机器之心)
2.2 国内行业动态
(1)AI大模型
【北大与港理工提出全新 LiNO 框架,突破时间序列预测瓶颈】北京大学与香港理工大学联合提出了 LiNO 框架(Linear and Nonlinear Decomposition Framework),采用递归残差分解(Recursive Residual Decomposition, RRD)技术,有效实现对时间序列数据中线性和非线性模式的显式提取。LiNO 框架在分离与预测时间序列数据的趋势(Trend)和季节性(Seasonal)变化上表现卓越,并结合自回归(AR)模型和 Transformer 编码器对非线性模式进行建模。通过灵活应用 Li 块(Linear Block)和 No 块(Nonlinear Block),LiNO 不仅能够提高预测结果的准确性,还展现了对时间序列复杂动态的强大解析能力。(来源:机器之心)
【CAD-GPT:推动 3D 建模智能化生成】上海交通大学 i-WIN 团队推出的 CAD-GPT 大模型在 3D 建模生成领域展示了卓越的性能。CAD-GPT 结合了多模态大语言模型和 3D建模空间定位机制,能够基于单张图片或一句描述实现高精度的 CAD 模型生成。在模型性能评估中,其准确性和生成质量全面超越传统方法(如 DeepCAD、GPT-4),展示了在工业设计与工程建模领域的巨大潜力。(来源:机器之心)
(2)应用
【LiNO 框架在多领域时间序列预测中表现出色】LiNO 框架在电力、交通、气象等多个实际应用领域展示了卓越的预测能力。在单变量时间序列预测任务中,LiNO 相较于现有方法显著降低了均方误差(MSE)和平均绝对误差(MAE),例如在 Weather 数据集上,MSE 下降了 $47.11%$ 。在多变量时间序列预测任务中,LiNO 在 ETT、ECL 等多个数据集上均表现出最优预测性能,全面超越传统方法和 Transformer 框架,进一步验证了其广泛的实用性和鲁棒性。(来源:机器之心)
【工业设计与 3D 建模的革新】CAD-GPT 在多模态输入条件下实现了精确的 3D 模型生成能力,适用于多种工业设计场景,包括 CAD 建模、工程设计和虚拟制造。其特有的 3D空间定位机制能够将复杂的 3D 草图角度和位置映射到语言描述中,显著提升了工业领域的自动化和智能化水平。(来源:机器之心)
三、AI行情回顾:A股整体下跌,美股液冷散热板块领涨
2024 年 12 月 30 日-2025 年 1 月 3 日,我们构建的西部 AI 股票池中,其中 75 家 A 股公司整体周平均跌幅 $12.1%$ ,60 家美股公司整体周平均涨幅 $1.27%$ 。A 股公司中,算力租赁,AI 应用和液冷散热板块上跌幅度最小,分别下跌 $9.6%$ 、 $10.3%$ 、 $10.3%$ 。美股公司中,液冷散热,高速 serdes 和存储芯片板块涨幅最大,分别上涨 $9.2%$ 、 $4.5%$ 、 $3%$ 。根据西部通信股票池,A 股市场中本周涨幅居前十的个股分别是共进股份( $(+6.2%)$ )、太辰光( $(+3.4%)$ )、寒武纪 $(-4.8%$ )、沪电股份 $(-4.9%)$ )、鹏鼎控股 $(.5.5%$ )、光云科技 $(-5.8%$ )、恒为科技( $-6.1%$ )、虹软科技( $(-6.7%)$ )、海康威视( $(-7.2%)$ )、云天励飞( $(-7.6%)$ )。美股市场中本周涨幅居前五的个股分别是Coherent( $+9.5%$ )、VERTIV( $+9.2%$ )、Snap( $+8.9%)$ )、BigBear.ai Holdings( $+7.6%$ )、Lumentum 控股( $+5.9%$ )。
西部证券2025 年 01 月 05 日资料来源:iFinD,西部证券研发中心资料来源:iFinD,西部证券研发中心
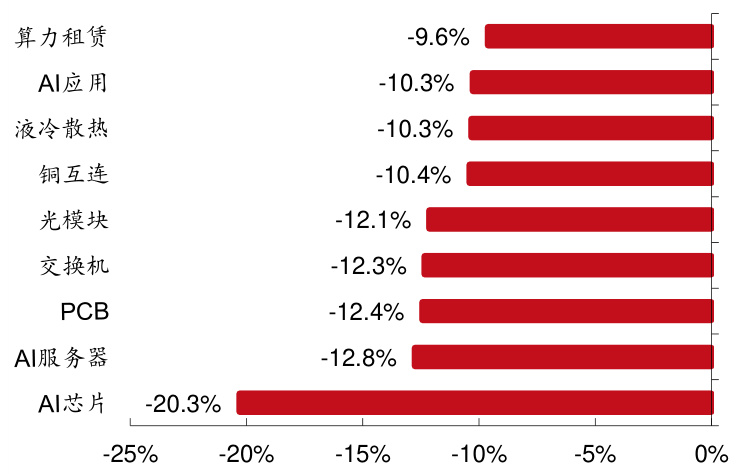
图 5:A 股 AI 行业细分板块周涨跌幅对比(12.30-01.03)
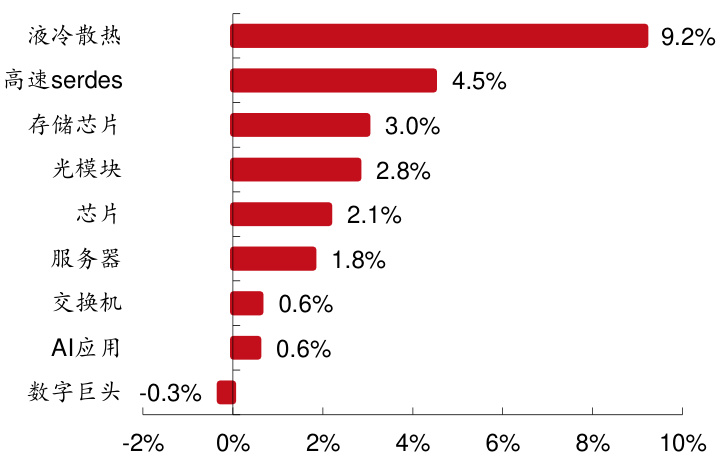
图 6:美股 AI 行业细分板块周涨跌幅对比(12.30-01.03)
四、投资建议:持续关注AI应用和算力基础设施
AIGC 和数字中国共振,算力托底。国内智算中心的加速部署,催化 AI 服务器、交换机、光模块、光芯片、温控设备等核心环节需求增长和技术加速升级。建议重点关注 AI 算力硬件,关注光模块(中际旭创、天孚通信、源杰科技等);散热领域(英维克)及 ICT 设备商等。
AI 应用的发展是影响 AI 板块估值的核心矛盾。AI 行业目前仍处在产业初期,整体处在行业曲线的上升阶段。在 AI 产业高速成长初期,投资逻辑上来看核心关注应用端增量需求的创造,投资节奏来看,前期是算力基础设施建设和大模型训练先行,后期重点关注应用持续强化带来机会。
五、风险提示
技术落地不及预期、硬件设备市场接受度不及预期、监管政策风险、中美贸易摩擦风险。
免责申明:
- 本资料来源于网络公开渠道,版权归属版权方;
- 本资料仅限会员学习使用,如他用请联系版权方;
- 会员费用作为信息收集整理及运营之必须费用;
- 如侵犯您的合法权益,请联系客服微信将及时删除
行业报告资源群
- 进群福利:进群即领万份行业研究、管理方案及其他学
习资源,直接打包下载 - 每日分享:6份行研精选报告、3个行业主题
- 报告查找:群里直接咨询,免费协助查找
- 严禁广告:仅限行业报告交流,禁止一切无关信息

微信扫码,长期有效
知识星球 行业与管理资源
专业知识社群:每月分享8000+份行业研究报告、商业计划、市场研究、企业运营及咨询管理方案等,涵盖科技、金融、教育、互联网、房地产、生物制药、医疗健康等;已成为投资、产业研究、企业运营、价值传播等工作助手。

西部证券—投资评级说明
| 行业评级 | 超配: | 行业预期未来6-12个月内的涨幅超过市场基准指数10%以上 |
| 中配: | 行业预期未来6-12个月内的波动幅度介于市场基准指数-10%到10%之间 | |
| 低配: | 行业预期未来6-12个月内的跌幅超过市场基准指数10%以上 | |
| 公司评级 | 买入: | 公司未来6-12个月的投资收益率领先市场基准指数20%以上 |
| 增持: | 公司未来6-12个月的投资收益率领先市场基准指数5%到20%之间 | |
| 中性: | 公司未来6-12个月的投资收益率与市场基准指数变动幅度相差-5%到5% | |
| 卖出: | 公司未来6-12个月的投资收益率落后市场基准指数大于5% |
报告中所涉及的投资评级采用相对评级体系,基于报告发布日后 6-12 个月内公司股价(或行业指数)相对同期当地市场基准指数的市场表现预期。其中,A 股市场以沪深 300 指数为基准;香港市场以恒生指数为基准;美国市场以标普 500 指数为基准。
分析师声明
本人具有中国证券业协会授予的证券投资咨询执业资格并注册为证券分析师,以勤勉的职业态度、专业审慎的研究方法,使用合法合规的信息,独立、客观地出具本报告。本报告清晰准确地反映了本人的研究观点。本人不曾因,不因,也将不会因本报告中的具体推荐意见或观点而直接或间接收到任何形式的补偿。
联系地址
联系地址: 上海市浦东新区耀体路 276 号 12 层北京市西城区丰盛胡同 28 号太平洋保险大厦 513 室深圳市福田区深南大道 6008 号深圳特区报业大厦 10C
联系电话: 021-38584209
免责声明
本报告由西部证券股份有限公司(已具备中国证监会批复的证券投资咨询业务资格)制作。本报告仅供西部证券股份有限公司(以下简称“本公司”)机构客户使用。本报告在未经本公司公开披露或者同意披露前,系本公司机密材料,如非收件人(或收到的电子邮件含错误信息),请立即通知发件人,及时删除该邮件及所附报告并予以保密。发送本报告的电子邮件可能含有保密信息、版权专有信息或私人信息,未经授权者请勿针对邮件内容进行任何更改或以任何方式传播、复制、转发或以其他任何形式使用,发件人保留与该邮件相关的一切权利。同时本公司无法保证互联网传送本报告的及时、安全、无遗漏、无错误或无病毒,敬请谅解。
本报告基于已公开的信息编制,但本公司对该等信息的真实性、准确性及完整性不作任何保证。本报告所载的意见、评估及预测仅为本报告出具日的观点和判断,该等意见、评估及预测在出具日外无需通知即可随时更改。在不同时期,本公司可能会发出与本报告所载意见、评估及预测不一致的研究报告。同时,本报告所指的证券或投资标的的价格、价值及投资收入可能会波动。本公司不保证本报告所含信息保持在最新状态。对于本公司其他专业人士(包括但不限于销售人员、交易人员)根据不同假设、研究方法、即时动态信息及市场表现,发表的与本报告不一致的分析评论或交易观点,本公司没有义务向本报告所有接收者进行更新。本公司对本报告所含信息可在不发出通知的情形下做出修改,投资者应当自行关注相应的更新或修改。
本公司力求报告内容客观、公正,但本报告所载的观点、结论和建议仅供投资者参考之用,并非作为购买或出售证券或其他投资标的的邀请或保证。客户不应以本报告取代其独立判断或根据本报告做出决策。该等观点、建议并未考虑到获取本报告人员的具体投资目的、财务状况以及特定需求,在任何时候均不构成对客户私人投资建议。投资者应当充分考虑自身特定状况,并完整理解和使用本报告内容,不应视本报告为做出投资决策的唯一因素,必要时应就法律、商业、财务、税收等方面咨询专业财务顾问的意见。本公司以往相关研究报告预测与分析的准确,不预示与担保本报告及本公司今后相关研究报告的表现。对依据或者使用本报告及本公司其他相关研究报告所造成的一切后果,本公司及作者不承担任何法律责任。
在法律许可的情况下,本公司可能与本报告中提及公司正在建立或争取建立业务关系或服务关系。因此,投资者应当考虑到本公司及/或其相关人员可能存在影响本报告观点客观性的潜在利益冲突。对于本报告可能附带的其它网站地址或超级链接,本公司不对其内容负责,链接内容不构成本报告的任何部分,仅为方便客户查阅所用,浏览这些网站可能产生的费用和风险由使用者自行承担。
本公司关于本报告的提示(包括但不限于本公司工作人员通过电话、短信、邮件、微信、微博、博客、QQ、视频网站、百度官方贴吧、论坛、BBS)仅为研究观点的简要沟通,投资者对本报告的参考使用须以本报告的完整版本为准。
本报告版权仅为本公司所有。未经本公司书面许可,任何机构或个人不得以翻版、复制、发表、引用或再次分发他人等任何形式侵犯本公司版权。如征得本公司同意进行引用、刊发的,需在允许的范围内使用,并注明出处为“西部证券研究发展中心”,且不得对本报告进行任何有悖原意的引用、删节和修改。如未经西部证券授权,私自转载或者转发本报告,所引起的一切后果及法律责任由私自转载或转发者承担。本公司保留追究相关责任的权力。所有本报告中使用的商标、服务标记及标记均为本公司的商标、服务标记及标记。
本公司具有中国证监会核准的“证券投资咨询”业务资格,经营许可证编号为:91610000719782242D。
文章作者 大模型
上次更新 2025-03-09