【关键模块】让你的推荐系统反应更快:实时推荐
文章目录
更快,更高,更强,不只是奥林匹克运动所追求的,也是推荐系统从业者所追求的三个要素:捕捉兴趣要更快,指标要更高,系统要更健壮。
我今天就要说的就是这个“更快”。推荐系统是为了在用户和物品之间建立连接,手段是利用已有的用户物品之间的连接,然而任何事物都是有生命周期的,包括这里说的这个虚无的“连接”也是有的。
为什么要实时
一个连接从建立开始,其连接的强度就开始衰减,直到最后,可能用户不记得自己和那个物品曾经交汇过眼神。因此,推荐系统既然使用已有的连接去预测未来的连接,那么追求“更快”就成了理所当然的事情。
用户和物品之间产生的连接,不论轻如点击,还是重如购买,都有推荐的黄金时间。在这个黄金时间,捕捉到用户的兴趣并且给与响应,可能就更容易留住用户。
在业界,大家为了高大上,不会说“更快”的推荐系统,而是会说“实时”推荐系统。实际上,绝对的实时是不存在的,哪怕延迟级别在微秒的推荐,也是会有延迟的。但是为了顺应时代潮流,我还是会在后面的内容中说这是实时推荐,你就那么一听,知道就好。
关于到底什么是实时推荐,实际上有三个层次。
- 第一层,“给得及时”,也就是服务的实时响应。这个是最基本的要求,一旦一个推荐系统上线后,在互联网的场景下,没有让用户等个一天一夜的情况,基本上最慢的服务接口整个下来响应时间也超过秒级。达到第一层不能成为实时推荐,但是没达到就是不合格。
- 第二层,“用得及时”,就是特征的实时更新。例如用户刚刚购买了一个新的商品,这个行为事件,立即更新到用户历史行为中,参与到下一次协同过滤推荐结果的召回中。做到这个层次,已经有实时推荐的意思了,常见的效果就是在经过几轮交互之后,用户的首页推荐会有所变化。这一层次的操作影响范围只是当前用户。
- 第三层,“改得及时”,就是模型的实时更新。还是刚才这个例子,用户刚刚购买了一个新的商品,那需要实时地去更新这个商品和所有该用户购买的其他商品之间的相似度,因为这些商品对应的共同购买用户数增加了,商品相似度就是一种推荐模型,所以它的改变影响的是全局推荐。
实时推荐
好,下面就讲一下如何构建一个处在第三层次的实时推荐系统。
1. 架构概览
按照前面的分析,一个处在第三层次的实时推荐,需要满足三个条件:
- 数据实时进来
- 数据实时计算
- 结果实时更新
为此,下面给出一个基本的实时推荐框图。
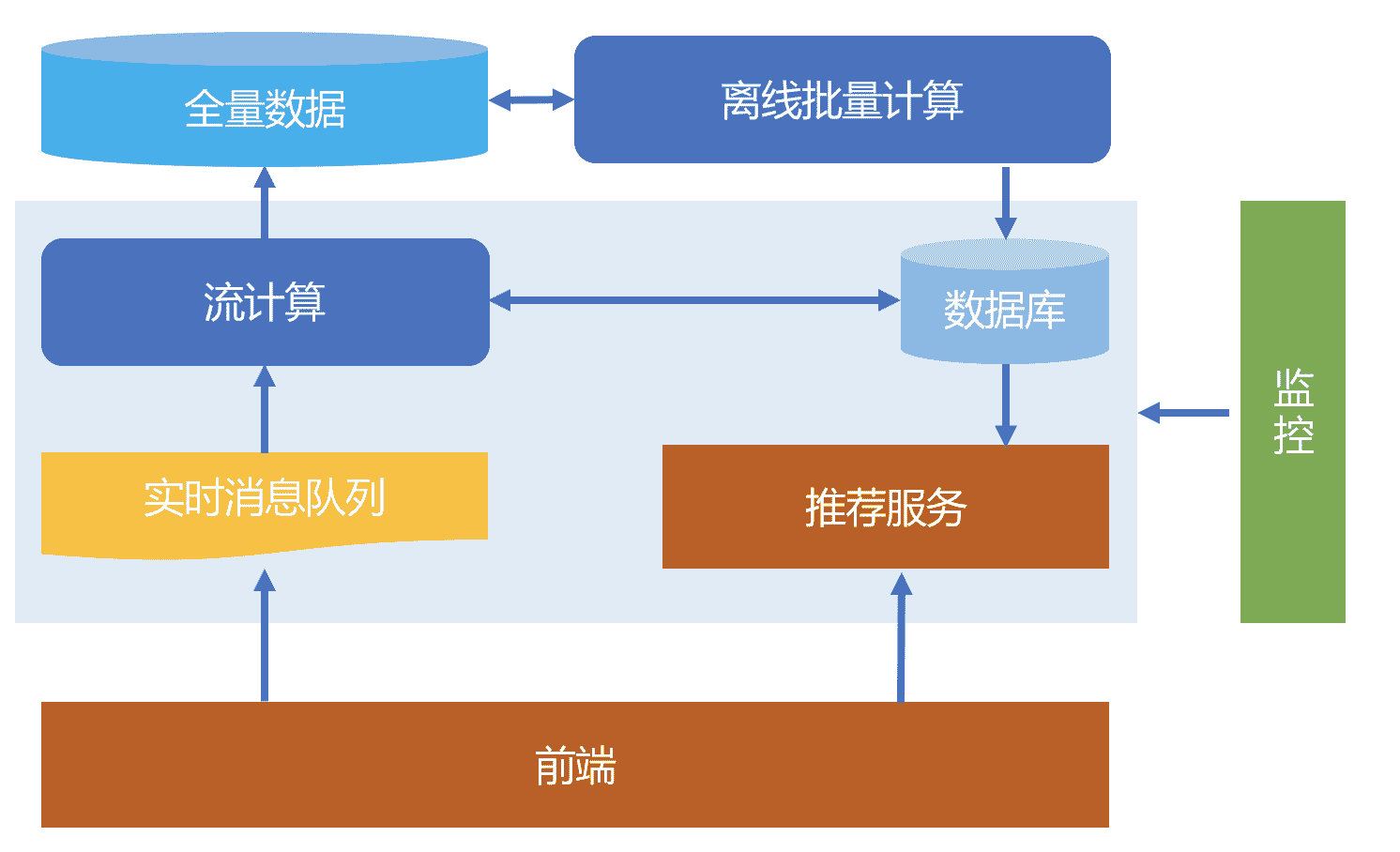
整体介绍一下这个图,前端服务负责和用户之间直接交互,不论是采集用户行为数据,还是给出推荐服务返回结果。
用户行为数据经过实时的消息队列发布,然后由一个流计算平台消费这些实时数据,一方面清洗后直接入库,另一方面就是参与到实时推荐中,并将实时计算的结果更新到推荐数据库,供推荐服务实时使用。
2. 实时数据
实时流数据的接入,在上一篇专栏中已经讲到过,需要一个实时的消息队列,开源解决方案 Kafka 已经是非常成熟的选项。
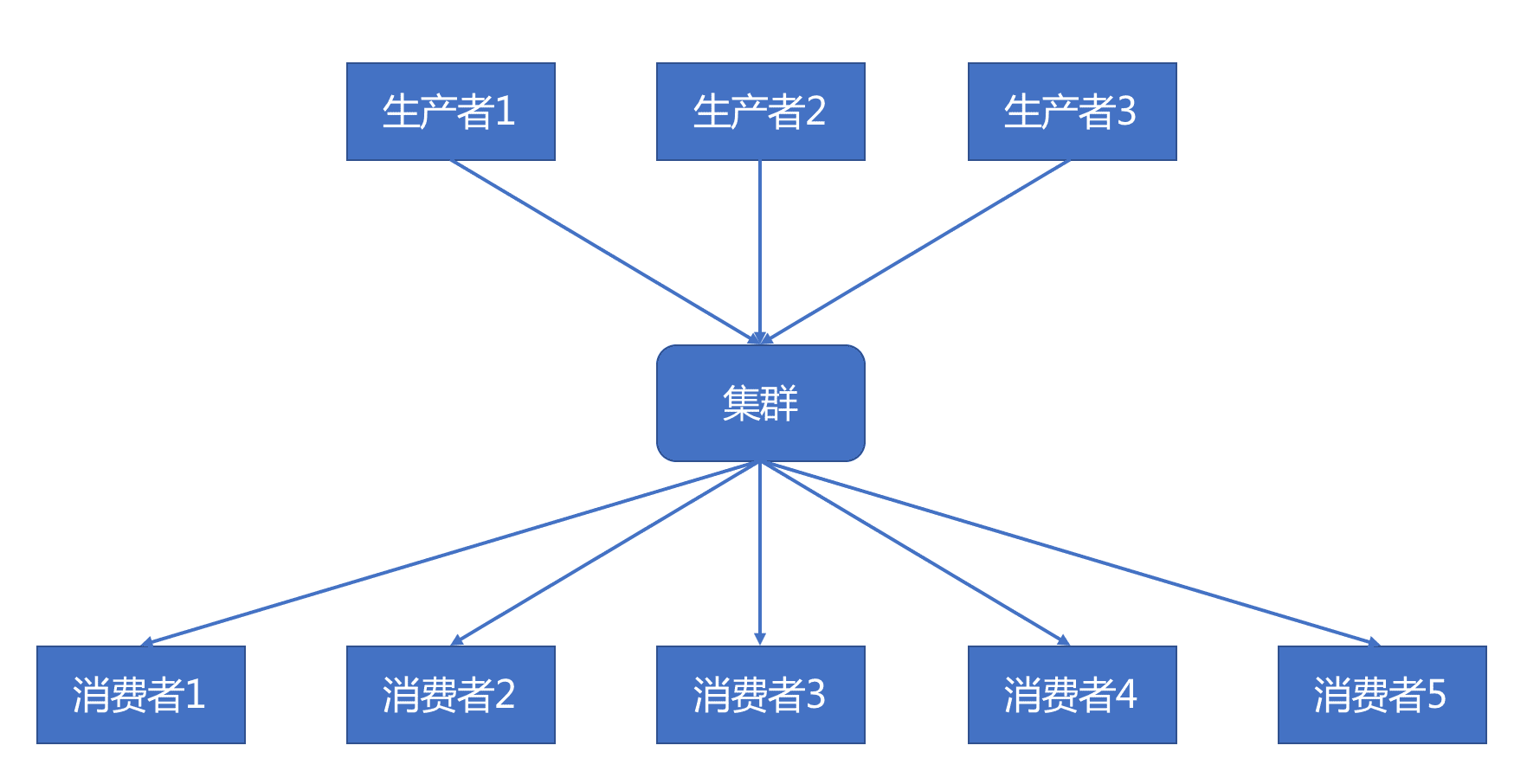
Kafka 以生产者消费者的模式吞吐数据,这些数据以主题的方式组织在一起,每一个主题的数据会被分为多块,消费者各自去消费,互不影响,Kafka 也不会因为某个消费者消费了而删除数据。
每一个消费者各自保存状态信息:所消费数据在 Kafka 某个主题某个分块下的偏移位置。也因此任意时刻、任意消费者,只要自己愿意,可以从 Kafka 任意位置开始消费数据,一遍消费,对应的偏移量顺序往前移动。示意图如下。

一个生产者可以看做一个数据源,生产者决定数据源放进哪个主题中,甚至通过一些算法决定数据如何落进哪个分块里。示意图如下:
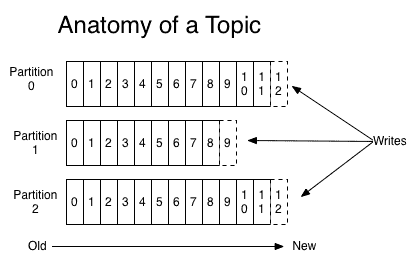
因此,Kafka 的生产者和消费者在自己的项目中实现时都非常简单,就是往某个主题写数据,以及从某个主题读数据。
3. 流计算
整个实时推荐建立在流计算平台上。常见的流计算平台有 Twitter 开源的 Storm,“Yahoo!”开源的 S4,还有 Spark 中的 Streaming。
不过随着 Storm 使用者越来越多,社区越来越繁荣,并且相比 Streaming 的 MiniBatch 模式,Storm 才是真正的流计算。因此,在你构建自己的实时推荐时,流计算平台不妨就选用 Storm,不过最新的流计算框架 FLink 表现强劲,高吞吐低延迟,如果你所在团队有人愿意尝试一下也很不错。
Storm 是一个流计算框架,它有以下几个元素。
- Spout,意思是喷嘴,水龙头,接入一个数据流,然后以喷嘴的形式把数据喷洒出去。
- Bolt,意思是螺栓,像是两段水管的连接处,两端可以接入喷嘴,也可以接入另一个螺栓,数据流就进入了下一个处理环节。
- Tuple,意思是元组,就是流在水管中的水。
- Topology,意思是拓扑结构,螺栓和喷嘴,以及之间的数据水管,一起组成了一个有向无环图,这就是一个拓扑结构。
注意,Storm 规定了这些基本的元素,也是你在 Storm 平台上编程时需要实现的,但不用关心水管在哪,水管由 Storm 提供,你只用实现自己需要的水龙头和水管连接的螺栓即可。
因此,其编程模型也非常简单。举一个简单的例子,看看如何用 Storm 实现流计算?假如有一个字符串构成的数据流,这个数据流恰好也是 Kafka 中的一个主题,正在源源不断地在接入。
要用 Storm 实现一个流计算统计每一个字符的频率。你首先需要实现一个 Spout,也就是给数据流加装一个水龙头,这个水龙头那一端就是一个 Kafka 的消费者,从 Kafka 中不断取出字符串数据,这头就喷出来,然后再实现 Bolt,也就是螺栓。
当有字符串数据流进来时,把他们拆成不同的字符,并以(字符,1)这样的方式变成新的数据流发射出去,最后就是去把相同字符的数据流聚合起来,相加就得到了字符的频率。
实际上,如果你知道 MapReduce 过程的话,你会发现虽然 Storm 重新取了名字,仍然可以按照 MapReduce 来理解。
Storm 的模型示意如下:

Storm 中要运行实时推荐系统的所有计算和统计任务,比如有下面几种:
- 清洗数据;
- 合并用户的历史行为;
- 重新更新物品相似度;
- 在线更新机器学习模型;
- 更新推荐结果。
4. 算法实时化
我在前面的文章里面,已经介绍过基于物品的协同过滤原理。下面我以基于物品的协同过滤算法为主线,来讲解一下如何实现实时推荐,其他算法你可以举一反三改造。
主要是两个计算,第一个是计算物品之间的相似度。
sim(i,j)=cousers(itemi,itemj)countusers(itemi)−−−−−−−−−−−−−−−√countusers(itemj)−−−−−−−−−−−−−−−√sim(i,j)=cousers(itemi,itemj)countusers(itemi)countusers(itemj)
文章作者 anonymous
上次更新 2024-02-22