FireShot_Capture_075_用几个案例来讲解程序化SEO生成海量页面获取流量的方式
文章目录
帖子经验教程 资源标签群聊 我的帖子 b
〉教程〉哥飞小课堂〉用几个案例来讲解程序化SEO生成海量页面获取流量的方式

用几个案例来讲解程序化SEO生成海量页面获取流量的方
式 朋友们,今天的#哥飞小课堂来得有点早
海量页面
一会儿10点给大家讲课,用几个案例来讲解程序化SEO生成海量页面获取流量的方式。
时间到,今天的#哥飞下课堂开始了。
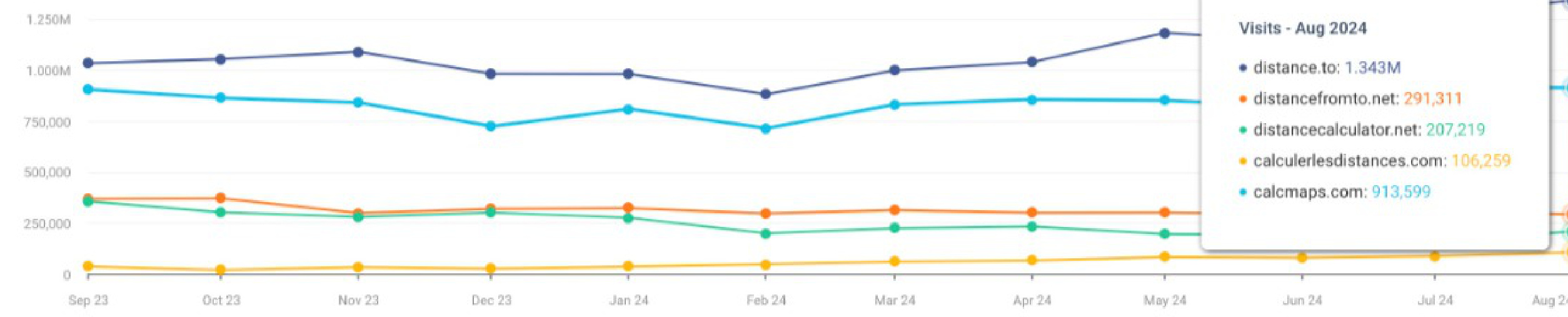
12.97M 3.776M 2.923M 672,226 10.04M先看流量,Similarweb上面几个网站的最近12个月访问量,最大的distance.to访问量1297万。
这些网站解决的需求是什么呢?
其实是特别小的一个需求,甲地到乙地的距离是多少。
如阿塞拜疆到德国距离是多少。
Distance from Azerbaijan to Germany
这样两个地点,两两组合,就会有N多问题。
仅仅从国家层面,全球二百多个国家,就有四万多个问题了。再到省市区不同级别地区,各自两两组合,几百万个问题都有了
Google Distancefron
| Q | distancefromgermanytousa |
| distancefromearthtomoon distancefromearthtosun | |
| distancefromearthtomars | |
| distancefromoneplacetoanother | |
| distancefromalaskatorussia | |
| distancefromdartboard | |
| distancefromto | |
| distancefrommoundtohomeplate |
甚至离开地球,在宇宙尺度,也是有人会问问题的。
Google distancefromgermanyto| distance from germany to usa distance from germany to japan distancefrom germany to othercountries distance from germany to switzerland by tra distance from germany to hawaii distance from germany to us distance from germany tovietnam distance from germany to philippines distancefrom germanytomoscow distance from germany to prague
每一个地区,到另一个地区,都会有人好奇,距离是多少。
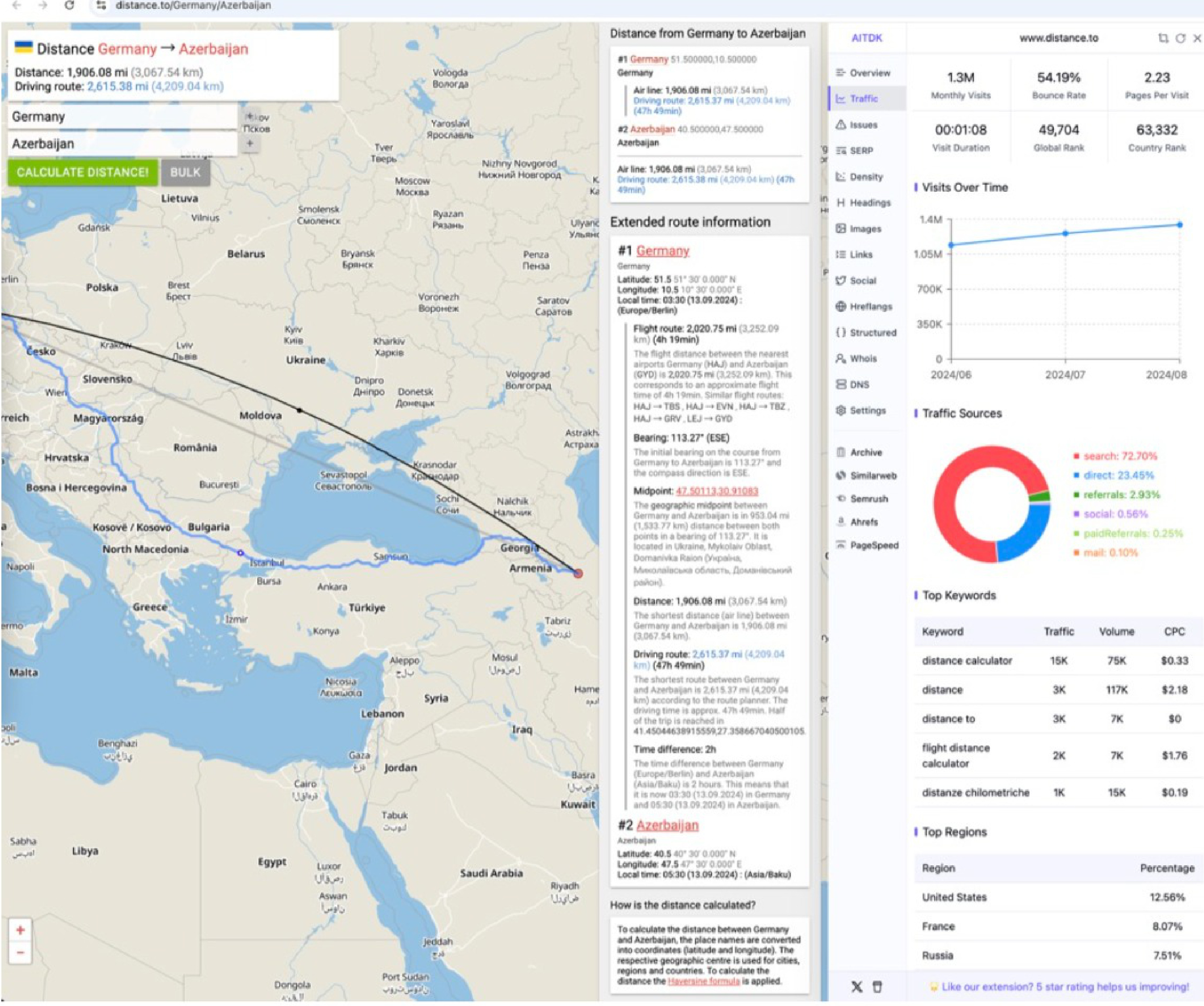
我们拿distance.to这个网站来说,看上图,页面很好做,主体部分是地图,标记一下两个地区,连上线,再在地图上方浮层显示一些文字信息,整个页面就做好了。
https://www.distance.to/Germany/Azerbaijan
70 site:distance.to AlI
Calcolatore di distanza Distanzachilometrica-Calcolatore didistanza
Afstandscalculator Afstandscalculator-bereken deafstand online! De populaireafstandscalculatorberekent afstandeninkilometerstussen allelocatiesencoordinaten,n biedt routeplannersinteractievekaartenen… Distance calculator Calculator distanta-Calculeaza distanta online! Calculatorulpopularpentru distanta calculeazadistanteleinkilometri intreoricelocurisicoordonate, oferind planificatoare pentru rute,
注意,并不是说这个网站服务器里有129万个html文件。这样的页面,都是统一的模板页面,只需要从数据库里取出地理位置数据,计算一下距离,然后把数据填充到
it.distance.to
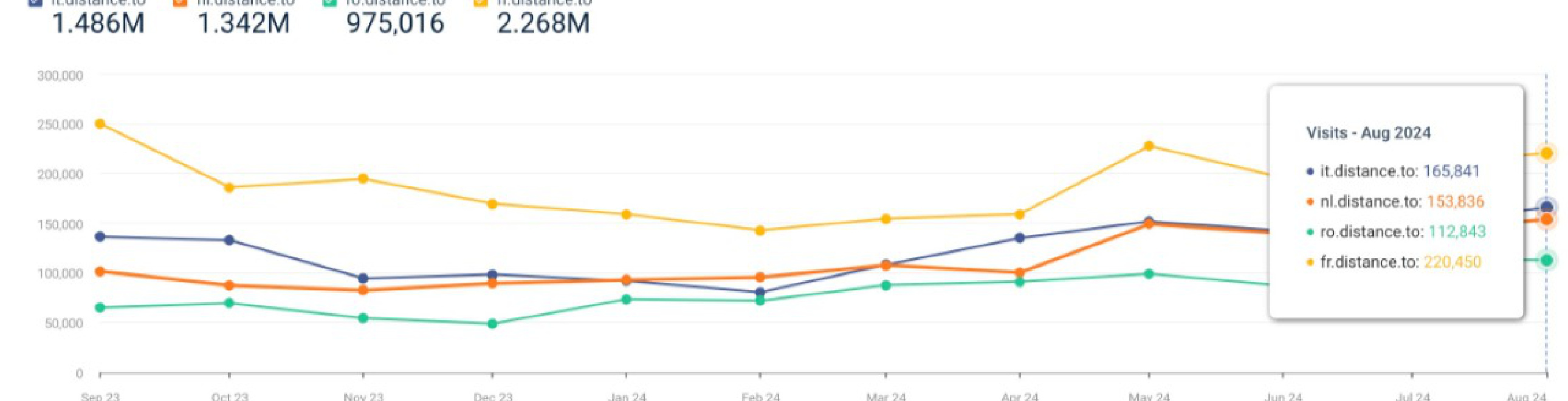
从前面的site结果看到,这个网站还做了多语言支持,并且用的是子域名的方式实现的。我们之前提到的多语言方式都是用子目录来实现的。两种方法都可以,但是哥飞建议,你一个新网站刚上线时,最好用子目录方式来实现,这样冷启动的成
如使是canva这样的大站,也是用的子目录形式实现的多语言。 https://www.canva.com/ai-image-generator/ https://www.canva.com/ja_jp/ai-image-generator/ https://www.canva.com/fr_fr/generateur-image-ia/
两个地点之间,其实有很多需求,距离只是其中一个特别小的需求,但是你盯住这个这么小的需求,也能做出百万月访问量的网站。
原因就是这类需求都可以做出海量页面。
所以不要因为我们今天分享了distance.to,就觉得子域名形式更好。
虽然每一个页面可能每一天只有几个几十个访问量,但是所有页面加起来,访问量就多了。
两地之间,更值钱的需求是交通,飞机、公路、轮船、铁路等等各种交通方式,直接卖票就是旅游网站的赚方式之一。
不知道大家发现没有,今天分享的distance.to生成页面的方式,跟之前大家理解的海量页面方式还不太一
样。
尤其是有了A的加持后,大家以为的海量页面生成方式,就是让AI去回答海量的问题。
只需要你的数据库里有结构化的数据,就可以做成各种各样的模板,生成各种各样的页面每一个页面都是盯着某一个真的会有人搜索的需求去创建的。
阿彪-谈谈海量SEO页面以及最近的一些收获https://new.web.cafe/tutorial/detail/82ea980d818446bfbee3daea735126e完今天的小课堂,现在大家再去听彪哥讲的海量页面SEO经验,可能就会更能听得懂,更有收获了。
彪哥在演讲中给我们分享了一个找人找公司的网站,里边就有大量的页面,从人的维度,从公司的维度,从地点的维度,都能够生成海量页面。
是因为有人会这样搜索,所以才去生成相关的页面,期望我们的网页能够出现在真实用户搜索结果里,从而获得访问量。
之前有一次小课堂,哥飞分享的growjo.com,也是这类网好,既然数据这么重要,那么数据怎么来呢?当然是从互联网中来
但是,没有哪个地方刚好就有你需要的一模一样的数据。所以一般都是你自己先分析好需求,规划好数据结构,然后按照需要,去找哪里可能有相关数据,你用爬虫
抓取,然后解析维结构化数据。
不过,这里注意一下,非公开数据,有版权数据,不要去抓取。
有时候一个地方不会有你需要的全部数据,你还需要去多个地方抓取,最后整合数据。
一般,如果我们去外部分享,提到了海量页面,一定会有人杠,你这不是垃圾网站吗的回答是,只要能够帮助一部分人群解决某些特定需求,就不是垃圾网站。
他们会这么说,只是因为这个网站不是他的。
吃不到的葡萄,都说是酸的。谷歌有一个反垃圾机制,你不提供价值的网站,很难获取到流量了。
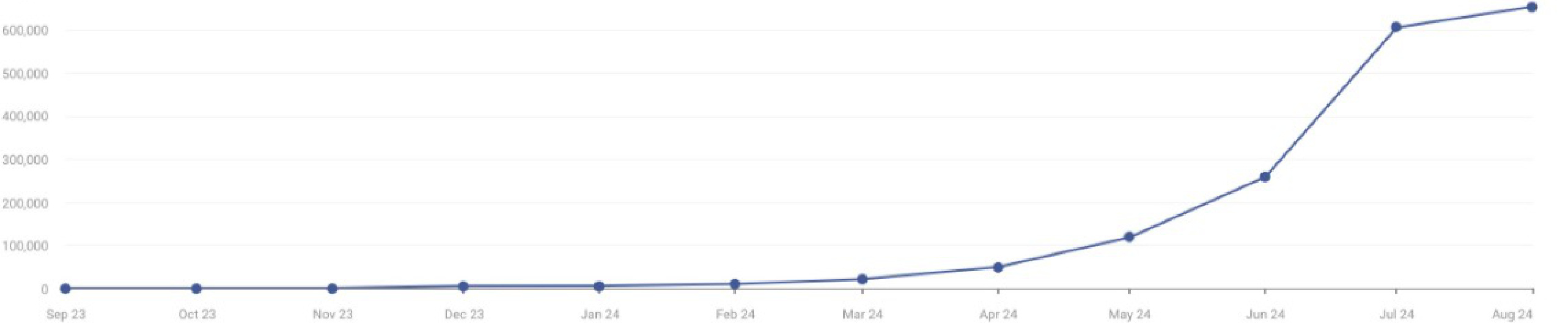
能够拿到流量的网站,尤其是拿到大流量的网站,一定是能够给一部分人群提供价值的。之前6月北京线下聚会时,Henry分享了他的网站的案例,首页瞄准有一定优化难度的大搜索量关键词,然后通过二级页面和大量的三级页面,不断的获取小词的排名、曝光、点击,进而带动了上一级页面的权重,最后让首页拿到了相关关键词的排名。
上面这条流量增长曲线就说明了,这个内容策略是有效的。
所以你的网站需要做好内链,从首页到二级页面,二级页面到三级页面,一层一层展开,让爬虫能够抓取到每一个页面。
怎么让搜索引擎爬虫能够爬取到你的海量页面,可以看看这篇文章:【哥飞SEO教程】如何制作出S的网页?先从学习谷歌是如何理解我们网页开始
还有个问题,大家很关心,现在还可以做这样的网站吗?那么你就要去挖掘相关需求了,而不是仅仅盯着哥飞今天分享的两地距离这个需求去做。重要的是学会这种建站思路,然后再去挖掘可以用这个建站思路做站的需求。
今天的小课堂内容就到这里了,下面是提问环节。
群友问1:飞哥,数据填充到模板里,每次用户访问时动态渲染出来的这个页面是真实的页面么,它和提前创建出来页面相比有啥优势么
哥飞答1:这就是我们常说的后端渲染,你如果真的生成了129万个html文件,一是海量小文件不好管理,二是万一你要修改页面里的某个地方,就会很麻烦。
群友问2:飞哥,有个疑问,我们把数据放到数据库中,生成页面,搜索引擎如何知道这些页面的url呢?哥飞答2:所以你的网站需要做好内链,从首页到二级页面,二级页面到三级页面,一层一层展开,让爬虫能够抓取到每一个页面。
群友问3:飞哥,如果我们内链做得好,提前被搜索引擎爬取了,这样意味着用户搜索之前这个页面已经被生成了吧?
哥飞答3:每一次都是临时生成的,动态生成的,生成完成后就返回给前端了,并没有存储为html文件。通常来说,每一个请求来了,就生成一次。但是一旦流量大了之后,这样对数据库的压力就大了。所以一般会设置缓存,如缓存10分钟,那么这10分钟内,不管有多少请求,实际你的数据库只被查询了一次。
群友问4:那针对于这个朋友的问题,这些临时生成的网页在用户搜索、点击之前是没有的(超过十分钟的话),但是URL却可以显示在搜索结果落地页?
哥飞答4:是的,你只是对外给出了一个指针。
群友问5:就是说先做好内链、被搜索引擎收URL、最后生成页面,这个顺序对吗哥飞答5:没有顺序,都是实时的,同步的。搜索引擎看到了你的某个URL,之后去请求这个URL,你的就会生成html返回给爬虫。
哥飞答6:让用户能够从首页开始,访问到你网站的每一个页面让爬虫能够从首页开始,访问到你网站的每一个页面。
让用户能够从任荷 个贝面打并你的网站,都能够到达上 级贝面,以及到达网站的真他重要贝面,特别是首页。让爬虫能够从任何一个页面打开你的网站,都能够到达上一级页面,以及到达网站的其他重要页面,特别是首群友问7:这种海量页面的话,新站的话,一天上多少个页面合适。
飞答7:每一个站情况都不同,一般来讲,前期少量测试,每天10个页面,看看爬虫是否能够全部抓取了之后是否会出词
这一步目的是测试你的模板页面SEO做得到底好不好。根据GSC后台反馈的数据,不断调整页面。直到你给出的页面,谷歌爬虫都能够抓取,并且都出词了,那就说明你的页面调整得差不多了。接下来,就可以增大生成页面的数量,每天100个看看谷歌爬虫是否吃得下。如果也是能吃下去,并且也有出词,那就改成每天200个,300个,500个,1000个。
群友问8:判断一个页面需不需要生成,数据来源和依据一般是什么?是不是当前站点的搜索后台的搜索情况,或者按照以前的搜索意图去分析哥飞答8:刚才课堂里其实已经讲了,因为有人会在搜索引擎搜索相关关键词,我们才去做相关的页面。
群友问9:Google会有一个网页内容的重复度吗?比如只换一些结构化词,大部分描述都一致哥飞答9:你说大部分描述一致,那就避免就好了,为什么要做成大部分描述一致呢。
群友问10:提问,canva这种超级细的关键词怎么挖掘的?感觉自己做关键词挖掘,similarweb难以达到他的颗粒度,太细致了。因为有很多不相关的词干扰
哥飞答10:机器+人工,他们已经跑通了这个模式,每一个词对于他们来说都是钱,所以可以花更高的成本去做这个事情。
好了,以上就是今天这篇文章的主要内容了,包含了哥飞在小课堂分享的内容,课后的问答环节的问题和回答。
相信大家看完之后,对于海量页面SEO会有更清晰的了解。
上一篇:如何通过正在投广告的产品帮助我们发现需求,下一篇:一句话告诉大家,游戏站怎么找新词新游戏
分析需求价值
评论区
回复
Web.Cafe 法律条款
文章作者 独立站运营从SEO到Adsense攻略
上次更新 2025-03-09