12|树的深度优先搜索(下):如何才能高效率地查字典?
文章目录
你好,我是黄申。今天咱们继续聊前缀树。
上节结尾我给你留了道思考题:如何实现前缀树的构建和查询?如果你动手尝试之后,你会发现,这个案例的实现没有我们前面讲的那些排列组合这么直观。
这是因为,从数学的思想,到最终的编程实现,其实需要一个比较长的流程。我们首先需要把问题转化成数学中的模型,然后使用数据结构和算法来刻画数学模型,最终才能落实到编码。
而在前缀树中,我们需要同时涉及树的结构、树的动态构建和深度优先搜索,这个实现过程相对比较复杂。所以,这节我就给你仔细讲解一下,这个实现过程中需要注意的点。只要掌握这些点,你就能轻而易举实现深度优先搜索。
如何使用数据结构表达树?
首先,我想问你一个问题,什么样的数据结构可以表示树?
我们知道,计算机中最基本的数据结构是数组和链表。数组适合快速地随机访问。不过,数组并不适合稀疏的数列或者矩阵,而且数组中元素的插入和删除操作也比较低效。相对于数组,链表的随机访问的效率更低,但是它的优势是,不必事先规定数据的数量,表示稀疏的数列或矩阵时,可以更有效地利用存储空间,同时也利于数据的动态插入和删除。
我们再来看树的特点。树的结点及其之间的边,和链表中的结点和链接在本质上是一样的,因此,我们可以模仿链表的结构,用编程语言中的指针或对象引用来构建树。
除此之外,我们其实还可以用二维数组。用数组的行或列元素表示树中的结点,而行和列共同确定了两个树结点之间是不是存在边。可是在树中,这种二维关系通常是非常稀疏的、非常动态的,所以用数组效率就比较低下。
基于上面这些考虑,我们可以设计一个 TreeNode 类,表示有向树的结点和边。这个类需要体现前缀树结点最重要的两个属性。
- 这个结点所代表的字符,要用 label 变量表示。
- 这个结点有哪些子结点,要用 sons 哈希映射表示。之所以用哈希,是为了便于查找某个子结点(或者说对应的字符)是否存在。
另外,我们还可以用变量 prefix 表示当前结点之前的前缀,用变量 explanation 表示某个单词的解释。和之前一样,为了代码的简洁,所有属性都用了 public,避免读取和设置类属性的代码。
这里我写了一段 TreeNode 类的代码,来表示前缀树的结点和边,你可以看看。
|
|
说到这里,你可能会好奇,为什么只有结点的定义,而没有边的定义呢?实际上,这里的有向边表达的是父子结点之间的关系,我把这种关系用 sons 变量来存储父结点。
需要注意的是,我们需要动态地构建这棵树。每当接收一个新单词时,代码都需要扫描这个单词的每个字母,并使用当前的前缀树进行匹配。如果匹配到某个结点,发现相应的字母结点并不存在,那么就建立一个新的树结点。这个过程不好理解,我也写了几行代码,你可以结合来看。其中,str 表示还未处理的字符串,parent 表示父结点。
|
|
如何使用递归和栈实现深度优先搜索?
构建好了数据结构,我们现在需要考虑,什么样的编程方式可以实现对树结点和边的操作?
仔细观察前缀树构建和查询,你会发现这两个不断重复迭代的过程,都可以使用递归编程来实现。换句话说,深度优先搜索的过程和递归调用在逻辑上是一致的。
我们可以把函数的嵌套调用,看作访问下一个连通的结点;把函数的返回,看作没有更多新的结点需要访问,回溯到上一个结点。在之前的案例中,我已经讲过很多次递归编程的例子,这里我就不列举代码细节了。如果忘记的话,你可以回去前面章节复习一下。
在查询的过程中,至少有三种情况是无法在字典里找到被查的单词的。于是,我们需要在递归的代码中做相应的处理。
第一种情况:被查单词所有字母都被处理完毕,但是我们仍然无法在字典里找到相应的词条。
每次递归调用的函数开始,我们都需要判断待查询的单词,看看是否还有字母需要处理。如果没有更多的字母需要匹配了,那么再确认一下当前匹配到的结点本身是不是一个单词。如果是,就返回相应的单词解释,否则就返回查找失败。对于结点是不是一个单词,你可以使用 Node 类中的 explanation 变量来进行标识和判断,如果不是一个存在的单词,这个变量应该是空串或者 Null 值。
第二种情况:搜索到前缀树的叶子结点,但是被查单词仍有未处理的字母,就返回查找失败。
我们可以通过结点对象的 sons 变量来判断这个结点是不是叶子结点。如果是叶子结点,这个变量应该是空的 HashMap,或者 Null 值。
第三种情况:搜索到中途,还没到达叶子结点,被查单词也有尚未处理的字母,但是当前被处理的字母已经无法和结点上的 label 匹配,返回查找失败。是不是叶子仍然通过结点对象的 sons 变量来判断。
好了,现在你已经可以很方便地在字典里查找某个单词,看看它是否存在,或者看看它的解释是什么。我这里又有一个新的问题了:如果我想遍历整个字典中所有的单词,那该怎么办呢?
仔细观察一下,你应该能发现,查找一个单词的过程,其实就是在有向树中,找一条从树的根到代表这个单词的结点之通路。那么如果要遍历所有的单词,就意味着我们要找出从根到所有代表单词的结点之通路。所以,在每个结点上,我们不再是和某个待查询单词中的字符进行比较,而是要遍历该结点所有的子结点,这样才能找到所有可能的通路。我们还可以用递归来实现这一过程。
尽管函数递归调用非常直观,可是也有它自身的弱点。函数的每次嵌套,都可能产生新的变量来保存中间结果,这可能会消耗大量的内存。所以这里我们可以用一个更节省内存的数据结构,栈(Stack)。
栈的特点是先进后出(First In Last Out),也就是,最先进入栈的元素最后才会得到处理。我画了一张元素入栈和出栈的过程图,你可以看看。
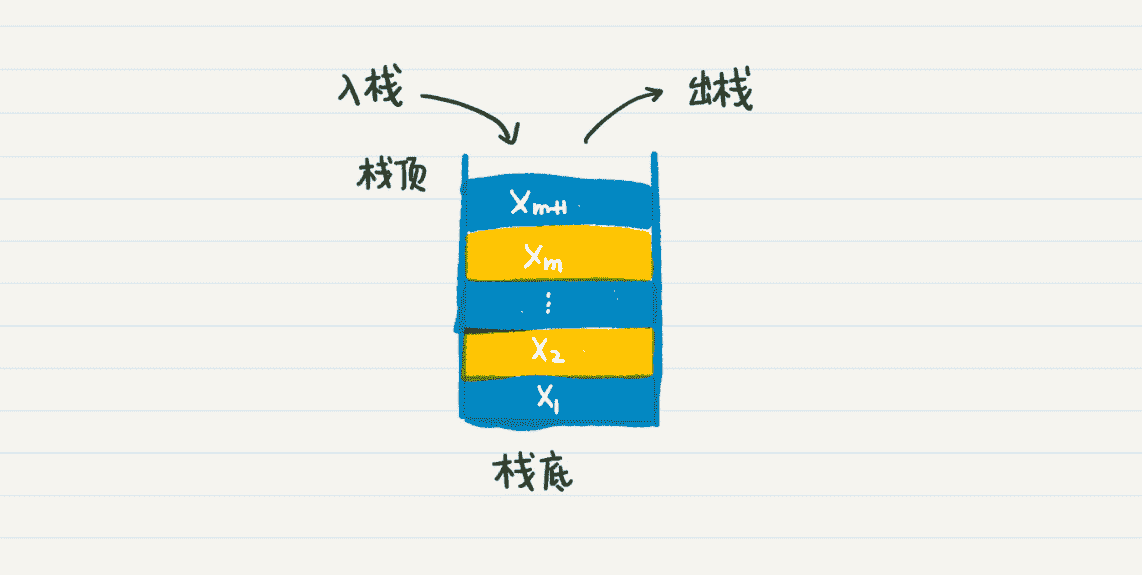
为什么栈可以进行深度优先搜索呢?你可以先回顾一下上一节,我解释深度优先搜索时候的例子。为了方便你回想,我把图放在这里了。
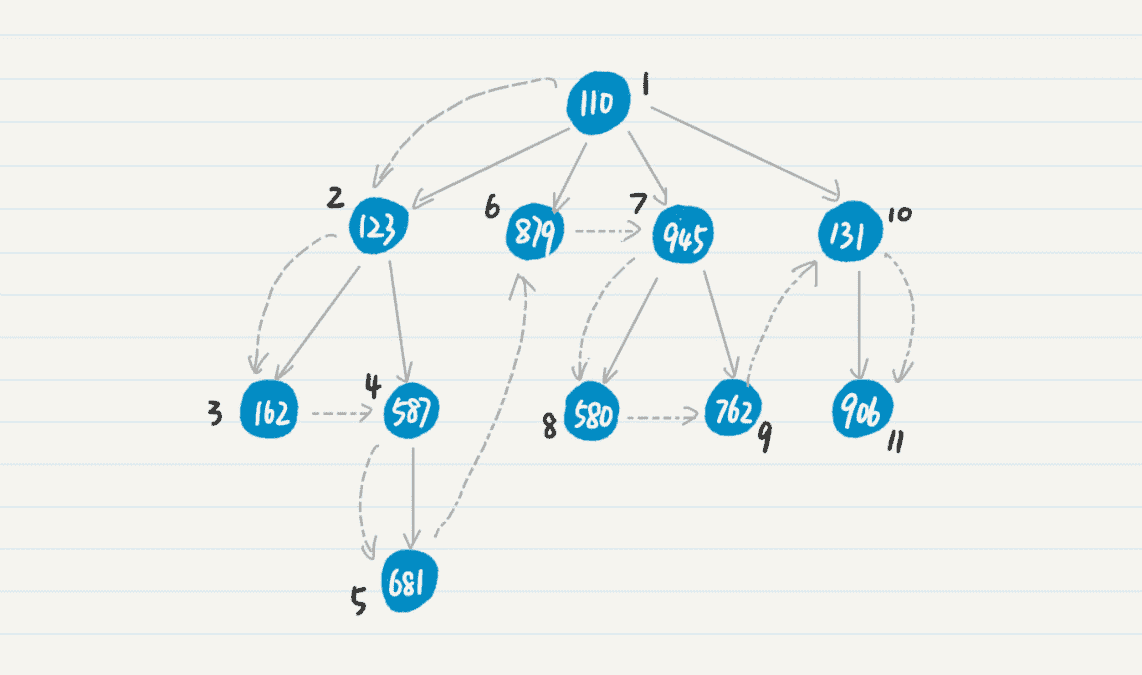
然后,我们用栈来实现一下这个过程。
第 1 步,将初始结点 110 压入栈中。
第 2 步,弹出结点 110,搜出下一级结点 123、879、945 和 131。
第 3 步,将结点 123、879、945 和 131 压入栈中。
第 4 步,重复第 2 步和第 3 步弹出和压入的步骤,处理结点 123,将新发现结点 162 和 587 压入栈中。
第 5 步,处理结点 162,由于 162 是叶子结点,所以没有发现新的点。第 6 步,重复第 2 和第 3 步,处理结点 587,将新发现结点 681 压入栈中。
……
第 n-1 步,重复第 2 和第 3 步,处理结点 131,将新发现结点 906 压入栈中。
第 n 步,重复第 2 和第 3 步,处理结点 906,没有发现新的结点,也没有更多待处理的结点,整个过程结束。
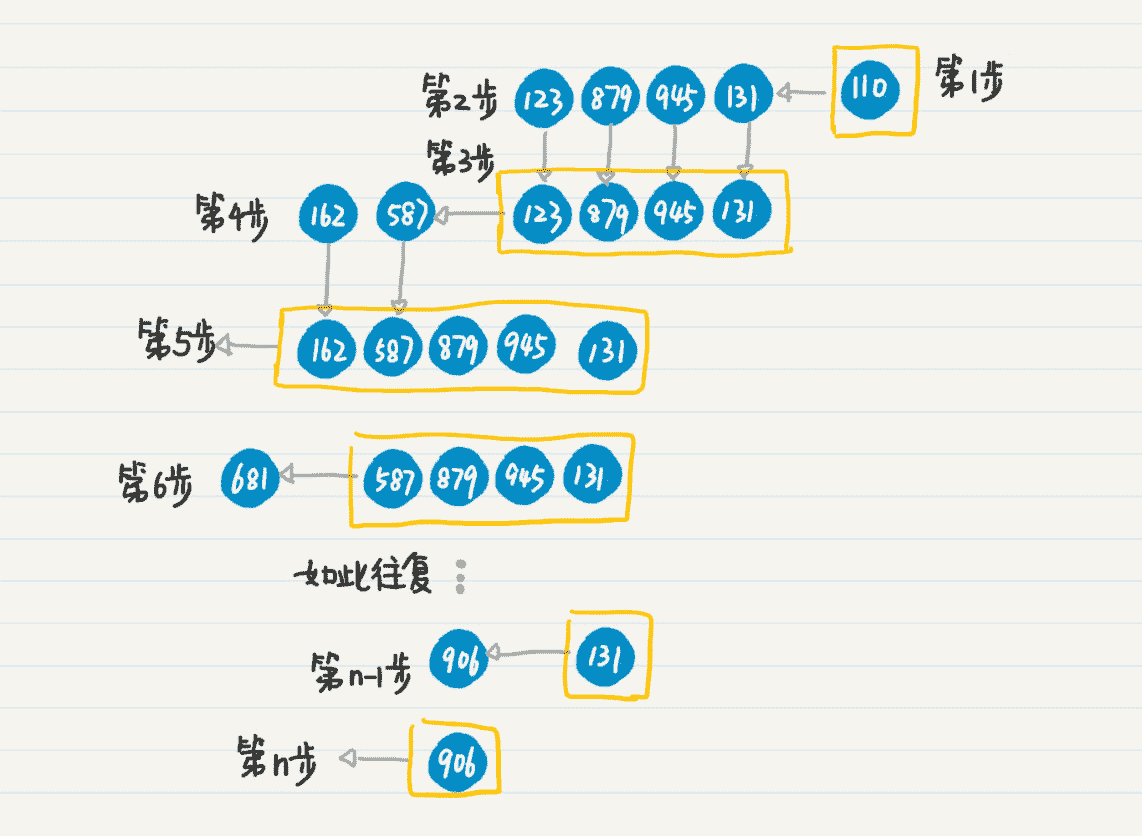
从上面的步骤来看,栈先进后出的特性,可以模拟函数的递归调用。实际上,计算机系统里的函数递归,在内部也是通过栈来实现的。如果我们不使用函数调用时自动生成的栈,而是手动使用栈的数据结构,就能始终保持数据的副本只有一个,大大节省内存的使用量。
用 TreeNode 类和栈实现深度优先搜索的代码我写出来了,你可以看看。
|
|
这里面有个细节需要注意一下。当我们把某个结点的子结点压入栈的时候,由于栈“先进后出”的特性,会导致子结点的访问顺序,和递归遍历时子结点的访问顺序相反。如果你希望两者保持一致,可以用一个临时的栈 stackTemp 把子结点入栈的顺序颠倒过来。
小结
这一节我们用递归来实现了深度优先搜索。说到这,你可能会想到,之前讨论的归并排序、排列组合等课题,也采用了递归来实现,那它们是不是也算深度优先搜索呢?
我把归并排序和排列的分解过程放在这里,它们是不是也可以用有向树来表示呢?
在归并排序的数据分解阶段,初始的数据集就是树的根结点,二分之前的数据集代表父节点,而二分之后的左半边的数据集和右半边的数据集都是父结点的子结点。分解过程一直持续到单个的数值,也就是最末端的叶子结点,很明显这个阶段可以用树来表示。如果使用递归编程来进行数据的切分,那么这种实现就是深度优先搜索的体现。

在排列中,我们可以把空集认为是树的根结点,如果把每次选择的元素作为父结点,那么剩下可选择的元素,就构成了这个父结点的子结点。而每多选择一个元素,就会把树的高度加 1。因此,我们也可以使用递归和深度优先搜索,列举所有可能的排列。
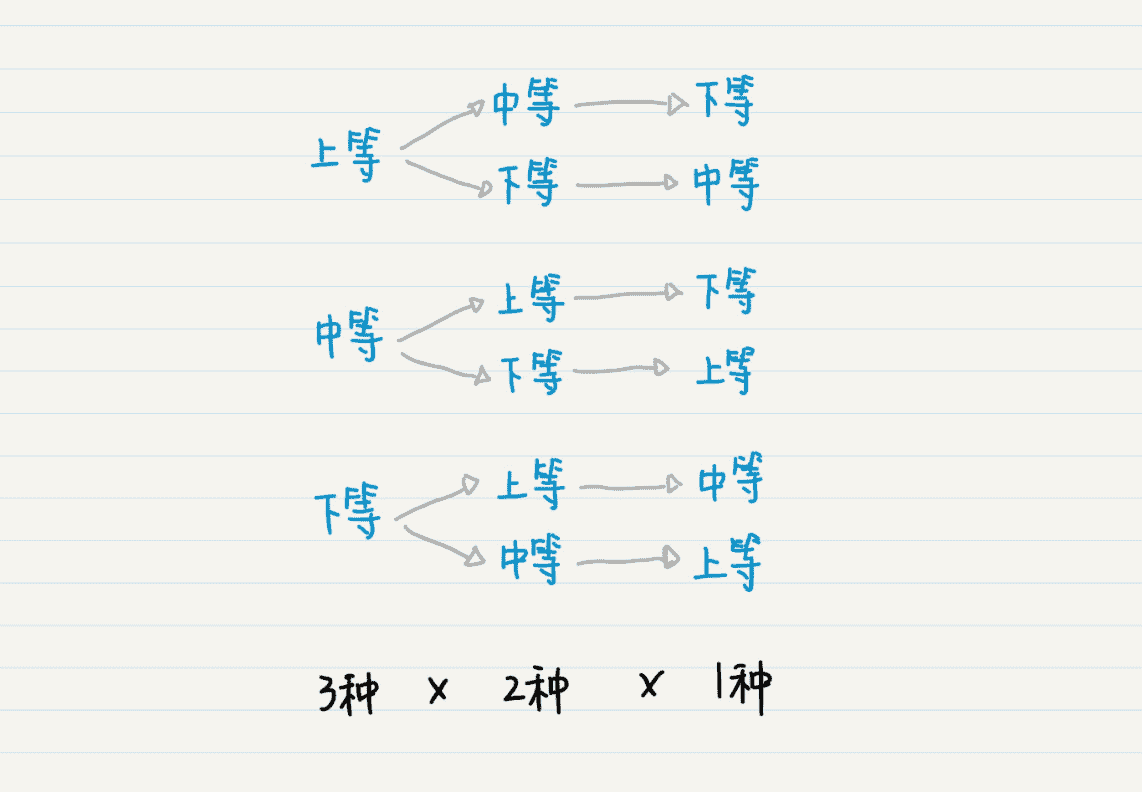
从这两个例子,我们可以看出有些数学思想都是相通的,例如递归、排列和深度优先搜索等等。
我来总结一下,其实深度优先搜索的核心思想,就是按照当前的通路,不断地向前进,当遇到走不通的时候就回退到上一个结点,通过另一个新的边进行尝试。如果这一个点所有的方向都走不通的时候,就继续回退。这样一次一次循环下去,直到到达目标结点。树中的每个结点,既可以表示某个子问题和它所对应的抽象状态,也可以表示某个数据结构中一部分具体的值。
所以,我们需要做的是,观察问题是否可以使用递归的方式来逐步简化,或者是否需要像前缀树这样遍历,如果是,就可以尝试使用深度优先搜索来帮助我们思考并解决问题。

思考题
这两节我讲的是树的深度优先搜索。如果是在一般的图中进行深度优先搜索,会有什么不同呢?
欢迎在留言区交作业,并写下你今天的学习笔记。你可以点击“请朋友读”,把今天的内容分享给你的好友,和他一起精进。

文章作者 anonymous
上次更新 2024-03-12