加餐6|分布式系统的本质是什么?
文章目录
你好,我是编辑冬青。上一期加餐我们分享了张帆老师的一篇文章,从总体上聊了聊分布式系统,那作为系列分享,这期加餐我还为你带来了张帆老师的另一篇文章,进一步聊聊分布式系统的本质。这里交付给你,期待能给你带来更多的收获!
分布式系统的价值
谈到分布式系统的价值,可能就得从 1953 年说起了。在这一年,埃布·格罗希(Herb Grosch)提出了一个他观察得出的规律——Grosch 定律。维基百科中是这样描述的:
计算机性能随着成本的平方而增加。如果计算机 A 的成本是计算机 B 的两倍,那么计算机 A 的速度应该是计算机 B 的四倍。
这一论断与当时的大型机技术非常吻合,因而使得许多机构都尽其所能购买最大的单个大型机。其实,这也非常符合惯性思维,简单粗暴。
然而,1965 年高登·摩尔(Gordon Moore)提出了摩尔定律。经过几年的发展,人们发现摩尔定律的预测是符合现实的。这就意味着,集中式系统的运算能力每隔一段时间才能提升一倍。
那么,到底要隔多久呢?这个“时间”有很多版本,比如广为流传的 18 个月版本,以及 Gordon Moore 本人坚持的 2 年版本。这里我们不用太过纠结于实际情况到底是哪个“时间”版本,因为这其中隐含的意思更重要,即:如果你的系统需承载的计算量的增长速度大于摩尔定律的预测,那么在未来的某一个时间点,集中式系统将无法承载你所需的计算量。
而这只是一个内在因素,真正推动分布式系统发展的催化剂是“经济”因素。
人们发现,用廉价机器的集合组成的分布式系统,除了可以获得超过 CPU 发展速度的性能外,花费更低,具有更好的性价比,并且还可以根据需要增加或者减少所需机器的数量。
所以,我们得到一个新结论:无论是要以低价格获得普通的性能,还是要以较高的价格获得极高的性能,分布式系统都能够满足。并且受规模效应的影响,系统越大,性价比带来的收益越高。
之后,进入到互联网快速发展的时期,我们看到了分布式系统相比集中式系统的另一个更明显的优势:更高的可用性。例如,有 10 个能够承载 10000 流量的相同的节点,如果其中的 2 个挂了,只要实际流量不超过 8000,系统依然能够正常运转。
而这一切的价值,都是建立在分布式系统的“分治”和“冗余”之上的。从全局角度来看,这其实就是分布式系统的本质。
分治
分治,字面意思是“分而治之”,和我们的大脑在解决问题时的思考方式是一样的。我们可以将整个过程分为 3 步:分解 -> 治理 -> 归并。而分治思想的表现形式多样,分层、分块都是它的体现。

这么做的好处是:问题越小越容易被解决,并且,只要解决了所有子问题,父问题就都可以被解决了。但是,这么做的时候,需要满足一个最重要的条件:**不同分支上的子问题,不能相互依赖,需要各自独立。**因为一旦包含了依赖关系,子问题和父问题之间就失去了可以被“归并”的意义。在软件开发领域,我们把这个概念称为“耦合度”和“内聚度”,这两个度量概念非常重要。
耦合度,指的是软件模块之间相互依赖的程度。比如,每次调用方法 A 之后都需要同步调用方法 B,那么此时方法 A 和 B 间的耦合度是高的。
内聚度,指的是模块内的元素具有的共同点的相似程度。比如,一个类中的多个方法有很多的共同之处,都是做支付相关的处理,那么这个类的内聚度是高的。
内聚度通常与耦合度形成对比。低耦合通常与高内聚相关,反之亦然。
所以,当你打算进行分治的时候,耦合度和内聚度就是需要考虑的重点。
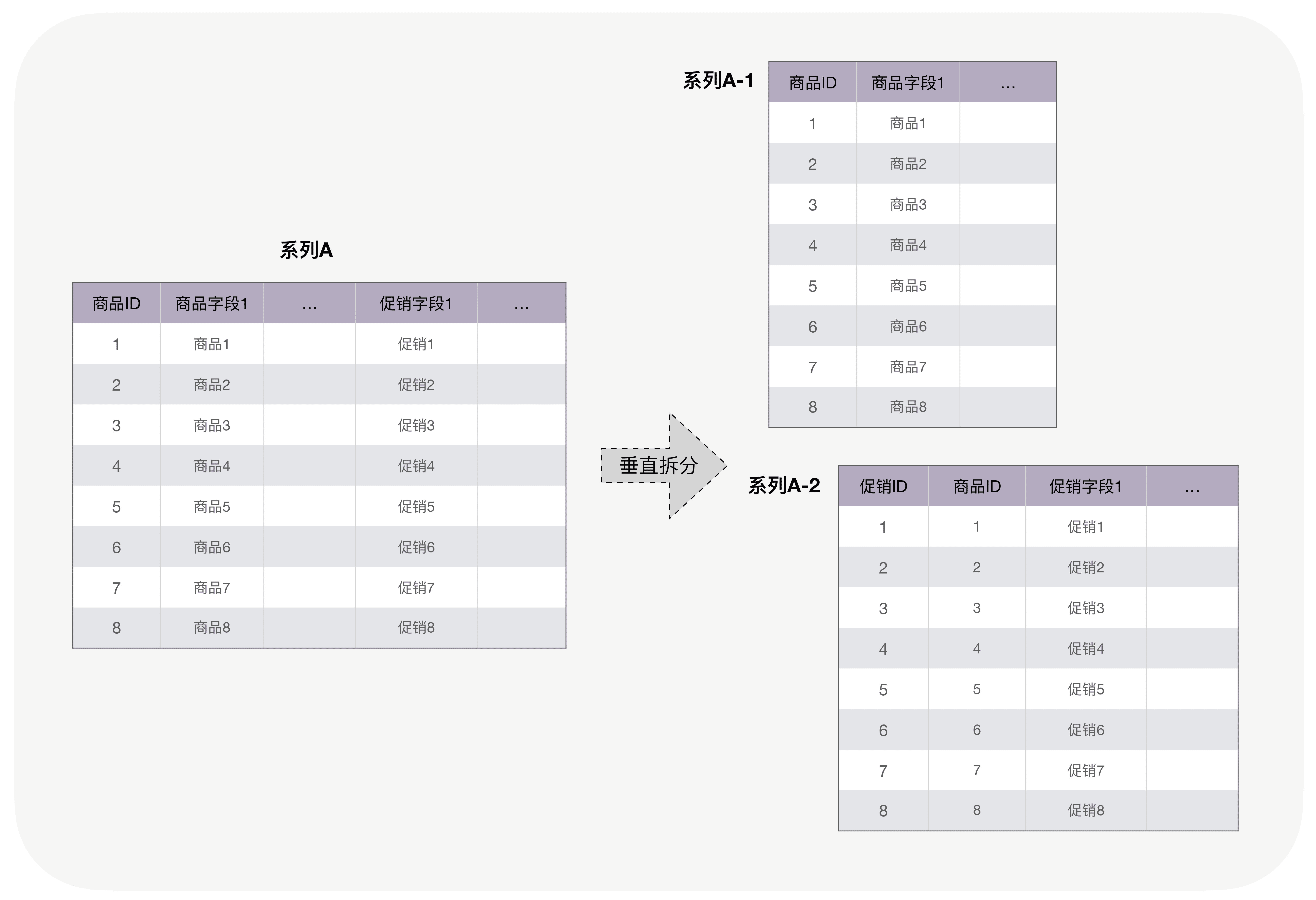
下面我们来看个例子,体会一下耦合度和内聚度的含义(图仅用于表达含义,切勿作其他参考)。假设一个电商平台,为了应对更大的访问量,需要拆分一个同时包含商品、促销的系统。如果垂直拆分,是这样:
而如果水平拆分,则是这样的:
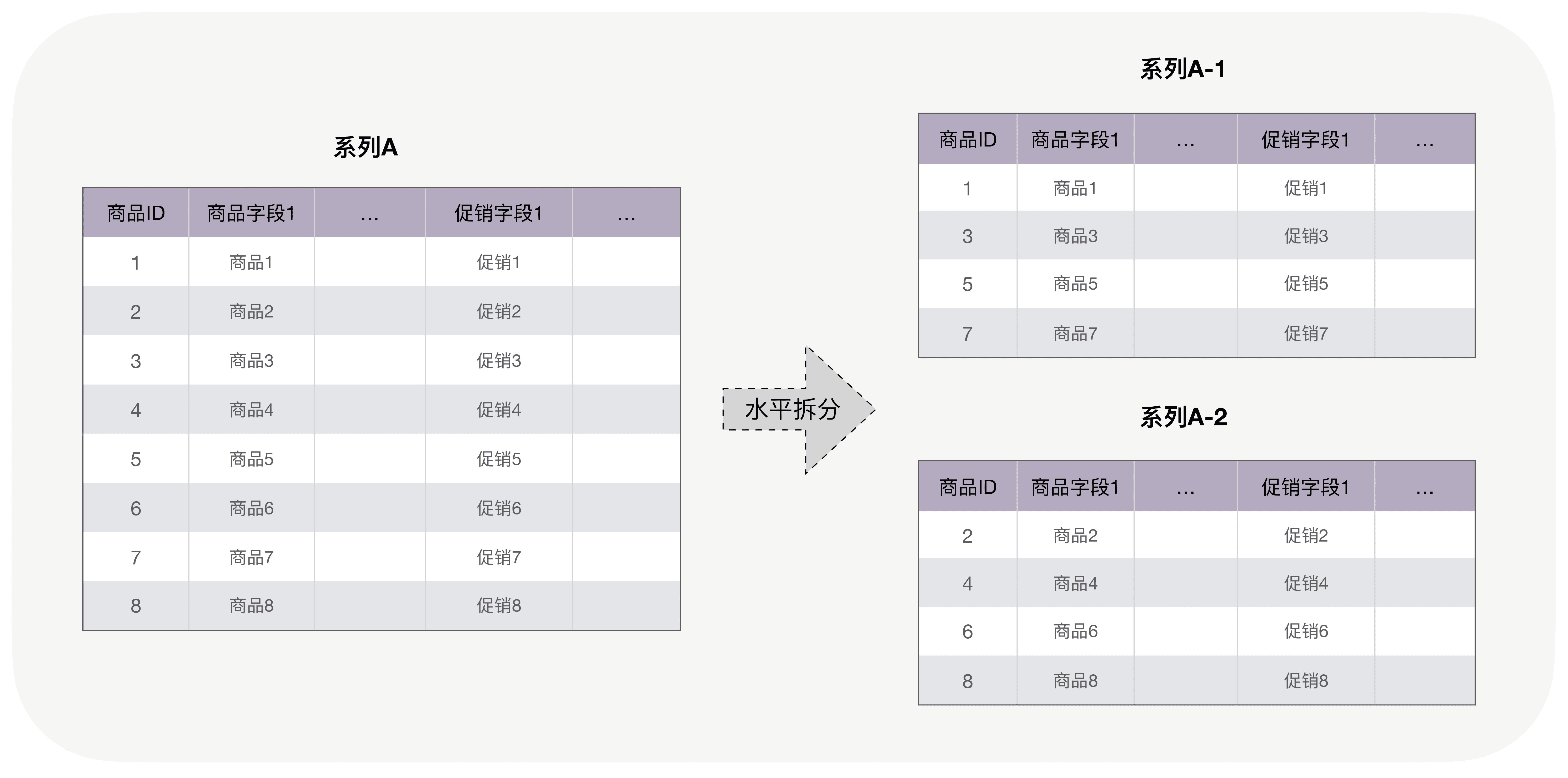
假如我们面对的场景仅仅是具体的商品详情展示页面,很显然,用水平拆分的效果会更好。因为传统的商品展示必然会同时展示促销,所以,如果用水平拆分,一次请求即可获取所有数据,内聚度非常高,并且此时模块间完全没有耦合。而如果是垂直拆分的话,就需要同时请求 2 个节点的数据并进行组合,因此耦合度更高、内聚度更差。
但是,这样的假设在真实的电商场景中是不存在的。从全局来看,订单、购物车、商品列表等许多其他场景也需要促销信息。并且这个时候我们发现引入了一些新的主体,诸如订单、购物车、商品分类等等。这个时候,水平拆分带来的好处越来越小,因为这样只解决了多个耦合中的一个,低耦合丧失了。并且随着商品和促销与外界的关联越来越多,必然有些场景仅仅涉及到商品和促销的其中一个,但是处理的时候,我们还需要避免受到另一个的影响。如此,高内聚也丧失了。
这个时候,反而通过垂直拆分可以获得更优的耦合度和内聚度,如下图。

最高的耦合关系从原先的 6 降到了 4,并且商品和促销各自的处理相互不受影响。
所以,你会发现随着业务的变化,耦合度与内聚度也会发生变化。因此,及时地进行梳理和调整,可以避免系统的复杂度快速增长,这样才能最大程度地发挥“分治”带来的好处。
综上,分治可以简化解题的难度,通过高内聚、低耦合的协作关系达到更好的“性能与经济比”,来承载更大的流量。而“冗余”则带来了系统可以 7*24 小时不间断运作的希望。
冗余
这里的冗余并不等同于代码的冗余、无意义的重复劳动,而是我们有意去做的、人为增加的重复部分。其目的是容许在一定范围内出现故障,而系统不受影响,如下图。

此时,我们可以将冗余的节点部署在一个独立的环境中。这个独立的环境,可能是处于同一个局域网内的不同主机,也可能是在不同的局域网,还可能是在不同的机房。很显然,它们能够应对的故障范围是逐步递增的。
但是,像这种单纯为了备用而做的冗余,最大的弊端是,如果没有出现故障,那么冗余的这部分资源就白白浪费了,不能发挥任何作用。所以,我们才提出了诸如双主多活、读写分离之类的概念,以提高资源利用率。
当然,除了软件层面,硬件层面的冗余也是同样的道理。比如,磁盘阵列可以容忍几块之内磁盘损坏,而不会影响整体。
不过也很显然,当故障影响范围大于你冗余的容量时,系统依然会挂。所以,既然你无法预知故障的发生情况,那么做冗余的时候需要平衡的另一端就是成本。相比更多的冗余,追求更好的性价比更合理一些。
在我们生活中的冗余也到处存在。比如,大部分的飞机和直升机的发动机都是偶数的,汽车中的电子控制系统的冗余机制等。就好比替身与真身的关系,冗余的就是替身。它可以和真身同时活动,也可以代替真身活动。
分治和冗余讲究的都是分散化,最终形成一个完整的系统还需要将它们“连接”起来。天下没有免费的午餐,获得分布式系统价值的同时,这个“再连接”的过程就是我们相比集中式系统要做的额外工作。
再连接
如何将拆分后的各个节点再次连接起来,从模式上来说,主要是去中心化与中心化之分。
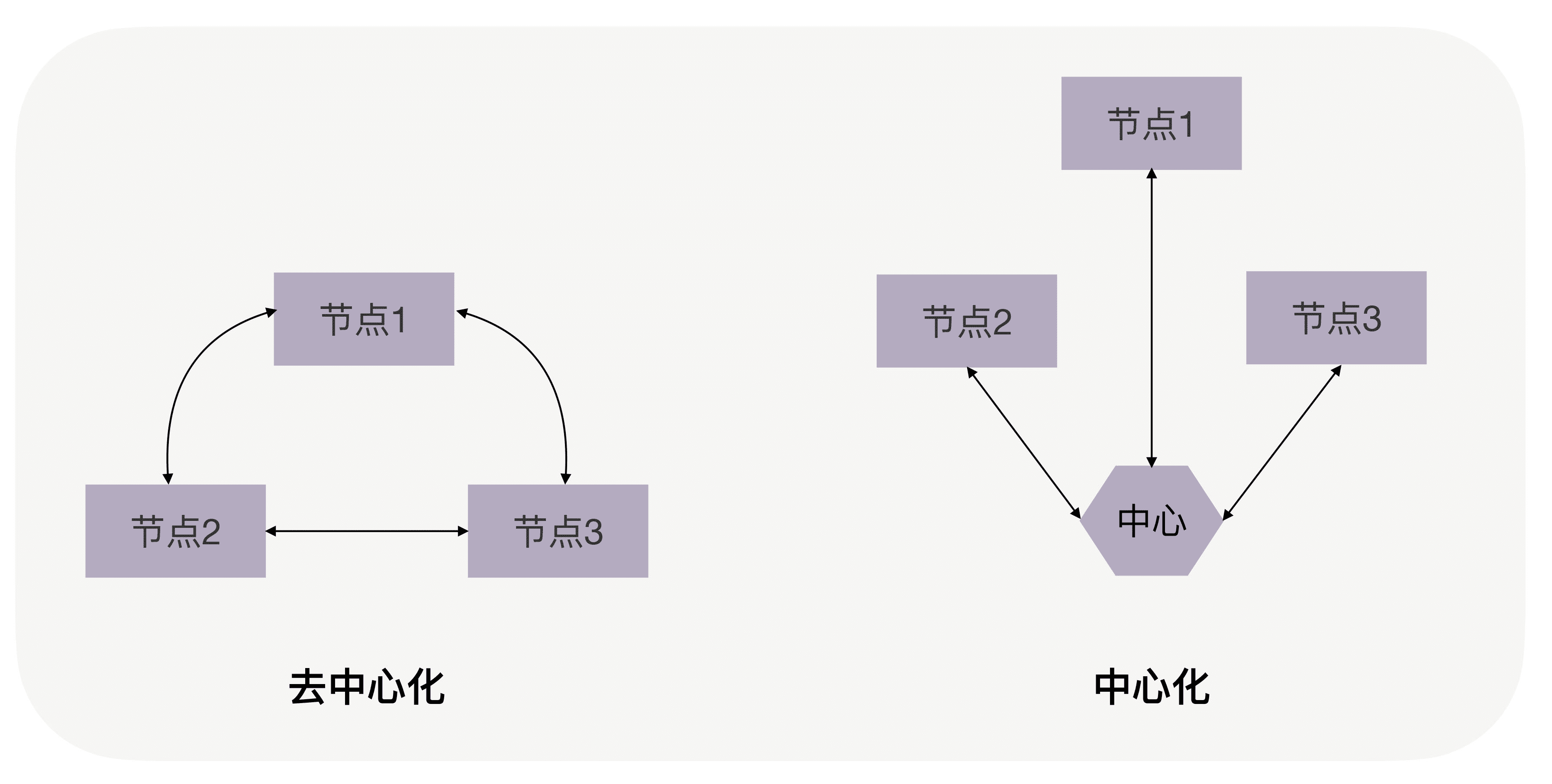
前者完全消除了中心节点故障带来的全盘出错的风险,却带来了更高的节点间协作成本。后者通过中心节点的集中式管理大大降低了协作成本,但是一旦中心节点故障则全盘出错。
另外,从技术角度来说,如何选择通信协议和序列化机制,也是非常重要的。
虽然很多通讯协议和序列化机制完全可以承担任何场景的连接责任,但是不同的协议和序列化机制在适合的场景下才能发挥它最大的优势。比如,需要更高性能的场景运用 TCP 协议优于 HTTP 协议;需要更高吞吐量的场景运用 UDP 协议优于 TCP 协议,等等。
小结
不管系统的规模发展到多大,合理的拆分,加上合适的连接方式,那么至少会是一个运转顺畅、协作舒服的系统,至少能够正常发挥分布式系统应有的价值。
如今,我们发现分布式系统还可以发挥更多的作用。比如,只要基于一个统一的上层通信协议,其下层的不同节点可以运用不同的技术栈来发挥不同技术各自的优势,比如用 Go 来应对高并发场景,用 Python 来做数据分析等。再比如,提高交付的速度,如下图。
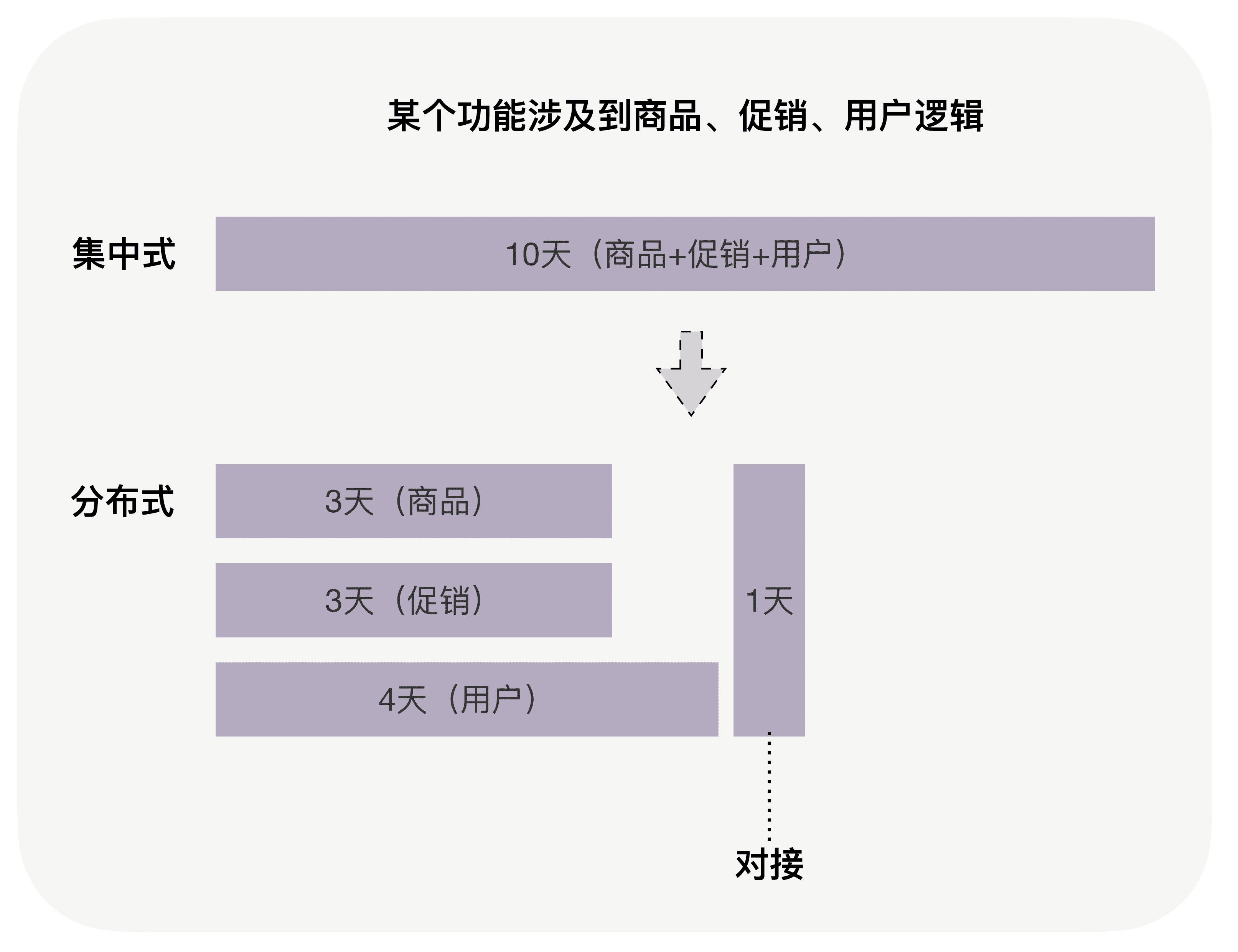
通过分配不同的团队、人员同时进行多个模块的开发,虽然总的耗时增加了,但是整体的交付速度加快了。
事物最本质的东西是恒定的、不变的,可以指引我们的工作方向。分布式系统的本质也是这样。例如,这样的“分治”方案耦合度和内聚度是否最优,这样做“冗余”带来的收益是否成本能够接受。只要持续带着这些思考,我们就好像拿着一杆秤,基于它,我们就可以去衡量各种变量影响,然后作权衡。比如成本、时间、人员、性能、易维护等等。也可以基于它去判断什么样的框架、组件、协议更适合当前的环境。
需要不断的权衡,也意味着分布式系统的设计工作一定不是一步到位,而是循序渐进的。因为过分为未知的未来做更多的考量,最终可能都会打水漂。所以,建议以多考虑 1~2 步为宜。假如以你所在的团队中对重大技术升级的频率来作为参考的话,做可供 2 个升级周期的设计,花一个升级周期的时间先实现第一阶段,下个阶段可以选择直接实现剩下的部分,也可继续进行 2 个升级周期设计,开启一个循环,持续迭代,并且不断修正方向以更贴近现实的发展,就如下图这样。

以上就是今天的全部内容。最后,互动一下,在你的工作或者学习中,你觉得分布式系统还具备哪些价值呢?欢迎留言!
文章作者 anonymous
上次更新 2024-05-15