在22 讲中,我们侧重讲解了汇编语言的基础知识,包括构成元素、汇编指令和汇编语言中常用的寄存器。学习完基础知识之后,你要做的就是多加练习,和汇编语言“混熟”。小窍门是查看编译器所生成的汇编代码,跟着学习体会。
不过,可能你是初次使用汇编语言,对很多知识点还会存在疑问,比如:
- 在汇编语言里调用函数(过程)时,传参和返回值是怎么实现的呢?
- 21 讲中运行期机制所讲的栈帧,如何通过汇编语言实现?
- 条件语句和循环语句如何实现?
- ……
为此,我策划了一期加餐,针对性地讲解这样几个实际场景,希望帮你加深对汇编语言的理解。
示例 1:过程调用和栈帧
这个例子涉及了一个过程调用(相当于 C 语言的函数调用)。过程调用是汇编程序中的基础结构,它涉及到栈帧的管理、参数的传递这两个很重要的知识点。
假设我们要写一个汇编程序,实现下面 C 语言的功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
/*function-call1.c */
#include <stdio.h>
int fun1(int a, int b){
int c = 10;
return a+b+c;
}
int main(int argc, char *argv[]){
printf("fun1: %d\n", fun1(1,2));
return 0;
}
|
fun1 函数接受两个整型的参数:a 和 b,来看看这两个参数是怎样被传递过去的,手写的汇编代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
# function-call1-craft.s 函数调用和参数传递
# 文本段, 纯代码
.section __TEXT,__text,regular,pure_instructions
_fun1:
# 函数调用的序曲, 设置栈指针
pushq %rbp # 把调用者的栈帧底部地址保存起来
movq %rsp, %rbp # 把调用者的栈帧顶部地址, 设置为本栈帧的底部
subq $4, %rsp # 扩展栈
movl $10, -4(%rbp) # 变量 c 赋值为 10,也可以写成 movl $10, (%rsp)
# 做加法
movl %edi, %eax # 第一个参数放进 %eax
addl %esi, %eax # 把第二个参数加到 %eax,%eax 同时也是存放返回值的寄存器
addl -4(%rbp), %eax # 加上 c 的值
addq $4, %rsp # 缩小栈
# 函数调用的尾声, 恢复栈指针为原来的值
popq %rbp # 恢复调用者栈帧的底部数值
retq # 返回
.globl _main # .global 伪指令让 _main 函数外部可见
_main: ## @main
# 函数调用的序曲, 设置栈指针
pushq %rbp # 把调用者的栈帧底部地址保存起来
movq %rsp, %rbp # 把调用者的栈帧顶部地址, 设置为本栈帧的底部
# 设置第一个和第二个参数, 分别为 1 和 2
movl $1, %edi
movl $2, %esi
callq _fun1 # 调用函数
# 为 pritf 设置参数
leaq L_.str(%rip), %rdi # 第一个参数是字符串的地址
movl %eax, %esi # 第二个参数是前一个参数的返回值
callq _printf # 调用函数
# 设置返回值。这句也常用 xorl %esi, %esi 这样的指令, 都是置为零
movl $0, %eax
# 函数调用的尾声, 恢复栈指针为原来的值
popq %rbp # 恢复调用者栈帧的底部数值
retq # 返回
# 文本段, 保存字符串字面量
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "Hello World! :%d \n"
|
**需要注意,**手写的代码跟编译器生成的可能有所不同,但功能是等价的,代码里有详细的注释,你肯定能看明白。
**借用这个例子,我们讲一下栈的管理。**在示例代码的两个函数里,有这样的固定结构:
1
2
3
4
5
6
7
8
9
10
11
12
|
# 函数调用的序曲, 设置栈指针
pushq %rbp # 把调用者的栈帧底部地址保存起来
movq %rsp, %rbp # 把调用者的栈帧顶部地址,设置为本栈帧的底部
...
# 函数调用的尾声, 恢复栈指针为原来的值
popq %rbp # 恢复调用者栈帧的底部数值
|
在 C 语言生成的代码中,一般用 %rbp 寄存器指向栈帧的底部,而 %rsp 则指向栈帧的顶部。**栈主要是通过 push 和 pop 这对指令来管理的:**push 把操作数压到栈里,并让 %rsp 指向新的栈顶,pop 把栈顶数据取出来,同时调整 %rsp 指向新的栈顶。
在进入函数的时候,用 pushq %rbp 指令把调用者的栈帧地址存起来(根据调用约定保护起来),而把调用者的栈顶地址设置成自己的栈底地址,它等价于下面两条指令,你可以不用 push 指令,而是运行下面两条指令:
1
2
3
4
|
subq $8, %rsp # 把 %rsp 的值减 8,也就是栈增长 8 个字节,从高地址向低地址增长
movq %rbp, (%rsp) # 把 %rbp 的值写到当前栈顶指示的内存位置
|
而在退出函数前,调用了 popq %rbp 指令。它恢复了之前保存的栈指针的地址,等价于下面两条指令:
1
2
3
4
|
movq (%rsp), %rbp # 把栈顶位置的值恢复回 %rbp,这是之前保存在栈里的值。
addq $8, %rsp # 把 %rsp 的值加 8,也就是栈减少 8 个字节
|
上述过程画成一张直观的图,表示如下:

上面每句指令执行以后,我们看看 %rbp 和 %rsp 值的变化:
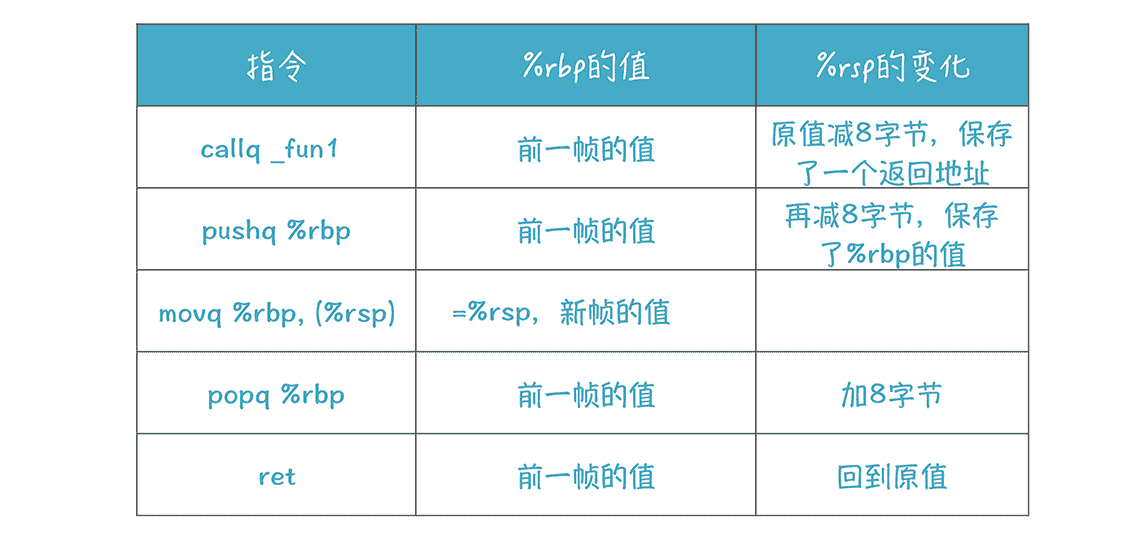
再来看看使用局部变量的时候会发生什么:
1
2
3
4
5
6
7
8
|
subq $4, %rsp # 扩展栈
movl $10, -4(%rbp) # 变量 c 赋值为 10,也可以写成 movl $10, (%rsp)
...
addq $4, %rsp # 缩小栈
|
我们通过减少 %rsp 的值,来扩展栈,然后在扩展出来的 4 个字节的位置上写入整数,这就是变量 c 的值。在返回函数前,我们通过 addq $4, %rsp 再把栈缩小。这个过程如下图所示:
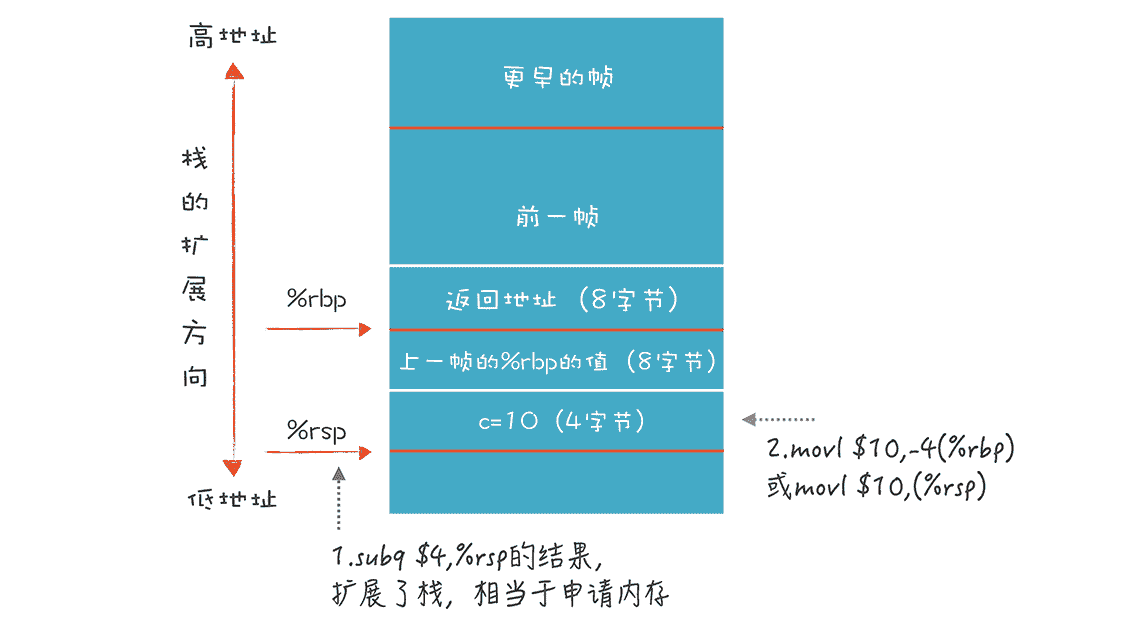
在这个例子中,我们通过移动 %rsp 指针来改变帧的大小。%rbp 和 %rsp 之间的空间就是当前栈帧。而过程调用和退出过程,分别使用 call 指令和 ret 指令。“callq _fun1”是调用 _fun1 过程,这个指令相当于下面两句代码,它用到了栈来保存返回地址:
1
2
3
4
|
pushq %rip # 保存下一条指令的地址,用于函数返回继续执行
jmp _fun1 # 跳转到函数 _fun1
|
_fun1 函数用 ret 指令返回,它相当于:
1
2
3
4
|
popq %rip # 恢复指令指针寄存器
jmp %rip
|
上一讲,我提到,在 X86-64 架构下,新的规范让程序可以访问栈顶之外 128 字节的内存,所以,我们甚至不需要通过改变 %rsp 来分配栈空间,而是直接用栈顶之外的空间。
上面的示例程序,你可以用 as 命令生成可执行程序,运行一下看看,然后试着做一下修改,逐步熟悉汇编程序的编写思路。
示例 2:同时使用寄存器和栈来传参
上一个示例中,函数传参只使用了两个参数,这时是通过两个寄存器传递参数的。这次,我们使用 8 个参数,来看看通过寄存器和栈传参这两种不同的机制。
在 X86-64 架构下,有很多的寄存器,所以程序调用约定中规定尽量通过寄存器来传递参数,而且,只要参数不超过 6 个,都可以通过寄存器来传参,使用的寄存器如下:

超过 6 个的参数的话,我们要再加上栈来传参:

根据程序调用约定的规定,参数 1~6 是放在寄存器里的,参数 7 和 8 是放到栈里的,先放参数 8,再放参数 7。
在 23 讲,我会带你为下面的一段 playscript 程序生成汇编代码:
1
2
3
4
5
6
7
8
9
10
11
12
|
//asm.play
int fun1(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8){
int c = 10;
return x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8 + c;
}
println("fun1:" + fun1(1,2,3,4,5,6,7,8));
|
现在,我们可以按照调用约定,先手工编写一段实现相同功能的汇编代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
# function-call2-craft.s 函数调用和参数传递
# 文本段, 纯代码
.section __TEXT,__text,regular,pure_instructions
_fun1:
# 函数调用的序曲, 设置栈指针
pushq %rbp # 把调用者的栈帧底部地址保存起来
movq %rsp, %rbp # 把调用者的栈帧顶部地址, 设置为本栈帧的底部
movl $10, -4(%rbp) # 变量 c 赋值为 10, 也可以写成 movl $10, (%rsp)
# 做加法
movl %edi, %eax # 第一个参数放进 %eax
addl %esi, %eax # 加参数 2
addl %edx, %eax # 加参数 3
addl %ecx, %eax # 加参数 4
addl %r8d, %eax # 加参数 5
addl %r9d, %eax # 加参数 6
addl 16(%rbp), %eax # 加参数 7
addl 24(%rbp), %eax # 加参数 8
addl -4(%rbp), %eax # 加上 c 的值
# 函数调用的尾声, 恢复栈指针为原来的值
popq %rbp # 恢复调用者栈帧的底部数值
retq # 返回
.globl _main # .global 伪指令让 _main 函数外部可见
_main: ## @main
# 函数调用的序曲, 设置栈指针
pushq %rbp # 把调用者的栈帧底部地址保存起来
movq %rsp, %rbp # 把调用者的栈帧顶部地址, 设置为本栈帧的底部
subq $16, %rsp # 这里是为了让栈帧 16 字节对齐,实际使用可以更少
# 设置参数
movl $1, %edi # 参数 1
movl $2, %esi # 参数 2
movl $3, %edx # 参数 3
movl $4, %ecx # 参数 4
movl $5, %r8d # 参数 5
movl $6, %r9d # 参数 6
movl $7, (%rsp) # 参数 7
movl $8, 8(%rsp) # 参数 8
callq _fun1 # 调用函数
# 为 pritf 设置参数
leaq L_.str(%rip), %rdi # 第一个参数是字符串的地址
movl %eax, %esi # 第二个参数是前一个参数的返回值
callq _printf # 调用函数
# 设置返回值。这句也常用 xorl %esi, %esi 这样的指令, 都是置为零
movl $0, %eax
addq $16, %rsp # 缩小栈
# 函数调用的尾声, 恢复栈指针为原来的值
popq %rbp # 恢复调用者栈帧的底部数值
retq # 返回
# 文本段, 保存字符串字面量
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "fun1 :%d \n"
|
用 as 命令,把这段汇编代码生成可执行文件,运行后会输出结果:“fun1: 46”。
1
2
3
4
|
as functio-call2-craft.s -o function-call2
./function-call2
|
这段程序虽然有点儿长,但思路很清晰,比如,每个函数(过程)都有固定的结构。7~10 行,我叫做序曲,是设置栈帧的指针;25~26 行,我叫做尾声,是恢复栈底指针并返回;13~22 行是做一些计算,还要为本地变量在栈里分配一些空间。
**我建议你读代码的时候,**对照着每行代码的注释,弄清楚这条代码所做的操作,以及相关的寄存器和内存中值的变化,脑海里有栈帧和寄存器的直观的结构,就很容易理解清楚这段代码了。
除了函数调用以外,我们在编程时经常使用循环语句和 if 语句,它们转换成汇编是什么样子呢?我们来研究一下,首先看看 while 循环语句。
示例 3:循环语句的汇编码解析
看看下面这个 C 语言的语句:
1
2
3
4
5
6
7
8
9
10
|
void fun1(int a){
while (a < 10){
a++;
}
}
|
我们要使用"gcc -S ifstmt.c -o ifstmt.s"命令,把它转换成汇编语句(注意不要带优化参数):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
.section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 15
.globl _fun1 ## -- Begin function fun1
.p2align 4, 0x90
_fun1: ## @fun1
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl %edi, -4(%rbp) # 把参数 a 放到栈里
LBB0_1: ## =>This Inner Loop Header: Depth=1
cmpl $10, -4(%rbp) # 比较参数 1 和立即数 10, 设置 eflags 寄存器
jge LBB0_3 # 如果大于等于,则跳转到 LBB0_3 基本块
## %bb.2: ## in Loop: Header=BB0_1 Depth=1
movl -4(%rbp), %eax # 这 2 行,是给 a 加 1
addl $1, %eax
movl %eax, -4(%rbp)
jmp LBB0_1
LBB0_3:
popq %rbp
retq
.cfi_endproc
## -- End function
.subsections_via_symbols
|
这段代码的 15、16、21 行是关键,我解释一下:
- 第 15 行,用 cmpl 指令,将 %edi 寄存器中的参数 1(即 C 代码中的参数 a)和立即数 10 做比较,比较的结果会设置 EFLAGS 寄存器中的相关位。
EFLAGS 中有很多位,下图是Intel 公司手册中对各个位的解释,有的指令会影响这些位的设置,比如 cmp 指令,有的指令会从中读取信息,比如 16 行的 jge 指令:
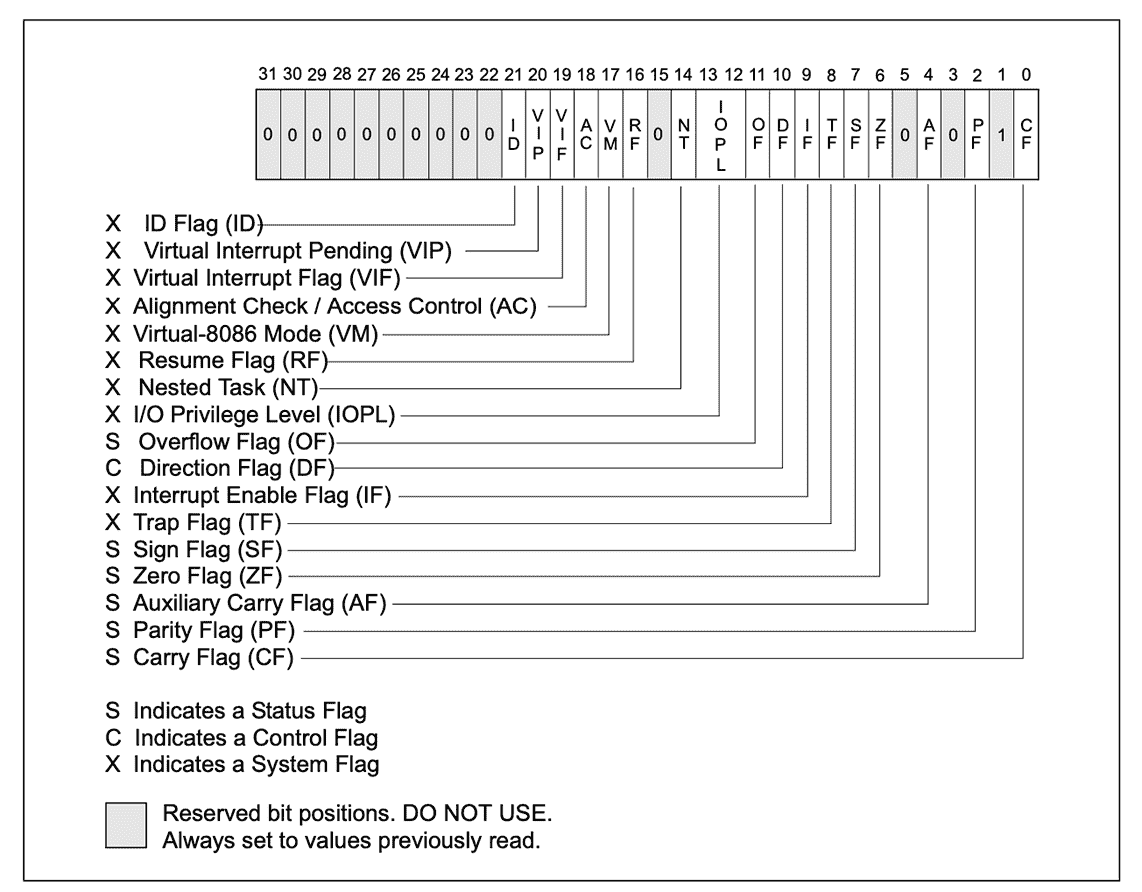
- 第 16 行,jge 指令。jge 是“jump if greater or equal”的缩写,也就是当大于或等于的时候就跳转。大于等于是从哪知道的呢?就是根据 EFLAGS 中的某些位计算出来的。
- 第 21 行,跳转到循环的开始。
在这个示例中,我们看到了 jmp(无条件跳转指令)和 jge(条件跳转指令)两个跳转指令。条件跳转指令很多,它们分别是基于 EFLAGS 的状态位做不同的计算,判断是否满足跳转条件,看看下面这张表格:
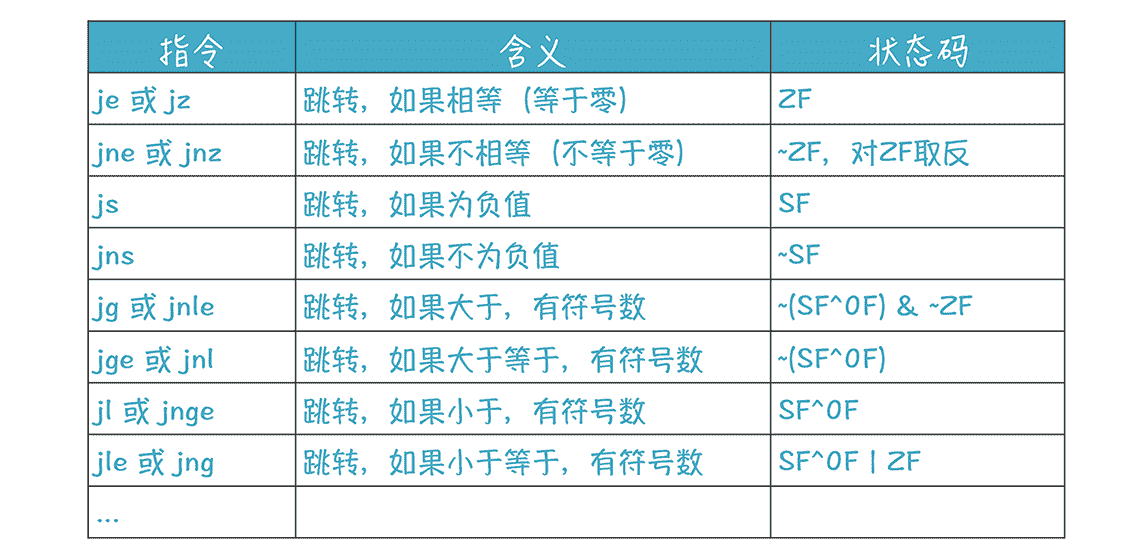
表格中的跳转指令,是基于有符号的整数进行判断的,对于无符号整数、浮点数,还有很多其他的跳转指令。现在你应该体会到,汇编指令为什么这么多了。好在其助记符都是有规律的,可以看做英文缩写,所以还比较容易理解其含义。
**另外我再强调一下,**刚刚我让你生成汇编时,不要带优化参数,那是因为优化算法很“聪明”,它知道这个循环语句对函数最终的计算结果没什么用,就优化掉了。后面学优化算法时,你会理解这种优化机制。
不过这样做,也会有一个不好的影响,就是代码不够优化。比如这段代码把参数 1 拷贝到了栈里,在栈里做运算,而不是直接基于寄存器做运算,这样性能会低很多,这是没有做寄存器优化的结果。
示例 4:if 语句的汇编码解析
循环语句看过了,if 语句如何用汇编代码实现呢?
看看下面这段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
int fun1(int a){
if (a > 10){
return 4;
}
else{
return 8;
}
}
|
把上面的 C 语言代码转换成汇编代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
.section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 15
.globl _fun1 ## -- Begin function fun1
.p2align 4, 0x90
_fun1: ## @fun1
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl %edi, -8(%rbp)
cmpl $10, -8(%rbp) # 将参数 a 与 10 做比较
jle LBB0_2 # 小于等于的话就调转到 LBB0_2 基本块
## %bb.1:
movl $4, -4(%rbp) # 否则就给 a 赋值为 4
jmp LBB0_3
LBB0_2:
movl $8, -4(%rbp) # 给 a 赋值为 8
LBB0_3:
movl -4(%rbp), %eax # 设置返回值
popq %rbp
retq
.cfi_endproc
## -- End function
.subsections_via_symbols
|
了解了条件跳转指令以后,再理解上面的代码容易了很多。还是先做比较,设置 EFLAGS 中的位,然后做跳转。
示例 5:浮点数的使用
之前我们用的例子都是采用整数,现在使用浮点数来做运算,看看会有什么不同。
看看下面这段代码:
1
2
3
4
5
6
7
8
|
float fun1(float a, float b){
float c = 2.0;
return a + b + c;
}
|
使用 -O2 参数,把 C 语言的程序编译成汇编代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
.section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 15
.section __TEXT,__literal4,4byte_literals
.p2align 2 ## -- Begin function fun1
LCPI0_0:
.long 1073741824 ## float 2 常量
.section __TEXT,__text,regular,pure_instructions
.globl _fun1
.p2align 4, 0x90
_fun1: ## @fun1
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
addss %xmm1, %xmm0 # 浮点数传参用 XMM 寄存器,加法用 addss 指令
addss LCPI0_0(%rip), %xmm0 # 把常量 2.0 加到 xmm0 上,xmm0 保存返回值
popq %rbp
retq
.cfi_endproc
## -- End function
.subsections_via_symbols
|
这个代码的结构你应该熟悉了,栈帧的管理方式都是一样的,都要维护 %rbp 和 %rsp。不一样的地方,有几个地方:
- 传参。给函数传递浮点型参数,是要使用 XMM 寄存器。
- 指令。浮点数的加法运算,使用的是 addss 指令,它用于对单精度的标量浮点数做加法计算,这是一个 SSE1 指令。SSE1 是一组指令,主要是对单精度浮点数 (比如 C 或 Java 语言中的 float) 进行运算的,而 SSE2 则包含了一些双精度浮点数(比如 C 或 Java 语言中的 double)的运算指令。
- 返回值。整型返回值是放在 %eax 寄存器中,而浮点数返回值是放在 xmm0 寄存器中的。调用者可以从这里取出来使用。
课程小结
利用本节课的加餐,我带你把编程中常见的一些场景,所对应的汇编代码做了一些分析。你需要记住的要点如下:
- 函数调用时,会使用寄存器传参,超过 6 个参数时,还要再加上栈,这都是遵守了调用约定。
- 通过 push、pop 指令来使用栈,栈与 %rbp 和 %rsp 这两个指针有关。你可以图形化地记住栈的增长和回缩的过程。需要注意的是,是从高地址向低地址走,所以访问栈里的变量,都是基于 %rbp 来减某个值。使用 %rbp 前,要先保护起来,别破坏了调用者放在里面的值。
- 循环语句和 if 语句的秘密在于比较指令和有条件跳转指令,它们都用到了 EFLAGS 寄存器。
- 浮点数的计算要用到 MMX 寄存器,指令也有所不同。
通过这次加餐,你会更加直观地了解汇编语言,接下来的课程中,我会带你尝试通过翻译 AST 自动生成这些汇编代码,让你直观理解编译器生成汇编码的过程。
一课一思
你了解到哪些地方会使用汇编语言编程?有没有一些比较有意思的场景?是否实现了一些普通高级语言难以实现的结果?欢迎在留言区分享你的经验。
最后,感谢你的阅读,如果这篇文章让你有所收获,也欢迎你将它分享给更多的朋友。
