协议专栏特别福利|答疑解惑第三期
文章目录
你好,我是刘超。
第三期答疑涵盖第 7 讲至第 13 讲的内容。我依旧对课后思考题和留言中比较有代表性的问题作出回答。你可以点击文章名,回到对应的章节复习,也可以继续在留言区写下你的疑问,我会持续不断地解答。希望对你有帮助。
《第 7 讲 | ICMP 与 ping:投石问路的侦察兵》
课后思考题
当发送的报文出问题的时候,会发送一个 ICMP 的差错报文来报告错误,但是如果 ICMP 的差错报文也出问题了呢?
我总结了一下,不会导致产生 ICMP 差错报文的有:
- ICMP 差错报文(ICMP 查询报文可能会产生 ICMP 差错报文);
- 目的地址是广播地址或多播地址的 IP 数据报;
- 作为链路层广播的数据报;
- 不是 IP 分片的第一片;
- 源地址不是单个主机的数据报。这就是说,源地址不能为零地址、环回地址、广播地址或多播地址。
留言问题
1.ping 使用的是什么网络编程接口?

咱们使用的网络编程接口是 Socket,对于 ping 来讲,使用的是 ICMP,创建 Socket 如下:
|
|
SOCK_RAW 就是基于 IP 层协议建立通信机制。
如果是 TCP,则建立下面的 Socket:
|
|
如果是 UDP,则建立下面的 Socket:
|
|
2.ICMP 差错报文是谁发送的呢?
我看留言里有很多人对这个问题有疑惑。ICMP 包是由内核返回的,在内核中,有一个函数用于发送 ICMP 的包。
|
|
例如,目标不可达,会调用下面的函数。
|
|
当 IP 大小超过 MTU 的时候,发送需要分片的 ICMP。
|
|
《第 8 讲 | 世界这么大,我想出网关:欧洲十国游与玄奘西行》
课后思考题
当在你家里要访问 163 网站的时候,你的包需要 NAT 成为公网 IP,返回的包又要 NAT 成你的私有 IP,返回包怎么知道这是你的请求呢?它怎么能这么智能的 NAT 成了你的 IP 而非别人的 IP 呢?
这是个比较复杂的事情。在讲云中网络安全里的 iptables 时,我们讲过 conntrack 功能,它记录了 SNAT 一去一回的对应关系。
如果编译内核时开启了连接跟踪选项,那么 Linux 系统就会为它收到的每个数据包维持一个连接状态,用于记录这条数据连接的状态。
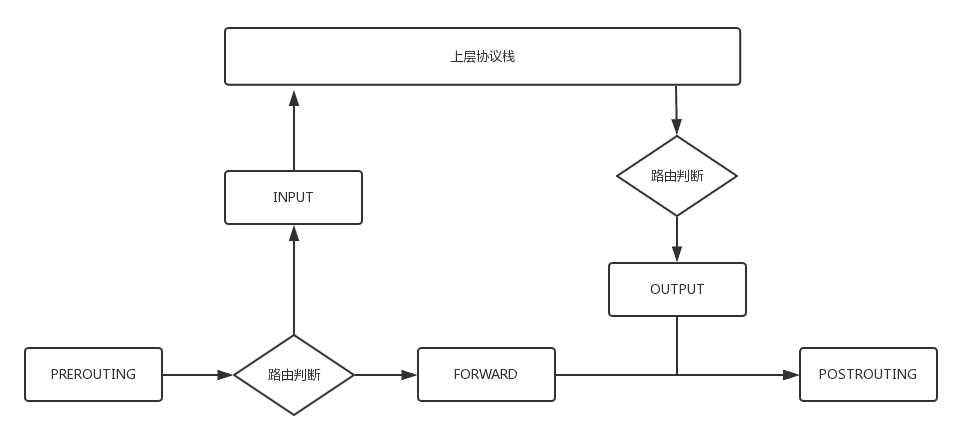
根据咱们学过的 Netfilter 的流程图,我们知道,网络包有三种路径:
- 发给我的,从 PREROUTING 到 INPUT,我就接收了;
- 我发给别人的,从 OUTPUT 到 POSTROUTING,就发出去的;
- 从我这里经过的,从 PREROUTING 到 FORWARD 到 POSTROUTING。
如果要跟踪一个网络包,对于每一种路径,都需要设置两个记录点,相当于打两次卡,这样内核才知道这个包的状态。
对于这三种路径,打卡的点是这样设置的:
- 发给我的,在 PREROUTING 调用 ipv4_conntrack_in,创建连接跟踪记录;在 INPUT 调用 ipv4_confirm,将这个连接跟踪记录挂在内核的连接跟踪表里面。为什么不一开始就挂在内核的连接跟踪表里面呢?因为有 filter 表,一旦把包过滤了,也就是丢弃了,那根本没必要记录这个连接了。
- 我发给别人的,在 OUTPUT 调用 ipv4_conntrack_local,创建连接跟踪记录,在 POSTROUTING 调用 ipv4_confirm,将这个连接跟踪记录挂在内核的连接跟踪表里面。
- 从我这里经过的,在 PREROUTING 调用 ipv4_conntrack_in,创建连接跟踪记录,在 POSTROUTING 调用 ipv4_confirm,将这个连接跟踪记录挂在内核的连接跟踪表里面。
网关主要做转发,这里主要说的是 NAT 网关,因而我们重点来看“从我这里经过的”这种场景,再加上要 NAT,因而将 NAT 的过程融入到连接跟踪的过程中来:
- 如果是 PREROUTING 的时候,先调用 ipv4_conntrack_in,创建连接跟踪记录;
- 如果是 PREROUTING 的时候,有 NAT 规则,则调用 nf_nat_ipv4_in 进行地址转换;
- 如果是 POSTROUTING 的时候,有 NAT 规则,则调用 nf_nat_ipv4_out 进行地址转换;
- 如果是 POSTROUTING 的时候,调用 ipv4_confirm,将这个连接跟踪记录挂在内核的连接跟踪表里面。
接下来,我们来看,在这个过程中涉及到的数据结构:连接跟踪记录、连接跟踪表。
在前面讲网络包处理的时候,我们说过,每个网络包都是一个 struct sk_buff,它有一个成员变量 _nfct 指向一个连接跟踪记录 struct nf_conn。当然当一个网络包刚刚进来的时候,是不会指向这么一个结构的,但是这个网络包肯定属于某个连接,因而会去连接跟踪表里面去查找,之后赋值给 sk_buff 的这个成员变量。没找到的话,就说明是一个新的连接,然后会重新创建一个。
连接跟踪记录里面有几个重要的东西:
- nf_conntrack 其实才是 _nfct 变量指向的地址,但是没有关系,学过 C++ 的话应该明白,对于结构体来讲,nf_conn 和 nf_conntrack 的起始地址是一样的;
- tuplehash 虽然是数组,但是里面只有两个,IP_CT_DIR_ORIGINAL 为下标 0,表示连接的发起方向,IP_CT_DIR_REPLY 为下标 1,表示连接的回复方向。
|
|
在这里面,最重要的是 nf_conntrack_tuple_hash 的数组。nf_conn 是这个网络包对应的一去一回的连接追踪记录,但是这个记录是会放在一个统一的连接追踪表里面的。
连接跟踪表 nf_conntrack_hash 是一个数组,数组中的每一项都是一个双向链表的头,每一项后面都挂着一个双向链表,链表中的每一项都是这个结构。
这个结构的第一项是链表的链,nf_conntrack_tuple 是用来标识是否同一个连接。
从上面可以看出来,连接跟踪表是一个典型的链式哈希表的实现。
每当有一个网络包来了的时候,会将网络包中 sk_buff 中的数据提取出来,形成 nf_conntrack_tuple,并根据里面的内容计算哈希值。然后需要在哈希表中查找,如果找到,则说明这个连接出现过;如果没找到,则生成一个插入哈希表。
通过 nf_conntrack_tuple 里面的内容,可以唯一地标识一个连接:
- src:包含源 IP 地址;如果是 TCP 或者 UDP,包含源端口;如果是 ICMP,包含的是 ID;
- dst:包含目标 IP 地址;如果是 TCP 或者 UDP,包含目标端口;如果是 ICMP,包含的是 type, code。
有了这些数据结构,我们接下来看这一去一回的过程。
当一个包发出去的时候,到达这个 NAT 网关的时候,首先经过 PREROUTING 的时候,先调用 ipv4_conntrack_in。这个时候进来的包 sk_buff 为: {源 IP:客户端 IP,源端口:客户端 port,目标 IP:服务端 IP,目标端口:服务端 port},将这个转换为 nf_conntrack_tuple,然后经过哈希运算,在连接跟踪表里面查找,发现没有,说明这是一个新的连接。
于是,创建一个新的连接跟踪记录 nf_conn,这里面有两个 nf_conntrack_tuple_hash:
- 一去:{源 IP:客户端 IP,源端口:客户端 port,目标 IP:服务端 IP,目标端口:服务端 port};
- 一回:{源 IP:服务端 IP,源端口:服务端 port,目标 IP:客户端 IP,目标端口:客户端 port}。
接下来经过 FORWARD 过程,假设包没有被 filter 掉,于是要转发出去,进入 POSTROUTING 的过程,有 NAT 规则,则调用 nf_nat_ipv4_out 进行地址转换。这个时候,源地址要变成 NAT 网关的 IP 地址,对于 masquerade 来讲,会自动选择一个公网 IP 地址和一个随机端口。
为了让包回来的时候,能找到连接跟踪记录,需要修改两个 nf_conntrack_tuple_hash 中回来的那一项为:{源 IP:服务端 IP,源端口:服务端 port,目标 IP:NAT 网关 IP,目标端口:随机端口}。
接下来要将网络包真正发出去的时候,除了要修改包里面的源 IP 和源端口之外,还需要将刚才的一去一回的两个 nf_conntrack_tuple_hash 放入连接跟踪表这个哈希表中。
当网络包到达服务端,然后回复一个包的时候,这个包 sk_buff 为:{源 IP:服务端 IP,源端口:服务端 port,目标 IP:NAT 网关 IP,目标端口:随机端口}。
将这个转换为 nf_conntrack_tuple 后,进行哈希运算,在连接跟踪表里面查找,是能找到相应的记录的,找到 nf_conntrack_tuple_hash 之后,Linux 会提供一个函数。
|
|
可以通过 nf_conntrack_tuple_hash 找到外面的连接跟踪记录 nf_conn,通过这个可以找到来方向的那个 nf_conntrack_tuple_hash,{源 IP:客户端 IP,源端口:客户端 port,目标 IP:服务端 IP,目标端口:服务端 port},这样就能够找到客户端的 IP 和端口,从而可以 NAT 回去。
留言问题
1.NAT 能建立多少连接?

SNAT 多用于内网访问外网的场景,鉴于 conntrack 是由{源 IP,源端口,目标 IP,目标端口},hash 后确定的。
如果内网机器很多,但是访问的是不同的外网,也即目标 IP 和目标端口很多,这样内网可承载的数量就非常大,可不止 65535 个。
但是如果内网所有的机器,都一定要访问同一个目标 IP 和目标端口,这样源 IP 如果只有一个,这样的情况下,才受 65535 的端口数目限制,根据原理,一种方法就是多个源 IP,另外的方法就是多个 NAT 网关,来分摊不同的内网机器访问。
如果你使用的是公有云,65535 台机器,应该放在一个 VPC 里面,可以放在多个 VPC 里面,每个 VPC 都可以有自己的 NAT 网关。

其实 SNAT 的场景是内网访问外网,存在端口数量的问题,也是所有的机器都访问一个目标地址的情况。
如果是微信这种场景,应该是服务端在数据中心内部,无论多少长连接,作为服务端监听的都是少数几个端口,是 DNAT 的场景,是没有端口数目问题的,只有一台服务器能不能维护这么多连接,因而在 NAT 网关后面部署多个 nginx 来分摊连接即可。
2. 公网 IP 和私网 IP 需要一一绑定吗?

公网 IP 是有限的,如果使用公有云,需要花钱去买。但是不是每一个虚拟机都要有一个公网 IP 的,只有需要对外提供服务的机器,也即接入层的那些 nginx 需要公网 IP,没有公网 IP,使用 SNAT,大家共享 SNAT 网关的公网 IP 地址,也是能够访问的外网的。
我看留言中的困惑点都在于,要区分内主动发起访问外,还是外主动发起访问内,是访问同一个服务端,还是访问一大批服务端。这里就很明白了。
《第 9 讲 | 路由协议:西出网关无故人,敢问路在何方》
课后思考题
路由协议要在路由器之间交换信息,这些信息的交换还需要走路由吗?不是死锁了吗?

OSPF 是直接基于 IP 协议发送的,而且 OSPF 的包都是发给邻居的,也即只有一跳,不会中间经过路由设备。BGP 是基于 TCP 协议的,在 BGP peer 之间交换信息。
留言问题
1. 多线 BGP 机房是怎么回事儿?

BGP 主要用于互联网 AS 自治系统之间的互联,BGP 的最主要功能在于控制路由的传播和选择最好的路由。各大运营商都具有 AS 号,全国各大网络运营商多数都是通过 BGP 协议与自身的 AS 来实现多线互联的。
使用此方案来实现多线路互联,IDC 需要在 CNNIC(中国互联网信息中心)或 APNIC(亚太网络信息中心)申请自己的 IP 地址段和 AS 号,然后通过 BGP 协议将此段 IP 地址广播到其它的网络运营商的网络中。
使用 BGP 协议互联后,网络运营商的所有骨干路由设备将会判断到 IDC 机房 IP 段的最佳路由,以保证不同网络运营商用户的高速访问。
《第 10 讲 | UDP 协议:因性善而简单,难免碰到“城会玩”》
课后思考题
都说 TCP 是面向连接的,在计算机看来,怎么样才算一个连接呢?
赵强强在留言中回答的是正确的。这是 TCP 的两端为了维护连接所保持的数据结构。


《第 11 讲 | TCP 协议(上):因性恶而复杂,先恶后善反轻松》
课后思考题
TCP 的连接有这么多的状态,你知道如何在系统中查看某个连接的状态吗?

留言问题
1.TIME_WAIT 状态太多是怎么回事儿?

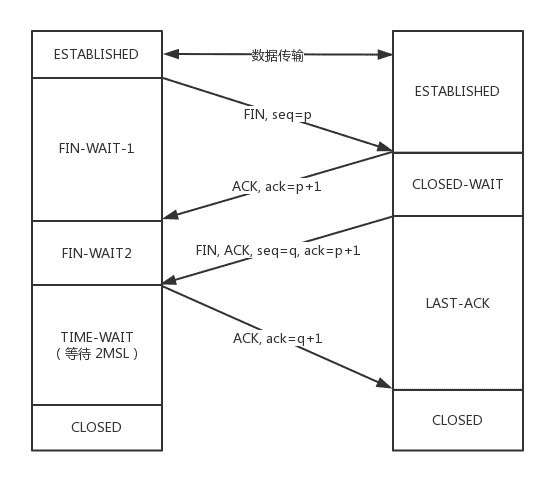
如果处于 TIMEWAIT 状态,说明双方建立成功过连接,而且已经发送了最后的 ACK 之后,才会处于这个状态,而且是主动发起关闭的一方处于这个状态。
如果存在大量的 TIMEWAIT,往往是因为短连接太多,不断的创建连接,然后释放连接,从而导致很多连接在这个状态,可能会导致无法发起新的连接。解决的方式往往是:
- 打开 tcp_tw_recycle 和 tcp_timestamps 选项;
- 打开 tcp_tw_reuse 和 tcp_timestamps 选项;
- 程序中使用 SO_LINGER,应用强制使用 rst 关闭。
当客户端收到 Connection Reset,往往是收到了 TCP 的 RST 消息,RST 消息一般在下面的情况下发送:
- 试图连接一个未被监听的服务端;
- 对方处于 TIMEWAIT 状态,或者连接已经关闭处于 CLOSED 状态,或者重新监听 seq num 不匹配;
- 发起连接时超时,重传超时,keepalive 超时;
- 在程序中使用 SO_LINGER,关闭连接时,放弃缓存中的数据,给对方发送 RST。
2. 起始序列号是怎么计算的,会冲突吗?
有同学在留言中问了几个问题。Ender0224 的回答非常不错。


起始 ISN 是基于时钟的,每 4 毫秒加一,转一圈要 4.55 个小时。
TCP 初始化序列号不能设置为一个固定值,因为这样容易被攻击者猜出后续序列号,从而遭到攻击。RFC1948 中提出了一个较好的初始化序列号 ISN 随机生成算法。
ISN = M + F (localhost, localport, remotehost, remoteport)
M 是一个计时器,这个计时器每隔 4 毫秒加 1。F 是一个 Hash 算法,根据源 IP、目的 IP、源端口、目的端口生成一个随机数值。要保证 Hash 算法不能被外部轻易推算得出,用 MD5 算法是一个比较好的选择。
《第 12 讲 | TCP 协议(下):西行必定多妖孽,恒心智慧消磨难》
课后思考题
TCP 的 BBR 听起来很牛,你知道它是如何达到这个最优点的嘛?

《第 13 讲 | 套接字 Socket:Talk is cheap, show me the code》
课后思考题
epoll 是 Linux 上的函数,那你知道 Windows 上对应的机制是什么吗?如果想实现一个跨平台的程序,你知道应该怎么办吗?

epoll 是异步通知,当事件发生的时候,通知应用去调用 IO 函数获取数据。IOCP 异步传输,当事件发生时,IOCP 机制会将数据直接拷贝到缓冲区里,应用可以直接使用。
如果跨平台,推荐使用 libevent 库,它是一个事件通知库,适用于 Windows、Linux、BSD 等多种平台,内部使用 select、epoll、kqueue、IOCP 等系统调用管理事件机制。
感谢第 7 讲至第 13 讲中对内容有深度思考和提出问题的同学。我会为你们送上奖励礼券和知识图谱。(稍后运营同学会发送短信通知。)
欢迎你继续提问!


文章作者 anonymous
上次更新 2024-04-16