08|内核初始化:生意做大了就得成立公司
文章目录
上一节,你获得了一本《企业经营宝典》,完成了一件大事,切换到了老板角色,从实模式切换到了保护模式。有了更强的寻址能力,接下来,我们就要按照宝典里面的指引,开始经营企业了。
内核的启动从入口函数 start_kernel() 开始。在 init/main.c 文件中,start_kernel 相当于内核的 main 函数。打开这个函数,你会发现,里面是各种各样初始化函数 XXXX_init。
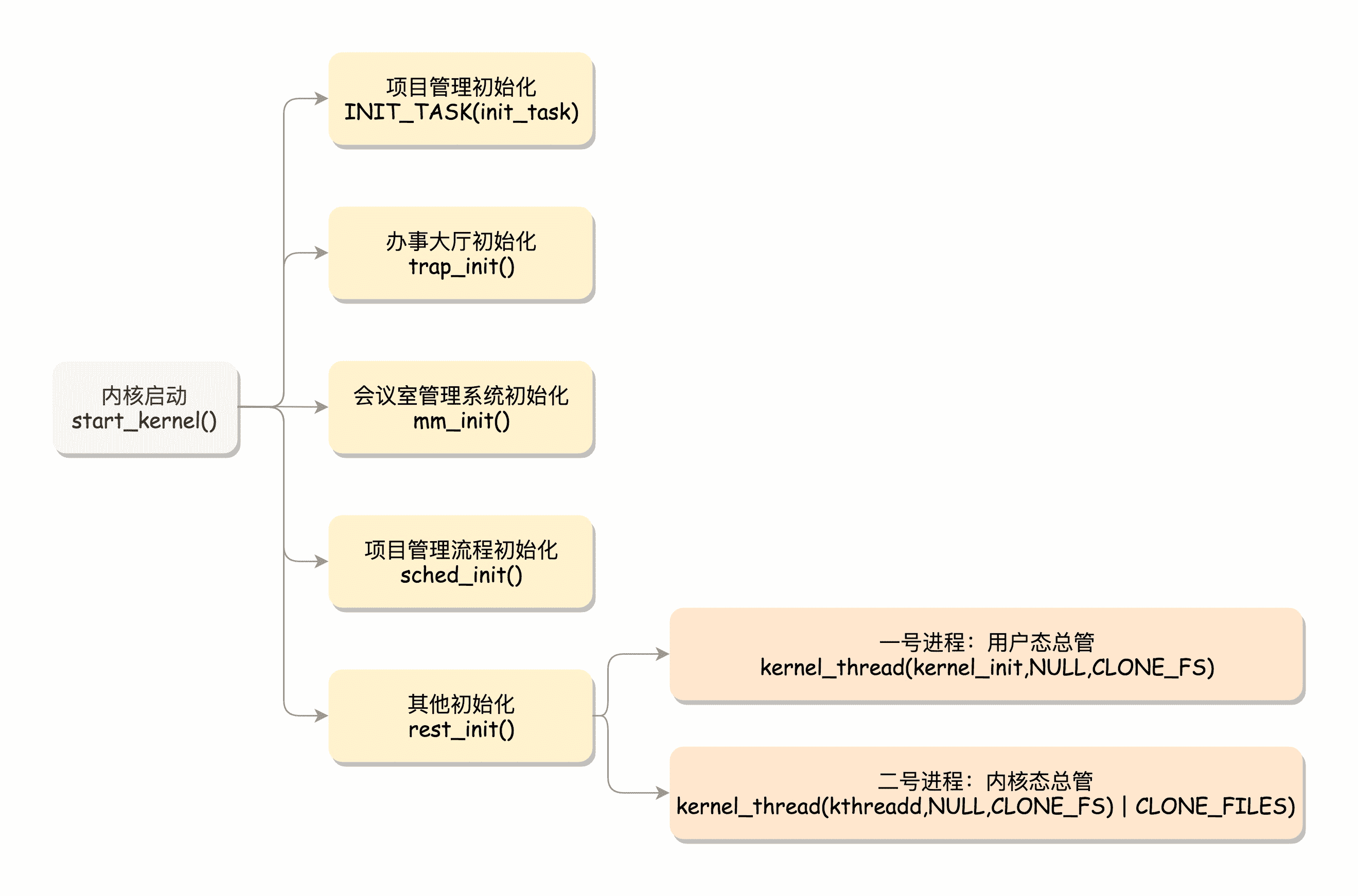
初始化公司职能部门
于是,公司要开始建立各种职能部门了。
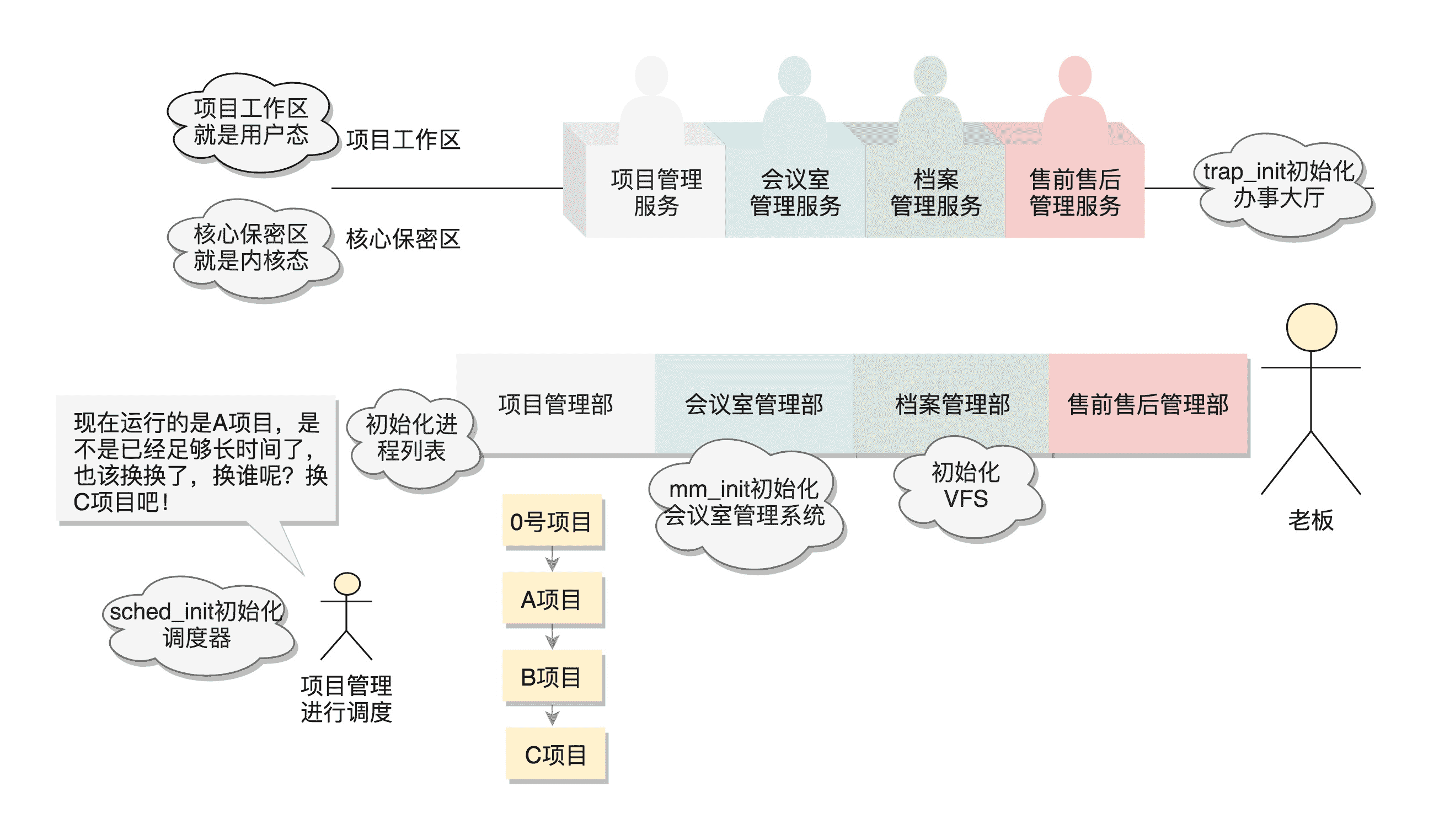
首先是项目管理部门。咱们将来肯定要接各种各样的项目,因此,项目管理体系和项目管理流程首先要建立起来。之前讲的创建项目都是复制老项目,现在咱们需要有第一个全新的项目。这个项目需要你这个老板来打个样。
在操作系统里面,先要有个创始进程,有一行指令 set_task_stack_end_magic(&init_task)。这里面有一个参数 init_task,它的定义是 struct task_struct init_task = INIT_TASK(init_task)。它是系统创建的第一个进程,我们称为0 号进程。这是唯一一个没有通过 fork 或者 kernel_thread 产生的进程,是进程列表的第一个。
所谓进程列表(Procese List),就是咱们前面说的项目管理工具,里面列着我们所有接的项目。
第二个要初始化的就是办事大厅。有了办事大厅,我们就可以响应客户的需求。
这里面对应的函数是 trap_init(),里面设置了很多中断门(Interrupt Gate),用于处理各种中断。其中有一个 set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32),这是系统调用的中断门。系统调用也是通过发送中断的方式进行的。当然,64 位的有另外的系统调用方法,这一点我们放到后面的系统调用章节详细谈。
接下来要初始化的是咱们的会议室管理系统。对应的,mm_init() 就是用来初始化内存管理模块。
项目需要项目管理进行调度,需要执行一定的调度策略。sched_init() 就是用于初始化调度模块。
vfs_caches_init() 会用来初始化基于内存的文件系统 rootfs。在这个函数里面,会调用 mnt_init()->init_rootfs()。这里面有一行代码,register_filesystem(&rootfs_fs_type)。在 VFS 虚拟文件系统里面注册了一种类型,我们定义为 struct file_system_type rootfs_fs_type。
文件系统是我们的项目资料库,为了兼容各种各样的文件系统,我们需要将文件的相关数据结构和操作抽象出来,形成一个抽象层对上提供统一的接口,这个抽象层就是 VFS(Virtual File System),虚拟文件系统。
这里的 rootfs 还有其他用处,下面我们会用到。
最后,start_kernel() 调用的是 rest_init(),用来做其他方面的初始化,这里面做了好多的工作。
初始化 1 号进程
rest_init 的第一大工作是,用 kernel_thread(kernel_init, NULL, CLONE_FS) 创建第二个进程,这个是1 号进程。
1 号进程对于操作系统来讲,有“划时代”的意义。因为它将运行一个用户进程,这意味着这个公司把一个老板独立完成的制度,变成了可以交付他人完成的制度。这个 1 号进程就相当于老板带了一个大徒弟,有了第一个,就有第二个,后面大徒弟开枝散叶,带了很多徒弟,形成一棵进程树。
一旦有了用户进程,公司的运行模式就要发生一定的变化。因为原来你是老板,没有雇佣其他人,所有东西都是你的,无论多么关键的资源,第一,不会有人给你抢,第二,不会有人恶意破坏、恶意使用。
但是现在有了其他人,你就要开始做一定的区分,哪些是核心资源,哪些是非核心资源;办公区也要分开,有普通的项目人员都能访问的项目工作区,还有职业核心人员能够访问的核心保密区。
好在 x86 提供了分层的权限机制,把区域分成了四个 Ring,越往里权限越高,越往外权限越低。

操作系统很好地利用了这个机制,将能够访问关键资源的代码放在 Ring0,我们称为内核态(Kernel Mode);将普通的程序代码放在 Ring3,我们称为用户态(User Mode)。
你别忘了,现在咱们的系统已经处于保护模式了,保护模式除了可访问空间大一些,还有另一个重要功能,就是“保护”,也就是说,当处于用户态的代码想要执行更高权限的指令,这种行为是被禁止的,要防止他们为所欲为。
如果用户态的代码想要访问核心资源,怎么办呢?咱们不是有提供系统调用的办事大厅吗?这里是统一的入口,用户态代码在这里请求就是了。办事大厅后面就是内核态,用户态代码不用管后面发生了什么,做完了返回结果就可以了。
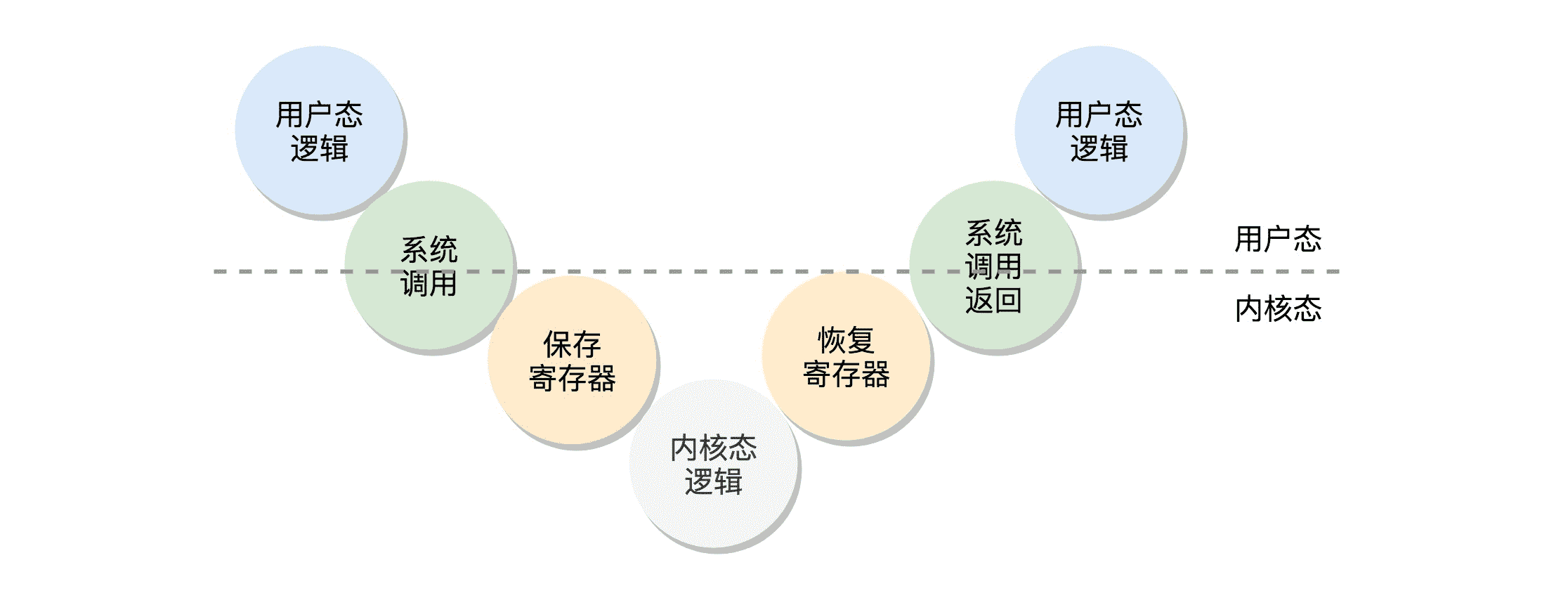
当一个用户态的程序运行到一半,要访问一个核心资源,例如访问网卡发一个网络包,就需要暂停当前的运行,调用系统调用,接下来就轮到内核中的代码运行了。
首先,内核将从系统调用传过来的包,在网卡上排队,轮到的时候就发送。发送完了,系统调用就结束了,返回用户态,让暂停运行的程序接着运行。
这个暂停怎么实现呢?其实就是把程序运行到一半的情况保存下来。例如,我们知道,内存是用来保存程序运行时候的中间结果的,现在要暂时停下来,这些中间结果不能丢,因为再次运行的时候,还要基于这些中间结果接着来。另外就是,当前运行到代码的哪一行了,当前的栈在哪里,这些都是在寄存器里面的。
所以,暂停的那一刻,要把当时 CPU 的寄存器的值全部暂存到一个地方,这个地方可以放在进程管理系统很容易获取的地方。在后面讨论进程管理数据结构的时候,我们还会详细讲。当系统调用完毕,返回的时候,再从这个地方将寄存器的值恢复回去,就能接着运行了。

这个过程就是这样的:用户态 - 系统调用 - 保存寄存器 - 内核态执行系统调用 - 恢复寄存器 - 返回用户态,然后接着运行。
从内核态到用户态
我们再回到 1 号进程启动的过程。当前执行 kernel_thread 这个函数的时候,我们还在内核态,现在我们就来跨越这道屏障,到用户态去运行一个程序。这该怎么办呢?很少听说“先内核态再用户态”的。
kernel_thread 的参数是一个函数 kernel_init,也就是这个进程会运行这个函数。在 kernel_init 里面,会调用 kernel_init_freeable(),里面有这样的代码:
|
|
先不管 ramdisk 是啥,我们回到 kernel_init 里面。这里面有这样的代码块:
|
|
这就说明,1 号进程运行的是一个文件。如果我们打开 run_init_process 函数,会发现它调用的是 do_execve。
这个名字是不是看起来很熟悉?前面讲系统调用的时候,execve 是一个系统调用,它的作用是运行一个执行文件。加一个 do_ 的往往是内核系统调用的实现。没错,这就是一个系统调用,它会尝试运行 ramdisk 的“/init”,或者普通文件系统上的“/sbin/init”“/etc/init”“/bin/init”“/bin/sh”。不同版本的 Linux 会选择不同的文件启动,但是只要有一个起来了就可以。
|
|
如何利用执行 init 文件的机会,从内核态回到用户态呢?
我们从系统调用的过程可以得到启发,“用户态 - 系统调用 - 保存寄存器 - 内核态执行系统调用 - 恢复寄存器 - 返回用户态”,然后接着运行。而咱们刚才运行 init,是调用 do_execve,正是上面的过程的后半部分,从内核态执行系统调用开始。
do_execve->do_execveat_common->exec_binprm->search_binary_handler,这里面会调用这段内容:
|
|
也就是说,我要运行一个程序,需要加载这个二进制文件,这就是我们常说的项目执行计划书。它是有一定格式的。Linux 下一个常用的格式是ELF(Executable and Linkable Format,可执行与可链接格式)。于是我们就有了下面这个定义:
|
|
这其实就是先调用 load_elf_binary,最后调用 start_thread。
|
|
看到这里,你是不是有点感觉了?struct pt_regs,看名字里的 register,就是寄存器啊!这个结构就是在系统调用的时候,内核中保存用户态运行上下文的,里面将用户态的代码段 CS 设置为 __USER_CS,将用户态的数据段 DS 设置为 __USER_DS,以及指令指针寄存器 IP、栈指针寄存器 SP。这里相当于补上了原来系统调用里,保存寄存器的一个步骤。
最后的 iret 是干什么的呢?它是用于从系统调用中返回。这个时候会恢复寄存器。从哪里恢复呢?按说是从进入系统调用的时候,保存的寄存器里面拿出。好在上面的函数补上了寄存器。CS 和指令指针寄存器 IP 恢复了,指向用户态下一个要执行的语句。DS 和函数栈指针 SP 也被恢复了,指向用户态函数栈的栈顶。所以,下一条指令,就从用户态开始运行了。
ramdisk 的作用
init 终于从内核到用户态了。一开始到用户态的是 ramdisk 的 init,后来会启动真正根文件系统上的 init,成为所有用户态进程的祖先。
为什么会有 ramdisk 这个东西呢?还记得上一节咱们内核启动的时候,配置过这个参数:
|
|
就是这个东西,这是一个基于内存的文件系统。为啥会有这个呢?
是因为刚才那个 init 程序是在文件系统上的,文件系统一定是在一个存储设备上的,例如硬盘。Linux 访问存储设备,要有驱动才能访问。如果存储系统数目很有限,那驱动可以直接放到内核里面,反正前面我们加载过内核到内存里了,现在可以直接对存储系统进行访问。
但是存储系统越来越多了,如果所有市面上的存储系统的驱动都默认放进内核,内核就太大了。这该怎么办呢?
我们只好先弄一个基于内存的文件系统。内存访问是不需要驱动的,这个就是 ramdisk。这个时候,ramdisk 是根文件系统。
然后,我们开始运行 ramdisk 上的 /init。等它运行完了就已经在用户态了。/init 这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk 上的 /init 会启动文件系统上的 init。
接下来就是各种系统的初始化。启动系统的服务,启动控制台,用户就可以登录进来了。
先别忙着高兴,rest_init 的第一个大事情才完成。我们仅仅形成了用户态所有进程的祖先。
创建 2 号进程
用户态的所有进程都有大师兄了,那内核态的进程有没有一个人统一管起来呢?有的,rest_init 第二大事情就是第三个进程,就是 2 号进程。
kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES) 又一次使用 kernel_thread 函数创建进程。这里需要指出一点,函数名 thread 可以翻译成“线程”,这也是操作系统很重要的一个概念。它和进程有什么区别呢?为什么这里创建的是进程,函数名却是线程呢?
从用户态来看,创建进程其实就是立项,也就是启动一个项目。这个项目包含很多资源,例如会议室、资料库等。这些东西都属于这个项目,但是这个项目需要人去执行。有多个人并行执行不同的部分,这就叫多线程(Multithreading)。如果只有一个人,那它就是这个项目的主线程。
但是从内核态来看,无论是进程,还是线程,我们都可以统称为任务(Task),都使用相同的数据结构,平放在同一个链表中。这些在进程的那一章节,我会更加详细地讲。
这里的函数 kthreadd,负责所有内核态的线程的调度和管理,是内核态所有线程运行的祖先。
这下好了,用户态和内核态都有人管了,可以开始接项目了。
总结时刻
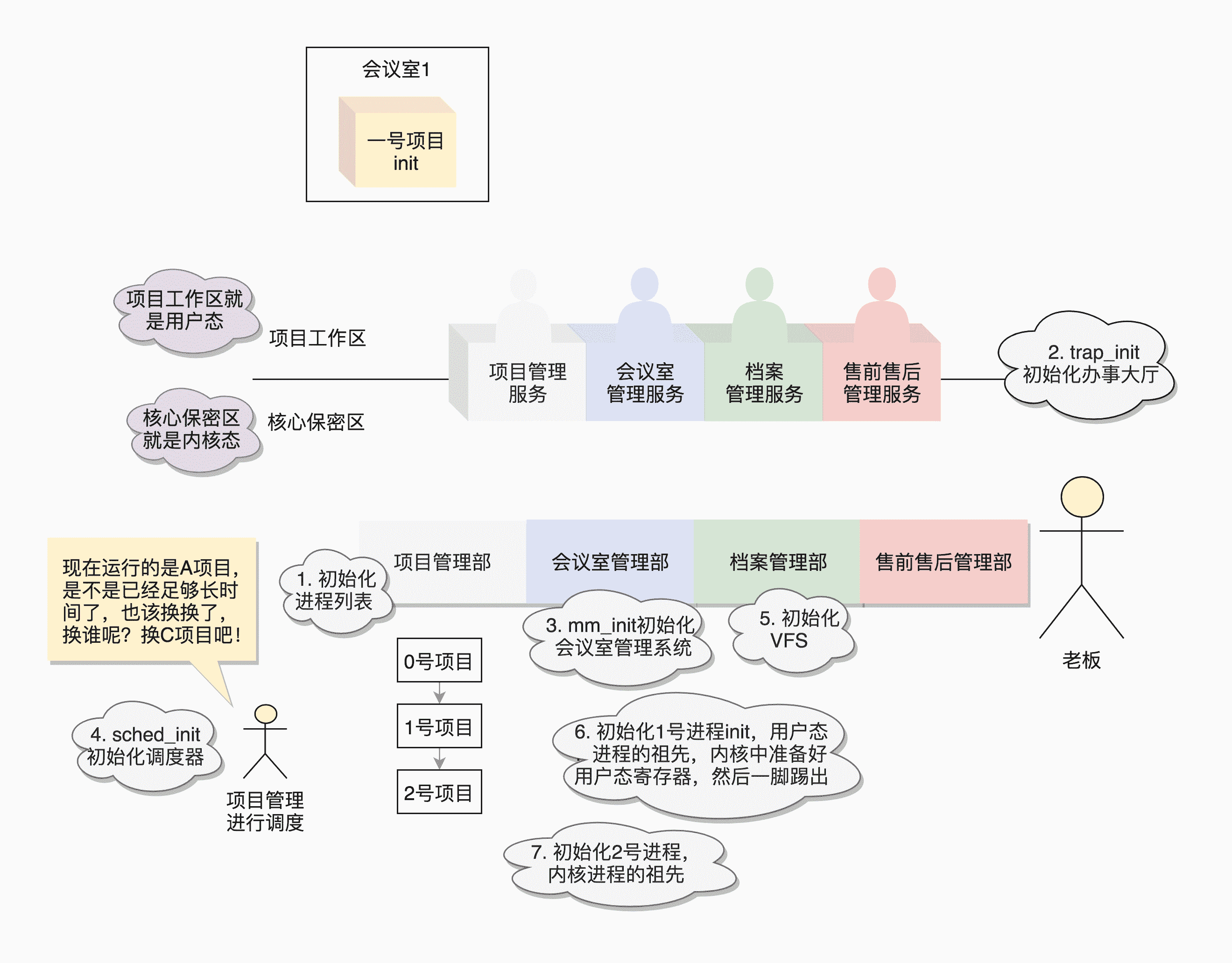
这一节,我们讲了内核的初始化过程,主要做了以下几件事情:
- 各个职能部门的创建;
- 用户态祖先进程的创建;
- 内核态祖先进程的创建。
咱们还是用一个图来总结一下这个过程。
课堂练习
这一节,我们看到内核创建了一些进程,这些进程都是放在一个列表中的,请你研读内核代码,看看这个列表是如何实现的。
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。

文章作者 anonymous
上次更新 2024-04-12