28|硬盘文件系统:如何最合理地组织档案库的文档?
文章目录
上一节,我们按照图书馆的模式,规划了档案库,也即文件系统应该有的样子。这一节,我们将这个模式搬到硬盘上来看一看。

我们常见的硬盘是上面这幅图左边的样子,中间圆的部分是磁盘的盘片,右边的图是抽象出来的图。每一层里分多个磁道,每个磁道分多个扇区,每个扇区是 512 个字节。
文件系统就是安装在这样的硬盘之上。这一节我们重点目前 Linux 下最主流的文件系统格式——ext 系列的文件系统的格式。
inode 与块的存储
就像图书馆的书架都要分成大小相同的格子,硬盘也是一样的。硬盘分成相同大小的单元,我们称为块(Block)。一块的大小是扇区大小的整数倍,默认是 4K。在格式化的时候,这个值是可以设定的。
一大块硬盘被分成了一个个小的块,用来存放文件的数据部分。这样一来,如果我们像存放一个文件,就不用给他分配一块连续的空间了。我们可以分散成一个个小块进行存放。这样就灵活得多,也比较容易添加、删除和插入数据。
但是这也带来一个新的问题,那就是文件的数据存放得太散,找起来就比较困难。有什么办法解决呢?我们是不是可以像图书馆那样,也设立一个索引区域,用来维护“某个文件分成几块、每一块在哪里“等等这些基本信息?
另外,文件还有元数据部分,例如名字、权限等,这就需要一个结构inode来存放。
什么是 inode 呢?inode 的“i”是 index 的意思,其实就是“索引”,类似图书馆的索引区域。既然如此,我们每个文件都会对应一个 inode;一个文件夹就是一个文件,也对应一个 inode。
至于 inode 里面有哪些信息,其实我们在内核中就有定义。你可以看下面这个数据结构。
|
|
从这个数据结构中,我们可以看出,inode 里面有文件的读写权限 i_mode,属于哪个用户 i_uid,哪个组 i_gid,大小是多少 i_size_io,占用多少个块 i_blocks_io。咱们讲 ls 命令行的时候,列出来的权限、用户、大小这些信息,就是从这里面取出来的。
另外,这里面还有几个与文件相关的时间。i_atime 是 access time,是最近一次访问文件的时间;i_ctime 是 change time,是最近一次更改 inode 的时间;i_mtime 是 modify time,是最近一次更改文件的时间。
这里你需要注意区分几个地方。首先,访问了,不代表修改了,也可能只是打开看看,就会改变 access time。其次,修改 inode,有可能修改的是用户和权限,没有修改数据部分,就会改变 change time。只有数据也修改了,才改变 modify time。
我们刚才说的“某个文件分成几块、每一块在哪里”,这些在 inode 里面,应该保存在 i_block 里面。
具体如何保存的呢?EXT4_N_BLOCKS 有如下的定义,计算下来一共有 15 项。
|
|
在 ext2 和 ext3 中,其中前 12 项直接保存了块的位置,也就是说,我们可以通过 i_block[0-11],直接得到保存文件内容的块。
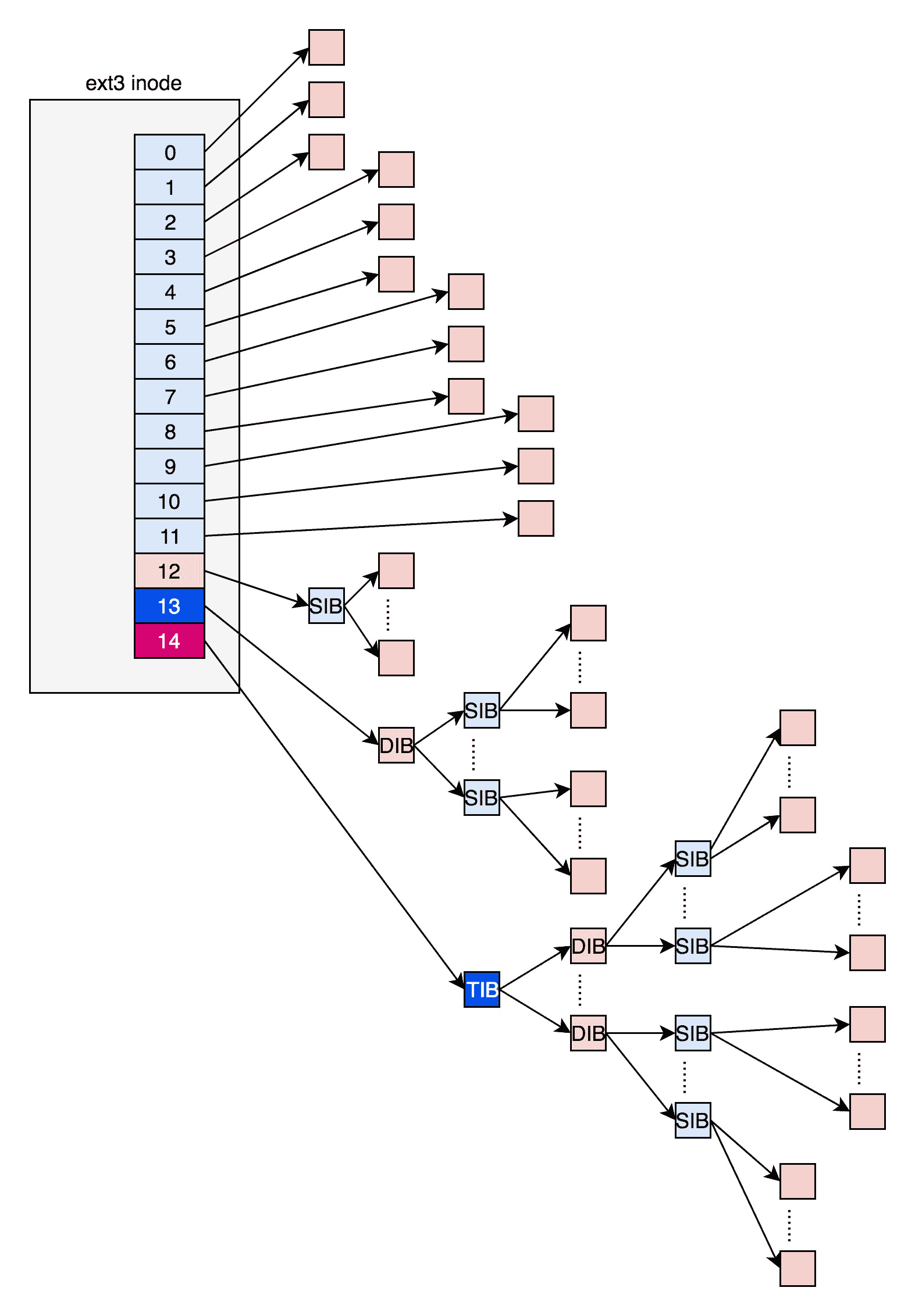
但是,如果一个文件比较大,12 块放不下。当我们用到 i_block[12] 的时候,就不能直接放数据块的位置了,要不然 i_block 很快就会用完了。这该怎么办呢?我们需要想个办法。我们可以让 i_block[12] 指向一个块,这个块里面不放数据块,而是放数据块的位置,这个块我们称为间接块。也就是说,我们在 i_block[12] 里面放间接块的位置,通过 i_block[12] 找到间接块后,间接块里面放数据块的位置,通过间接块可以找到数据块。
如果文件再大一些,i_block[13] 会指向一个块,我们可以用二次间接块。二次间接块里面存放了间接块的位置,间接块里面存放了数据块的位置,数据块里面存放的是真正的数据。如果文件再大一些,i_block[14] 会指向三次间接块。原理和上面都是一样的,就像一层套一层的俄罗斯套娃,一层一层打开,才能拿到最中心的数据块。
如果你稍微有点经验,现在你应该能够意识到,这里面有一个非常显著的问题,对于大文件来讲,我们要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。
为了解决这个问题,ext4 做了一定的改变。它引入了一个新的概念,叫作Extents。
我们来解释一下 Extents。比方说,一个文件大小为 128M,如果使用 4k 大小的块进行存储,需要 32k 个块。如果按照 ext2 或者 ext3 那样散着放,数量太大了。但是 Extents 可以用于存放连续的块,也就是说,我们可以把 128M 放在一个 Extents 里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了。
Exents 如何来存储呢?它其实会保存成一棵树。

树有一个个的节点,有叶子节点,也有分支节点。每个节点都有一个头,ext4_extent_header 可以用来描述某个节点。
|
|
我们仔细来看里面的内容。eh_entries 表示这个节点里面有多少项。这里的项分两种,如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点 ext4_extent;如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点 ext4_extent_idx。这两种类型的项的大小都是 12 个 byte。
|
|
如果文件不大,inode 里面的 i_block 中,可以放得下一个 ext4_extent_header 和 4 项 ext4_extent。所以这个时候,eh_depth 为 0,也即 inode 里面的就是叶子节点,树高度为 0。
如果文件比较大,4 个 extent 放不下,就要分裂成为一棵树,eh_depth>0 的节点就是索引节点,其中根节点深度最大,在 inode 中。最底层 eh_depth=0 的是叶子节点。
除了根节点,其他的节点都保存在一个块 4k 里面,4k 扣除 ext4_extent_header 的 12 个 byte,剩下的能够放 340 项,每个 extent 最大能表示 128MB 的数据,340 个 extent 会使你的表示的文件达到 42.5GB。这已经非常大了,如果再大,我们可以增加树的深度。
inode 位图和块位图
到这里,我们知道了,硬盘上肯定有一系列的 inode 和一系列的块排列起来。
接下来的问题是,如果我要保存一个数据块,或者要保存一个 inode,我应该放在硬盘上的哪个位置呢?难道需要将所有的 inode 列表和块列表扫描一遍,找个空的地方随便放吗?
当然,这样效率太低了。所以在文件系统里面,我们专门弄了一个块来保存 inode 的位图。在这 4k 里面,每一位对应一个 inode。如果是 1,表示这个 inode 已经被用了;如果是 0,则表示没被用。同样,我们也弄了一个块保存 block 的位图。
上海虹桥火车站的厕位智能引导系统,不知道你有没有见过?这个系统很厉害,我们要想知道哪个位置有没有被占用,不用挨个拉门,从这样一个电子版上就能看到了。

接下来,我们来看位图究竟是如何在 Linux 操作系统里面起作用的。前一节我们讲过,如果创建一个新文件,会调用 open 函数,并且参数会有 O_CREAT。这表示当文件找不到的时候,我们就需要创建一个。open 是一个系统调用,在内核里面会调用 sys_open,定义如下:
|
|
这里我们还是重点看对于 inode 的操作。其实 open 一个文件很复杂,下一节我们会详细分析整个过程。
我们来看接下来的调用链:do_sys_open-> do_filp_open->path_openat->do_last->lookup_open。这个调用链的逻辑是,要打开一个文件,先要根据路径找到文件夹。如果发现文件夹下面没有这个文件,同时又设置了 O_CREAT,就说明我们要在这个文件夹下面创建一个文件,那我们就需要一个新的 inode。
|
|
想要创建新的 inode,我们就要调用 dir_inode,也就是文件夹的 inode 的 create 函数。它的具体定义是这样的:
|
|
这里面定义了,如果文件夹 inode 要做一些操作,每个操作对应应该调用哪些函数。这里 create 操作调用的是 ext4_create。
接下来的调用链是这样的:ext4_create->ext4_new_inode_start_handle->__ext4_new_inode。在 __ext4_new_inode 函数中,我们会创建新的 inode。
|
|
这里面一个重要的逻辑就是,从文件系统里面读取 inode 位图,然后找到下一个为 0 的 inode,就是空闲的 inode。
对于 block 位图,在写入文件的时候,也会有这个过程,我就不展开说了。感兴趣的话,你可以自己去找代码看。
文件系统的格式
看起来,我们现在应该能够很顺利地通过 inode 位图和 block 位图创建文件了。如果仔细计算一下,其实还是有问题的。
数据块的位图是放在一个块里面的,共 4k。每位表示一个数据块,共可以表示 4∗1024∗8=2154∗1024∗8=215
文章作者 anonymous
上次更新 2024-04-12