IPC 这块的内容比较多,为了让你能够更好地理解,我分成了三节来讲。前面我们解析完了共享内存的内核机制后,今天我们来看最后一部分,信号量的内核机制。
首先,我们需要创建一个信号量,调用的是系统调用 semget。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
SYSCALL_DEFINE3(semget, key_t, key, int, nsems, int, semflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops sem_ops = {
.getnew = newary,
.associate = sem_security,
.more_checks = sem_more_checks,
};
struct ipc_params sem_params;
ns = current->nsproxy->ipc_ns;
sem_params.key = key;
sem_params.flg = semflg;
sem_params.u.nsems = nsems;
return ipcget(ns, &sem_ids(ns), &sem_ops, &sem_params);
}
|
我们解析过了共享内存,再看信号量,就顺畅很多了。这里同样调用了抽象的 ipcget,参数分别为信号量对应的 sem_ids、对应的操作 sem_ops 以及对应的参数 sem_params。
ipcget 的代码我们已经解析过了。如果 key 设置为 IPC_PRIVATE 则永远创建新的;如果不是的话,就会调用 ipcget_public。
在 ipcget_public 中,我们能会按照 key,去查找 struct kern_ipc_perm。如果没有找到,那就看看是否设置了 IPC_CREAT。如果设置了,就创建一个新的。如果找到了,就将对应的 id 返回。
我们这里重点看,如何按照参数 sem_ops,创建新的信号量会调用 newary。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
static int newary(struct ipc_namespace *ns, struct ipc_params *params)
{
int retval;
struct sem_array *sma;
key_t key = params->key;
int nsems = params->u.nsems;
int semflg = params->flg;
int i;
......
sma = sem_alloc(nsems);
......
sma->sem_perm.mode = (semflg & S_IRWXUGO);
sma->sem_perm.key = key;
sma->sem_perm.security = NULL;
......
for (i = 0; i < nsems; i++) {
INIT_LIST_HEAD(&sma->sems[i].pending_alter);
INIT_LIST_HEAD(&sma->sems[i].pending_const);
spin_lock_init(&sma->sems[i].lock);
}
sma->complex_count = 0;
sma->use_global_lock = USE_GLOBAL_LOCK_HYSTERESIS;
INIT_LIST_HEAD(&sma->pending_alter);
INIT_LIST_HEAD(&sma->pending_const);
INIT_LIST_HEAD(&sma->list_id);
sma->sem_nsems = nsems;
sma->sem_ctime = get_seconds();
retval = ipc_addid(&sem_ids(ns), &sma->sem_perm, ns->sc_semmni);
......
ns->used_sems += nsems;
......
return sma->sem_perm.id;
}
|
newary 函数的第一步,通过 kvmalloc 在直接映射区分配一个 struct sem_array 结构。这个结构是用来描述信号量的,这个结构最开始就是上面说的 struct kern_ipc_perm 结构。接下来就是填充这个 struct sem_array 结构,例如 key、权限等。
struct sem_array 里有多个信号量,放在 struct sem sems[] 数组里面,在 struct sem 里面有当前的信号量的数值 semval。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
struct sem {
int semval; /* current value */
/*
* PID of the process that last modified the semaphore. For
* Linux, specifically these are:
* - semop
* - semctl, via SETVAL and SETALL.
* - at task exit when performing undo adjustments (see exit_sem).
*/
int sempid;
spinlock_t lock; /* spinlock for fine-grained semtimedop */
struct list_head pending_alter; /* pending single-sop operations that alter the semaphore */
struct list_head pending_const; /* pending single-sop operations that do not alter the semaphore*/
time_t sem_otime; /* candidate for sem_otime */
} ____cacheline_aligned_in_smp;
|
struct sem_array 和 struct sem 各有一个链表 struct list_head pending_alter,分别表示对于整个信号量数组的修改和对于某个信号量的修改。
newary 函数的第二步,就是初始化这些链表。
newary 函数的第三步,通过 ipc_addid 将新创建的 struct sem_array 结构,挂到 sem_ids 里面的基数树上,并返回相应的 id。
信号量创建的过程到此结束,接下来我们来看,如何通过 semctl 对信号量数组进行初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
SYSCALL_DEFINE4(semctl, int, semid, int, semnum, int, cmd, unsigned long, arg)
{
int version;
struct ipc_namespace *ns;
void __user *p = (void __user *)arg;
ns = current->nsproxy->ipc_ns;
switch (cmd) {
case IPC_INFO:
case SEM_INFO:
case IPC_STAT:
case SEM_STAT:
return semctl_nolock(ns, semid, cmd, version, p);
case GETALL:
case GETVAL:
case GETPID:
case GETNCNT:
case GETZCNT:
case SETALL:
return semctl_main(ns, semid, semnum, cmd, p);
case SETVAL:
return semctl_setval(ns, semid, semnum, arg);
case IPC_RMID:
case IPC_SET:
return semctl_down(ns, semid, cmd, version, p);
default:
return -EINVAL;
}
}
|
这里我们重点看,SETALL 操作调用的 semctl_main 函数,以及 SETVAL 操作调用的 semctl_setval 函数。
对于 SETALL 操作来讲,传进来的参数为 union semun 里面的 unsigned short *array,会设置整个信号量集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
static int semctl_main(struct ipc_namespace *ns, int semid, int semnum,
int cmd, void __user *p)
{
struct sem_array *sma;
struct sem *curr;
int err, nsems;
ushort fast_sem_io[SEMMSL_FAST];
ushort *sem_io = fast_sem_io;
DEFINE_WAKE_Q(wake_q);
sma = sem_obtain_object_check(ns, semid);
nsems = sma->sem_nsems;
......
switch (cmd) {
......
case SETALL:
{
int i;
struct sem_undo *un;
......
if (copy_from_user(sem_io, p, nsems*sizeof(ushort))) {
......
}
......
for (i = 0; i < nsems; i++) {
sma->sems[i].semval = sem_io[i];
sma->sems[i].sempid = task_tgid_vnr(current);
}
......
sma->sem_ctime = get_seconds();
/* maybe some queued-up processes were waiting for this */
do_smart_update(sma, NULL, 0, 0, &wake_q);
err = 0;
goto out_unlock;
}
}
......
wake_up_q(&wake_q);
......
}
|
在 semctl_main 函数中,先是通过 sem_obtain_object_check,根据信号量集合的 id 在基数树里面找到 struct sem_array 对象,发现如果是 SETALL 操作,就将用户的参数中的 unsigned short *array 通过 copy_from_user 拷贝到内核里面的 sem_io 数组,然后是一个循环,对于信号量集合里面的每一个信号量,设置 semval,以及修改这个信号量值的 pid。
对于 SETVAL 操作来讲,传进来的参数 union semun 里面的 int val,仅仅会设置某个信号量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
static int semctl_setval(struct ipc_namespace *ns, int semid, int semnum,
unsigned long arg)
{
struct sem_undo *un;
struct sem_array *sma;
struct sem *curr;
int err, val;
DEFINE_WAKE_Q(wake_q);
......
sma = sem_obtain_object_check(ns, semid);
......
curr = &sma->sems[semnum];
......
curr->semval = val;
curr->sempid = task_tgid_vnr(current);
sma->sem_ctime = get_seconds();
/* maybe some queued-up processes were waiting for this */
do_smart_update(sma, NULL, 0, 0, &wake_q);
......
wake_up_q(&wake_q);
return 0;
}
|
在 semctl_setval 函数中,我们先是通过 sem_obtain_object_check,根据信号量集合的 id 在基数树里面找到 struct sem_array 对象,对于 SETVAL 操作,直接根据参数中的 val 设置 semval,以及修改这个信号量值的 pid。
至此,信号量数组初始化完毕。接下来我们来看 P 操作和 V 操作。无论是 P 操作,还是 V 操作都是调用 semop 系统调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
|
SYSCALL_DEFINE3(semop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops)
{
return sys_semtimedop(semid, tsops, nsops, NULL);
}
SYSCALL_DEFINE4(semtimedop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops, const struct timespec __user *, timeout)
{
int error = -EINVAL;
struct sem_array *sma;
struct sembuf fast_sops[SEMOPM_FAST];
struct sembuf *sops = fast_sops, *sop;
struct sem_undo *un;
int max, locknum;
bool undos = false, alter = false, dupsop = false;
struct sem_queue queue;
unsigned long dup = 0, jiffies_left = 0;
struct ipc_namespace *ns;
ns = current->nsproxy->ipc_ns;
......
if (copy_from_user(sops, tsops, nsops * sizeof(*tsops))) {
error = -EFAULT;
goto out_free;
}
if (timeout) {
struct timespec _timeout;
if (copy_from_user(&_timeout, timeout, sizeof(*timeout))) {
}
jiffies_left = timespec_to_jiffies(&_timeout);
}
......
/* On success, find_alloc_undo takes the rcu_read_lock */
un = find_alloc_undo(ns, semid);
......
sma = sem_obtain_object_check(ns, semid);
......
queue.sops = sops;
queue.nsops = nsops;
queue.undo = un;
queue.pid = task_tgid_vnr(current);
queue.alter = alter;
queue.dupsop = dupsop;
error = perform_atomic_semop(sma, &queue);
if (error == 0) { /* non-blocking succesfull path */
DEFINE_WAKE_Q(wake_q);
......
do_smart_update(sma, sops, nsops, 1, &wake_q);
......
wake_up_q(&wake_q);
goto out_free;
}
/*
* We need to sleep on this operation, so we put the current
* task into the pending queue and go to sleep.
*/
if (nsops == 1) {
struct sem *curr;
curr = &sma->sems[sops->sem_num];
......
list_add_tail(&queue.list,
&curr->pending_alter);
......
} else {
......
list_add_tail(&queue.list, &sma->pending_alter);
......
}
do {
queue.status = -EINTR;
queue.sleeper = current;
__set_current_state(TASK_INTERRUPTIBLE);
if (timeout)
jiffies_left = schedule_timeout(jiffies_left);
else
schedule();
......
/*
* If an interrupt occurred we have to clean up the queue.
*/
if (timeout && jiffies_left == 0)
error = -EAGAIN;
} while (error == -EINTR && !signal_pending(current)); /* spurious */
......
}
|
semop 会调用 semtimedop,这是一个非常复杂的函数。
semtimedop 做的第一件事情,就是将用户的参数,例如,对于信号量的操作 struct sembuf,拷贝到内核里面来。另外,如果是 P 操作,很可能让进程进入等待状态,是否要为这个等待状态设置一个超时,timeout 也是一个参数,会把它变成时钟的滴答数目。
semtimedop 做的第二件事情,是通过 sem_obtain_object_check,根据信号量集合的 id,获得 struct sem_array,然后,创建一个 struct sem_queue 表示当前的信号量操作。为什么叫 queue 呢?因为这个操作可能马上就能完成,也可能因为无法获取信号量不能完成,不能完成的话就只好排列到队列上,等待信号量满足条件的时候。semtimedop 会调用 perform_atomic_semop 在实施信号量操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
static int perform_atomic_semop(struct sem_array *sma, struct sem_queue *q)
{
int result, sem_op, nsops;
struct sembuf *sop;
struct sem *curr;
struct sembuf *sops;
struct sem_undo *un;
sops = q->sops;
nsops = q->nsops;
un = q->undo;
for (sop = sops; sop < sops + nsops; sop++) {
curr = &sma->sems[sop->sem_num];
sem_op = sop->sem_op;
result = curr->semval;
......
result += sem_op;
if (result < 0)
goto would_block;
......
if (sop->sem_flg & SEM_UNDO) {
int undo = un->semadj[sop->sem_num] - sem_op;
.....
}
}
for (sop = sops; sop < sops + nsops; sop++) {
curr = &sma->sems[sop->sem_num];
sem_op = sop->sem_op;
result = curr->semval;
if (sop->sem_flg & SEM_UNDO) {
int undo = un->semadj[sop->sem_num] - sem_op;
un->semadj[sop->sem_num] = undo;
}
curr->semval += sem_op;
curr->sempid = q->pid;
}
return 0;
would_block:
q->blocking = sop;
return sop->sem_flg & IPC_NOWAIT ? -EAGAIN : 1;
}
|
在 perform_atomic_semop 函数中,对于所有信号量操作都进行两次循环。在第一次循环中,如果发现计算出的 result 小于 0,则说明必须等待,于是跳到 would_block 中,设置 q->blocking = sop 表示这个 queue 是 block 在这个操作上,然后如果需要等待,则返回 1。如果第一次循环中发现无需等待,则第二个循环实施所有的信号量操作,将信号量的值设置为新的值,并且返回 0。
接下来,我们回到 semtimedop,来看它干的第三件事情,就是如果需要等待,应该怎么办?
如果需要等待,则要区分刚才的对于信号量的操作,是对一个信号量的,还是对于整个信号量集合的。如果是对于一个信号量的,那我们就将 queue 挂到这个信号量的 pending_alter 中;如果是对于整个信号量集合的,那我们就将 queue 挂到整个信号量集合的 pending_alter 中。
接下来的 do-while 循环,就是要开始等待了。如果等待没有时间限制,则调用 schedule 让出 CPU;如果等待有时间限制,则调用 schedule_timeout 让出 CPU,过一段时间还回来。当回来的时候,判断是否等待超时,如果没有等待超时则进入下一轮循环,再次等待,如果超时则退出循环,返回错误。在让出 CPU 的时候,设置进程的状态为 TASK_INTERRUPTIBLE,并且循环的结束会通过 signal_pending 查看是否收到过信号,这说明这个等待信号量的进程是可以被信号中断的,也即一个等待信号量的进程是可以通过 kill 杀掉的。
我们再来看,semtimedop 要做的第四件事情,如果不需要等待,应该怎么办?
如果不需要等待,就说明对于信号量的操作完成了,也改变了信号量的值。接下来,就是一个标准流程。我们通过 DEFINE_WAKE_Q(wake_q) 声明一个 wake_q,调用 do_smart_update,看这次对于信号量的值的改变,可以影响并可以激活等待队列中的哪些 struct sem_queue,然后把它们都放在 wake_q 里面,调用 wake_up_q 唤醒这些进程。其实,所有的对于信号量的值的修改都会涉及这三个操作,如果你回过头去仔细看 SETALL 和 SETVAL 操作,在设置完毕信号量之后,也是这三个操作。
我们来看 do_smart_update 是如何实现的。do_smart_update 会调用 update_queue。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
static int update_queue(struct sem_array *sma, int semnum, struct wake_q_head *wake_q)
{
struct sem_queue *q, *tmp;
struct list_head *pending_list;
int semop_completed = 0;
if (semnum == -1)
pending_list = &sma->pending_alter;
else
pending_list = &sma->sems[semnum].pending_alter;
again:
list_for_each_entry_safe(q, tmp, pending_list, list) {
int error, restart;
......
error = perform_atomic_semop(sma, q);
/* Does q->sleeper still need to sleep? */
if (error > 0)
continue;
unlink_queue(sma, q);
......
wake_up_sem_queue_prepare(q, error, wake_q);
......
}
return semop_completed;
}
static inline void wake_up_sem_queue_prepare(struct sem_queue *q, int error,
struct wake_q_head *wake_q)
{
wake_q_add(wake_q, q->sleeper);
......
}
|
update_queue 会依次循环整个信号量集合的等待队列 pending_alter,或者某个信号量的等待队列。试图在信号量的值变了的情况下,再次尝试 perform_atomic_semop 进行信号量操作。如果不成功,则尝试队列中的下一个;如果尝试成功,则调用 unlink_queue 从队列上取下来,然后调用 wake_up_sem_queue_prepare,将 q->sleeper 加到 wake_q 上去。q->sleeper 是一个 task_struct,是等待在这个信号量操作上的进程。
接下来,wake_up_q 就依次唤醒 wake_q 上的所有 task_struct,调用的是我们在进程调度那一节学过的 wake_up_process 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
void wake_up_q(struct wake_q_head *head)
{
struct wake_q_node *node = head->first;
while (node != WAKE_Q_TAIL) {
struct task_struct *task;
task = container_of(node, struct task_struct, wake_q);
node = node->next;
task->wake_q.next = NULL;
wake_up_process(task);
put_task_struct(task);
}
}
|
至此,对于信号量的主流操作都解析完毕了。
其实还有一点需要强调一下,信号量是一个整个 Linux 可见的全局资源,而不像咱们在线程同步那一节讲过的都是某个进程独占的资源,好处是可以跨进程通信,坏处就是如果一个进程通过 P 操作拿到了一个信号量,但是不幸异常退出了,如果没有来得及归还这个信号量,可能所有其他的进程都阻塞了。
那怎么办呢?Linux 有一种机制叫 SEM_UNDO,也即每一个 semop 操作都会保存一个反向 struct sem_undo 操作,当因为某个进程异常退出的时候,这个进程做的所有的操作都会回退,从而保证其他进程可以正常工作。
如果你回头看,我们写的程序里面的 semaphore_p 函数和 semaphore_v 函数,都把 sem_flg 设置为 SEM_UNDO,就是这个作用。
等待队列上的每一个 struct sem_queue,都有一个 struct sem_undo,以此来表示这次操作的反向操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
struct sem_queue {
struct list_head list; /* queue of pending operations */
struct task_struct *sleeper; /* this process */
struct sem_undo *undo; /* undo structure */
int pid; /* process id of requesting process */
int status; /* completion status of operation */
struct sembuf *sops; /* array of pending operations */
struct sembuf *blocking; /* the operation that blocked */
int nsops; /* number of operations */
bool alter; /* does *sops alter the array? */
bool dupsop; /* sops on more than one sem_num */
};
|
在进程的 task_struct 里面对于信号量有一个成员 struct sysv_sem,里面是一个 struct sem_undo_list,将这个进程所有的 semop 所带来的 undo 操作都串起来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
struct task_struct {
......
struct sysv_sem sysvsem;
......
}
struct sysv_sem {
struct sem_undo_list *undo_list;
};
struct sem_undo {
struct list_head list_proc; /* per-process list: *
* all undos from one process
* rcu protected */
struct rcu_head rcu; /* rcu struct for sem_undo */
struct sem_undo_list *ulp; /* back ptr to sem_undo_list */
struct list_head list_id; /* per semaphore array list:
* all undos for one array */
int semid; /* semaphore set identifier */
short *semadj; /* array of adjustments */
/* one per semaphore */
};
struct sem_undo_list {
atomic_t refcnt;
spinlock_t lock;
struct list_head list_proc;
};
|
为了让你更清楚地理解 struct sem_undo 的原理,我们这里举一个例子。
假设我们创建了两个信号量集合。一个叫 semaphore1,它包含三个信号量,初始化值为 3,另一个叫 semaphore2,它包含 4 个信号量,初始化值都为 4。初始化时候的信号量以及 undo 结构里面的值如图中 (1) 标号所示。
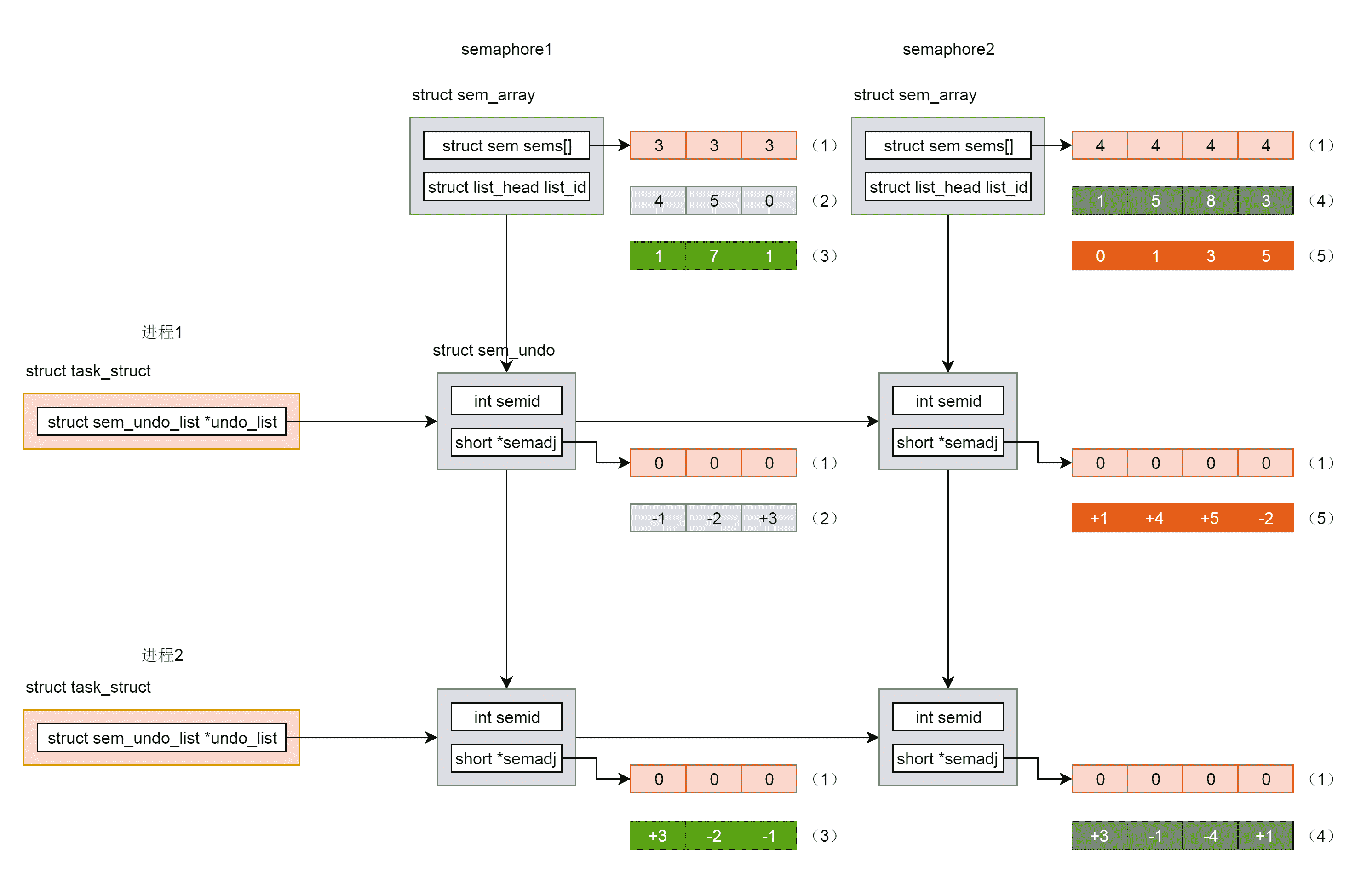
首先,我们来看进程 1。我们调用 semop,将 semaphore1 的三个信号量的值,分别加 1、加 2 和减 3,从而信号量的值变为 4,5,0。于是在 semaphore1 和进程 1 链表交汇的 undo 结构里面,填写 -1,-2,+3,是 semop 操作的反向操作,如图中 (2) 标号所示。
然后,我们来看进程 2。我们调用 semop,将 semaphore1 的三个信号量的值,分别减 3、加 2 和加 1,从而信号量的值变为 1、7、1。于是在 semaphore1 和进程 2 链表交汇的 undo 结构里面,填写 +3、-2、-1,是 semop 操作的反向操作,如图中 (3) 标号所示。
然后,我们接着看进程 2。我们调用 semop,将 semaphore2 的四个信号量的值,分别减 3、加 1、加 4 和减 1,从而信号量的值变为 1、5、8、3。于是,在 semaphore2 和进程 2 链表交汇的 undo 结构里面,填写 +3、-1、-4、+1,是 semop 操作的反向操作,如图中 (4) 标号所示。
然后,我们再来看进程 1。我们调用 semop,将 semaphore2 的四个信号量的值,分别减 1、减 4、减 5 和加 2,从而信号量的值变为 0、1、3、5。于是在 semaphore2 和进程 1 链表交汇的 undo 结构里面,填写 +1、+4、+5、-2,是 semop 操作的反向操作,如图中 (5) 标号所示。
从这个例子可以看出,无论哪个进程异常退出,只要将 undo 结构里面的值加回当前信号量的值,就能够得到正确的信号量的值,不会因为一个进程退出,导致信号量的值处于不一致的状态。
总结时刻
信号量的机制也很复杂,我们对着下面这个图总结一下。
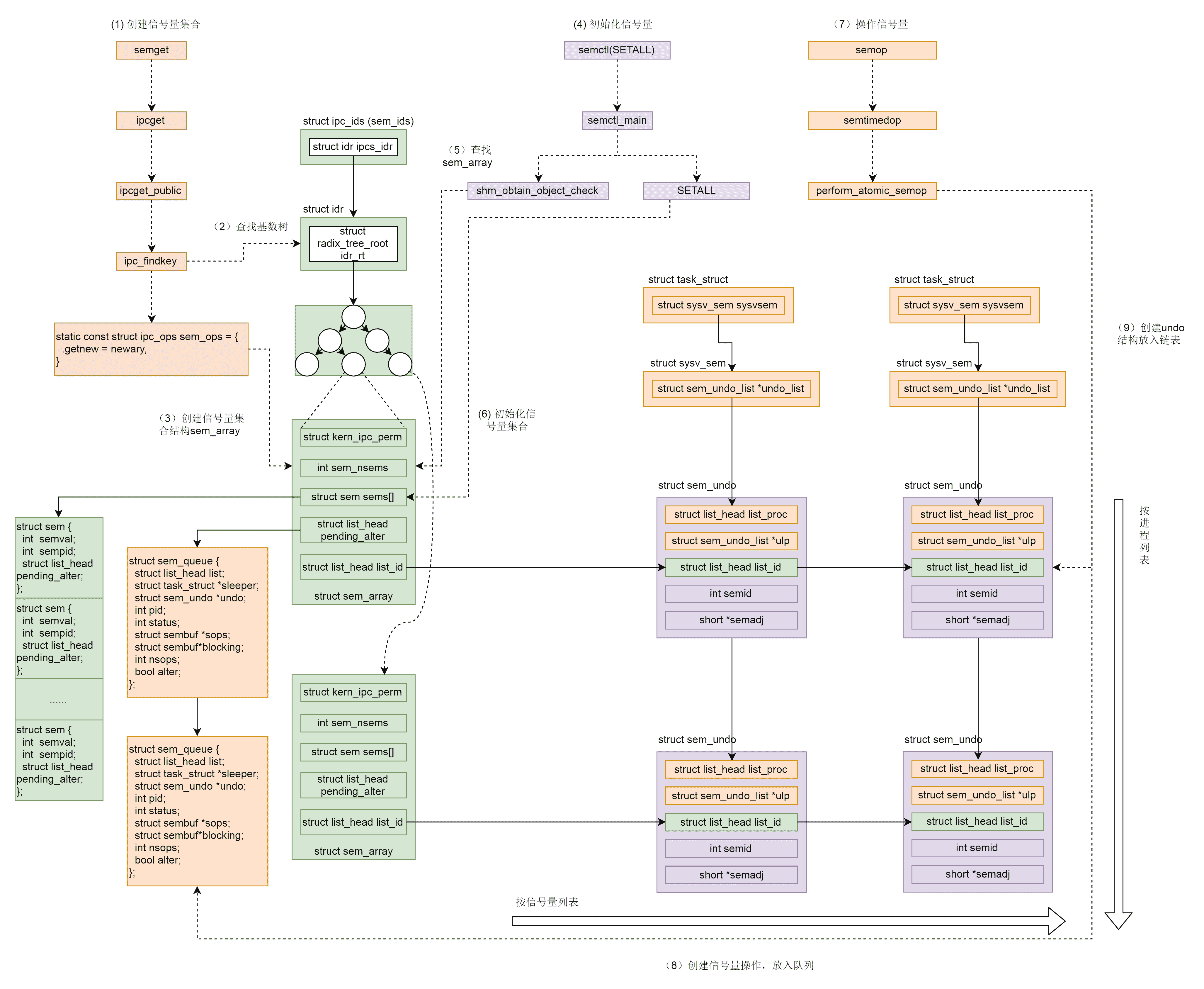
- 调用 semget 创建信号量集合。
- ipc_findkey 会在基数树中,根据 key 查找信号量集合 sem_array 对象。如果已经被创建,就会被查询出来。例如 producer 被创建过,在 consumer 中就会查询出来。
- 如果信号量集合没有被创建过,则调用 sem_ops 的 newary 方法,创建一个信号量集合对象 sem_array。例如,在 producer 中就会新建。
- 调用 semctl(SETALL) 初始化信号量。
- sem_obtain_object_check 先从基数树里面找到 sem_array 对象。
- 根据用户指定的信号量数组,初始化信号量集合,也即初始化 sem_array 对象的 struct sem sems[] 成员。
- 调用 semop 操作信号量。
- 创建信号量操作结构 sem_queue,放入队列。
- 创建 undo 结构,放入链表。
课堂练习
现在,我们的共享内存、信号量、消息队列都讲完了,你是不是觉得,它们的 API 非常相似。为了方便记忆,你可以自己整理一个表格,列一下这三种进程间通信机制、行为创建 xxxget、使用、控制 xxxctl、对应的 API 和系统调用。
欢迎留言和我分享你的疑惑和见解,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
