上一节,我们解析了计算虚拟化之 CPU。可以看到,CPU 的虚拟化是用户态的 qemu 和内核态的 KVM 共同配合完成的。它们二者通过 ioctl 进行通信。对于内存管理来讲,也是需要这两者配合完成的。
咱们在内存管理的时候讲过,操作系统给每个进程分配的内存都是虚拟内存,需要通过页表映射,变成物理内存进行访问。当有了虚拟机之后,情况会变得更加复杂。因为虚拟机对于物理机来讲是一个进程,但是虚拟机里面也有内核,也有虚拟机里面跑的进程。所以有了虚拟机,内存就变成了四类:
- 虚拟机里面的虚拟内存(Guest OS Virtual Memory,GVA),这是虚拟机里面的进程看到的内存空间;
- 虚拟机里面的物理内存(Guest OS Physical Memory,GPA),这是虚拟机里面的操作系统看到的内存,它认为这是物理内存;
- 物理机的虚拟内存(Host Virtual Memory,HVA),这是物理机上的 qemu 进程看到的内存空间;
- 物理机的物理内存(Host Physical Memory,HPA),这是物理机上的操作系统看到的内存。
咱们内存管理那一章讲的两大内容,一个是内存管理,它变得非常复杂;另一个是内存映射,具体来说就是,从 GVA 到 GPA,到 HVA,再到 HPA,这样几经转手,计算机的性能就会变得很差。当然,虚拟化技术成熟的今天,有了一些优化的手段,具体怎么优化呢?我们这一节就来一一解析。
内存管理
我们先来看内存管理的部分。
由于 CPU 和内存是紧密结合的,因而内存虚拟化的初始化过程,和 CPU 虚拟化的初始化是一起完成的。
上一节说 CPU 虚拟化初始化的时候,我们会调用 kvm_init 函数,这里面打开了"/dev/kvm"这个字符文件,并且通过 ioctl 调用到内核 kvm 的 KVM_CREATE_VM 操作,除了这些 CPU 相关的调用,接下来还有内存相关的。我们来看看。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
static int kvm_init(MachineState *ms)
{
MachineClass *mc = MACHINE_GET_CLASS(ms);
......
kvm_memory_listener_register(s, &s->memory_listener,
&address_space_memory, 0);
memory_listener_register(&kvm_io_listener,
&address_space_io);
......
}
AddressSpace address_space_io;
AddressSpace address_space_memory;
|
这里面有两个地址空间 AddressSpace,一个是系统内存的地址空间 address_space_memory,一个用于 I/O 的地址空间 address_space_io。这里我们重点看 address_space_memory。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
struct AddressSpace {
/* All fields are private. */
struct rcu_head rcu;
char *name;
MemoryRegion *root;
/* Accessed via RCU. */
struct FlatView *current_map;
int ioeventfd_nb;
struct MemoryRegionIoeventfd *ioeventfds;
QTAILQ_HEAD(, MemoryListener) listeners;
QTAILQ_ENTRY(AddressSpace) address_spaces_link;
};
|
对于一个地址空间,会有多个内存区域 MemoryRegion 组成树形结构。这里面,root 是这棵树的根。另外,还有一个 MemoryListener 链表,当内存区域发生变化的时候,需要做一些动作,使得用户态和内核态能够协同,就是由这些 MemoryListener 完成的。
在 kvm_init 这个时候,还没有内存区域加入进来,root 还是空的,但是我们可以先注册 MemoryListener,这里注册的是 KVMMemoryListener。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
void kvm_memory_listener_register(KVMState *s, KVMMemoryListener *kml,
AddressSpace *as, int as_id)
{
int i;
kml->slots = g_malloc0(s->nr_slots * sizeof(KVMSlot));
kml->as_id = as_id;
for (i = 0; i < s->nr_slots; i++) {
kml->slots[i].slot = i;
}
kml->listener.region_add = kvm_region_add;
kml->listener.region_del = kvm_region_del;
kml->listener.priority = 10;
memory_listener_register(&kml->listener, as);
}
|
在这个 KVMMemoryListener 中是这样配置的:当添加一个 MemoryRegion 的时候,region_add 会被调用,这个我们后面会用到。
接下来,在 qemu 启动的 main 函数中,我们会调用 cpu_exec_init_all->memory_map_init.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
static void memory_map_init(void)
{
system_memory = g_malloc(sizeof(*system_memory));
memory_region_init(system_memory, NULL, "system", UINT64_MAX);
address_space_init(&address_space_memory, system_memory, "memory");
system_io = g_malloc(sizeof(*system_io));
memory_region_init_io(system_io, NULL, &unassigned_io_ops, NULL, "io",
65536);
address_space_init(&address_space_io, system_io, "I/O");
}
|
在这里,对于系统内存区域 system_memory 和用于 I/O 的内存区域 system_io,我们都进行了初始化,并且关联到了相应的地址空间 AddressSpace。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
void address_space_init(AddressSpace *as, MemoryRegion *root, const char *name)
{
memory_region_ref(root);
as->root = root;
as->current_map = NULL;
as->ioeventfd_nb = 0;
as->ioeventfds = NULL;
QTAILQ_INIT(&as->listeners);
QTAILQ_INSERT_TAIL(&address_spaces, as, address_spaces_link);
as->name = g_strdup(name ? name : "anonymous");
address_space_update_topology(as);
address_space_update_ioeventfds(as);
}
|
对于系统内存地址空间 address_space_memory,我们需要把它里面内存区域的根 root 设置为 system_memory。
另外,在这里,我们还调用了 address_space_update_topology。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
static void address_space_update_topology(AddressSpace *as)
{
MemoryRegion *physmr = memory_region_get_flatview_root(as->root);
flatviews_init();
if (!g_hash_table_lookup(flat_views, physmr)) {
generate_memory_topology(physmr);
}
address_space_set_flatview(as);
}
static void address_space_set_flatview(AddressSpace *as)
{
FlatView *old_view = address_space_to_flatview(as);
MemoryRegion *physmr = memory_region_get_flatview_root(as->root);
FlatView *new_view = g_hash_table_lookup(flat_views, physmr);
if (old_view == new_view) {
return;
}
......
if (!QTAILQ_EMPTY(&as->listeners)) {
FlatView tmpview = { .nr = 0 }, *old_view2 = old_view;
if (!old_view2) {
old_view2 = &tmpview;
}
address_space_update_topology_pass(as, old_view2, new_view, false);
address_space_update_topology_pass(as, old_view2, new_view, true);
}
/* Writes are protected by the BQL. */
atomic_rcu_set(&as->current_map, new_view);
......
}
|
这里面会生成 AddressSpace 的 flatview。flatview 是什么意思呢?
我们可以看到,在 AddressSpace 里面,除了树形结构的 MemoryRegion 之外,还有一个 flatview 结构,其实这个结构就是把这样一个树形的内存结构变成平的内存结构。因为树形内存结构比较容易管理,但是平的内存结构,比较方便和内核里面通信,来请求物理内存。虽然操作系统内核里面也是用树形结构来表示内存区域的,但是用户态向内核申请内存的时候,会按照平的、连续的模式进行申请。这里,qemu 在用户态,所以要做这样一个转换。
在 address_space_set_flatview 中,我们将老的 flatview 和新的 flatview 进行比较。如果不同,说明内存结构发生了变化,会调用 address_space_update_topology_pass->MEMORY_LISTENER_UPDATE_REGION->MEMORY_LISTENER_CALL。
这里面调用所有的 listener。但是,这个逻辑这里不会执行的。这是因为这里内存处于初始化的阶段,全局的 flat_views 里面肯定找不到。因而 generate_memory_topology 第一次生成了 FlatView,然后才调用了 address_space_set_flatview。这里面,老的 flatview 和新的 flatview 一定是一样的。
但是,请你记住这个逻辑,到这里我们还没解析 qemu 有关内存的参数,所以这里添加的 MemoryRegion 虽然是一个根,但是是空的,是为了管理使用的,后面真的添加内存的时候,这个逻辑还会调用到。
我们再回到 qemu 启动的 main 函数中。接下来的初始化过程会调用 pc_init1。在这里面,对于 CPU 虚拟化,我们会调用 pc_cpus_init。这个我们在上一节已经讲过了。另外,pc_init1 还会调用 pc_memory_init,进行内存的虚拟化,我们这里解析这一部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
void pc_memory_init(PCMachineState *pcms,
MemoryRegion *system_memory,
MemoryRegion *rom_memory,
MemoryRegion **ram_memory)
{
int linux_boot, i;
MemoryRegion *ram, *option_rom_mr;
MemoryRegion *ram_below_4g, *ram_above_4g;
FWCfgState *fw_cfg;
MachineState *machine = MACHINE(pcms);
PCMachineClass *pcmc = PC_MACHINE_GET_CLASS(pcms);
......
/* Allocate RAM. We allocate it as a single memory region and use
* aliases to address portions of it, mostly for backwards compatibility with older qemus that used qemu_ram_alloc().
*/
ram = g_malloc(sizeof(*ram));
memory_region_allocate_system_memory(ram, NULL, "pc.ram",
machine->ram_size);
*ram_memory = ram;
ram_below_4g = g_malloc(sizeof(*ram_below_4g));
memory_region_init_alias(ram_below_4g, NULL, "ram-below-4g", ram,
0, pcms->below_4g_mem_size);
memory_region_add_subregion(system_memory, 0, ram_below_4g);
e820_add_entry(0, pcms->below_4g_mem_size, E820_RAM);
if (pcms->above_4g_mem_size > 0) {
ram_above_4g = g_malloc(sizeof(*ram_above_4g));
memory_region_init_alias(ram_above_4g, NULL, "ram-above-4g", ram, pcms->below_4g_mem_size, pcms->above_4g_mem_size);
memory_region_add_subregion(system_memory, 0x100000000ULL,
ram_above_4g);
e820_add_entry(0x100000000ULL, pcms->above_4g_mem_size, E820_RAM);
}
......
}
|
在 pc_memory_init 中,我们已经知道了虚拟机要申请的内存 ram_size,于是通过 memory_region_allocate_system_memory 来申请内存。
接下来的调用链为:memory_region_allocate_system_memory->allocate_system_memory_nonnuma->memory_region_init_ram_nomigrate->memory_region_init_ram_shared_nomigrate。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
void memory_region_init_ram_shared_nomigrate(MemoryRegion *mr,
Object *owner,
const char *name,
uint64_t size,
bool share,
Error **errp)
{
Error *err = NULL;
memory_region_init(mr, owner, name, size);
mr->ram = true;
mr->terminates = true;
mr->destructor = memory_region_destructor_ram;
mr->ram_block = qemu_ram_alloc(size, share, mr, &err);
......
}
static
RAMBlock *qemu_ram_alloc_internal(ram_addr_t size, ram_addr_t max_size, void (*resized)(const char*,uint64_t length,void *host),void *host, bool resizeable, bool share,MemoryRegion *mr, Error **errp)
{
RAMBlock *new_block;
size = HOST_PAGE_ALIGN(size);
max_size = HOST_PAGE_ALIGN(max_size);
new_block = g_malloc0(sizeof(*new_block));
new_block->mr = mr;
new_block->resized = resized;
new_block->used_length = size;
new_block->max_length = max_size;
new_block->fd = -1;
new_block->page_size = getpagesize();
new_block->host = host;
......
ram_block_add(new_block, &local_err, share);
return new_block;
}
static void ram_block_add(RAMBlock *new_block, Error **errp, bool shared)
{
RAMBlock *block;
RAMBlock *last_block = NULL;
ram_addr_t old_ram_size, new_ram_size;
Error *err = NULL;
old_ram_size = last_ram_page();
new_block->offset = find_ram_offset(new_block->max_length);
if (!new_block->host) {
new_block->host = phys_mem_alloc(new_block->max_length, &new_block->mr->align, shared);
......
}
}
......
}
|
这里面,我们会调用 qemu_ram_alloc,创建一个 RAMBlock 用来表示内存块。这里面调用 ram_block_add->phys_mem_alloc。phys_mem_alloc 是一个函数指针,指向函数 qemu_anon_ram_alloc,这里面调用 qemu_ram_mmap,在 qemu_ram_mmap 中调用 mmap 分配内存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
static void *(*phys_mem_alloc)(size_t size, uint64_t *align, bool shared) = qemu_anon_ram_alloc;
void *qemu_anon_ram_alloc(size_t size, uint64_t *alignment, bool shared)
{
size_t align = QEMU_VMALLOC_ALIGN;
void *ptr = qemu_ram_mmap(-1, size, align, shared);
......
if (alignment) {
*alignment = align;
}
return ptr;
}
void *qemu_ram_mmap(int fd, size_t size, size_t align, bool shared)
{
int flags;
int guardfd;
size_t offset;
size_t pagesize;
size_t total;
void *guardptr;
void *ptr;
......
total = size + align;
guardfd = -1;
pagesize = getpagesize();
flags = MAP_PRIVATE | MAP_ANONYMOUS;
guardptr = mmap(0, total, PROT_NONE, flags, guardfd, 0);
......
flags = MAP_FIXED;
flags |= fd == -1 ? MAP_ANONYMOUS : 0;
flags |= shared ? MAP_SHARED : MAP_PRIVATE;
offset = QEMU_ALIGN_UP((uintptr_t)guardptr, align) - (uintptr_t)guardptr;
ptr = mmap(guardptr + offset, size, PROT_READ | PROT_WRITE, flags, fd, 0);
......
return ptr;
}
|
我们回到 pc_memory_init,通过 memory_region_allocate_system_memory 申请到内存以后,为了兼容过去的版本,我们分成两个 MemoryRegion 进行管理,一个是 ram_below_4g,一个是 ram_above_4g。对于这两个 MemoryRegion,我们都会初始化一个 alias,也即别名,意思是说,两个 MemoryRegion 其实都指向 memory_region_allocate_system_memory 分配的内存,只不过分成两个部分,起两个别名指向不同的区域。
这两部分 MemoryRegion 都会调用 memory_region_add_subregion,将这两部分作为子的内存区域添加到 system_memory 这棵树上。
接下来的调用链为:memory_region_add_subregion->memory_region_add_subregion_common->memory_region_update_container_subregions。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
static void memory_region_update_container_subregions(MemoryRegion *subregion)
{
MemoryRegion *mr = subregion->container;
MemoryRegion *other;
memory_region_transaction_begin();
memory_region_ref(subregion);
QTAILQ_FOREACH(other, &mr->subregions, subregions_link) {
if (subregion->priority >= other->priority) {
QTAILQ_INSERT_BEFORE(other, subregion, subregions_link);
goto done;
}
}
QTAILQ_INSERT_TAIL(&mr->subregions, subregion, subregions_link);
done:
memory_region_update_pending |= mr->enabled && subregion->enabled;
memory_region_transaction_commit();
}
|
在 memory_region_update_container_subregions 中,我们会将子区域放到链表中,然后调用 memory_region_transaction_commit。在这里面,我们会调用 address_space_set_flatview。因为内存区域变了,flatview 也会变,就像上面分析过的一样,listener 会被调用。
因为添加了一个 MemoryRegion,region_add 也即 kvm_region_add。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
static void kvm_region_add(MemoryListener *listener,
MemoryRegionSection *section)
{
KVMMemoryListener *kml = container_of(listener, KVMMemoryListener, listener);
kvm_set_phys_mem(kml, section, true);
}
static void kvm_set_phys_mem(KVMMemoryListener *kml,
MemoryRegionSection *section, bool add)
{
KVMSlot *mem;
int err;
MemoryRegion *mr = section->mr;
bool writeable = !mr->readonly && !mr->rom_device;
hwaddr start_addr, size;
void *ram;
......
size = kvm_align_section(section, &start_addr);
......
/* use aligned delta to align the ram address */
ram = memory_region_get_ram_ptr(mr) + section->offset_within_region + (start_addr - section->offset_within_address_space);
......
/* register the new slot */
mem = kvm_alloc_slot(kml);
mem->memory_size = size;
mem->start_addr = start_addr;
mem->ram = ram;
mem->flags = kvm_mem_flags(mr);
err = kvm_set_user_memory_region(kml, mem, true);
......
}
|
kvm_region_add 调用的是 kvm_set_phys_mem,这里面分配一个用于放这块那内存的 KVMSlot 结构,就像一个内存条一样,当然这是在用户态模拟出来的内存条,放在 KVMState 结构里面。这个结构是我们上一节创建虚拟机的时候创建的。
接下来,kvm_set_user_memory_region 就会将用户态模拟出来的内存条,和内核中的 KVM 模块关联起来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
static int kvm_set_user_memory_region(KVMMemoryListener *kml, KVMSlot *slot, bool new)
{
KVMState *s = kvm_state;
struct kvm_userspace_memory_region mem;
int ret;
mem.slot = slot->slot | (kml->as_id << 16);
mem.guest_phys_addr = slot->start_addr;
mem.userspace_addr = (unsigned long)slot->ram;
mem.flags = slot->flags;
......
mem.memory_size = slot->memory_size;
ret = kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
slot->old_flags = mem.flags;
......
return ret;
}
|
终于,在这里,我们又看到了可以和内核通信的 kvm_vm_ioctl。我们来看内核收到 KVM_SET_USER_MEMORY_REGION 会做哪些事情。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
static long kvm_vm_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm *kvm = filp->private_data;
void __user *argp = (void __user *)arg;
switch (ioctl) {
case KVM_SET_USER_MEMORY_REGION: {
struct kvm_userspace_memory_region kvm_userspace_mem;
if (copy_from_user(&kvm_userspace_mem, argp,
sizeof(kvm_userspace_mem)))
goto out;
r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem);
break;
}
......
}
|
接下来的调用链为:kvm_vm_ioctl_set_memory_region->kvm_set_memory_region->__kvm_set_memory_region。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
int __kvm_set_memory_region(struct kvm *kvm,
const struct kvm_userspace_memory_region *mem)
{
int r;
gfn_t base_gfn;
unsigned long npages;
struct kvm_memory_slot *slot;
struct kvm_memory_slot old, new;
struct kvm_memslots *slots = NULL, *old_memslots;
int as_id, id;
enum kvm_mr_change change;
......
as_id = mem->slot >> 16;
id = (u16)mem->slot;
slot = id_to_memslot(__kvm_memslots(kvm, as_id), id);
base_gfn = mem->guest_phys_addr >> PAGE_SHIFT;
npages = mem->memory_size >> PAGE_SHIFT;
......
new = old = *slot;
new.id = id;
new.base_gfn = base_gfn;
new.npages = npages;
new.flags = mem->flags;
......
if (change == KVM_MR_CREATE) {
new.userspace_addr = mem->userspace_addr;
if (kvm_arch_create_memslot(kvm, &new, npages))
goto out_free;
}
......
slots = kvzalloc(sizeof(struct kvm_memslots), GFP_KERNEL);
memcpy(slots, __kvm_memslots(kvm, as_id), sizeof(struct kvm_memslots));
......
r = kvm_arch_prepare_memory_region(kvm, &new, mem, change);
update_memslots(slots, &new);
old_memslots = install_new_memslots(kvm, as_id, slots);
kvm_arch_commit_memory_region(kvm, mem, &old, &new, change);
return 0;
......
}
|
在用户态每个 KVMState 有多个 KVMSlot,在内核里面,同样每个 struct kvm 也有多个 struct kvm_memory_slot,两者是对应起来的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
// 用户态
struct KVMState
{
......
int nr_slots;
......
KVMMemoryListener memory_listener;
......
};
typedef struct KVMMemoryListener {
MemoryListener listener;
KVMSlot *slots;
int as_id;
} KVMMemoryListener
typedef struct KVMSlot
{
hwaddr start_addr;
ram_addr_t memory_size;
void *ram;
int slot;
int flags;
int old_flags;
} KVMSlot;
// 内核态
struct kvm {
spinlock_t mmu_lock;
struct mutex slots_lock;
struct mm_struct *mm; /* userspace tied to this vm */
struct kvm_memslots __rcu *memslots[KVM_ADDRESS_SPACE_NUM];
......
}
struct kvm_memslots {
u64 generation;
struct kvm_memory_slot memslots[KVM_MEM_SLOTS_NUM];
/* The mapping table from slot id to the index in memslots[]. */
short id_to_index[KVM_MEM_SLOTS_NUM];
atomic_t lru_slot;
int used_slots;
};
struct kvm_memory_slot {
gfn_t base_gfn;// 根据 guest_phys_addr 计算
unsigned long npages;
unsigned long *dirty_bitmap;
struct kvm_arch_memory_slot arch;
unsigned long userspace_addr;
u32 flags;
short id;
};
|
并且,id_to_memslot 函数可以根据用户态的 slot 号得到内核态的 slot 结构。
如果传进来的参数是 KVM_MR_CREATE,表示要创建一个新的内存条,就会调用 kvm_arch_create_memslot 来创建 kvm_memory_slot 的成员 kvm_arch_memory_slot。
接下来就是创建 kvm_memslots 结构,填充这个结构,然后通过 install_new_memslots 将这个新的内存条,添加到 struct kvm 结构中。
至此,用户态的内存结构和内核态的内存结构算是对应了起来。
页面分配和映射
上面对于内存的管理,还只是停留在元数据的管理。对于内存的分配与映射,我们还没有涉及,接下来,我们就来看看,页面是如何进行分配和映射的。
上面咱们说了,内存映射对于虚拟机来讲是一件非常麻烦的事情,从 GVA 到 GPA 到 HVA 到 HPA,性能很差,为了解决这个问题,有两种主要的思路。
影子页表
第一种方式就是软件的方式,影子页表 (Shadow Page Table)。
按照咱们在内存管理那一节讲的,内存映射要通过页表来管理,页表地址应该放在 cr3 寄存器里面。本来的过程是,客户机要通过 cr3 找到客户机的页表,实现从 GVA 到 GPA 的转换,然后在宿主机上,要通过 cr3 找到宿主机的页表,实现从 HVA 到 HPA 的转换。
为了实现客户机虚拟地址空间到宿主机物理地址空间的直接映射。客户机中每个进程都有自己的虚拟地址空间,所以 KVM 需要为客户机中的每个进程页表都要维护一套相应的影子页表。
在客户机访问内存时,使用的不是客户机的原来的页表,而是这个页表对应的影子页表,从而实现了从客户机虚拟地址到宿主机物理地址的直接转换。而且,在 TLB 和 CPU 缓存上缓存的是来自影子页表中客户机虚拟地址和宿主机物理地址之间的映射,也因此提高了缓存的效率。
但是影子页表的引入也意味着 KVM 需要为每个客户机的每个进程的页表都要维护一套相应的影子页表,内存占用比较大,而且客户机页表和和影子页表也需要进行实时同步。
扩展页表
于是就有了第二种方式,就是硬件的方式,Intel 的 EPT(Extent Page Table,扩展页表)技术。
EPT 在原有客户机页表对客户机虚拟地址到客户机物理地址映射的基础上,又引入了 EPT 页表来实现客户机物理地址到宿主机物理地址的另一次映射。客户机运行时,客户机页表被载入 CR3,而 EPT 页表被载入专门的 EPT 页表指针寄存器 EPTP。
有了 EPT,在客户机物理地址到宿主机物理地址转换的过程中,缺页会产生 EPT 缺页异常。KVM 首先根据引起异常的客户机物理地址,映射到对应的宿主机虚拟地址,然后为此虚拟地址分配新的物理页,最后 KVM 再更新 EPT 页表,建立起引起异常的客户机物理地址到宿主机物理地址之间的映射。
KVM 只需为每个客户机维护一套 EPT 页表,也大大减少了内存的开销。
这里,我们重点看第二种方式。因为使用了 EPT 之后,客户机里面的页表映射,也即从 GVA 到 GPA 的转换,还是用传统的方式,和在内存管理那一章讲的没有什么区别。而 EPT 重点帮我们解决的就是从 GPA 到 HPA 的转换问题。因为要经过两次页表,所以 EPT 又 tdp(two dimentional paging)。
EPT 的页表结构也是分为四层,EPT Pointer(EPTP)指向 PML4 的首地址。
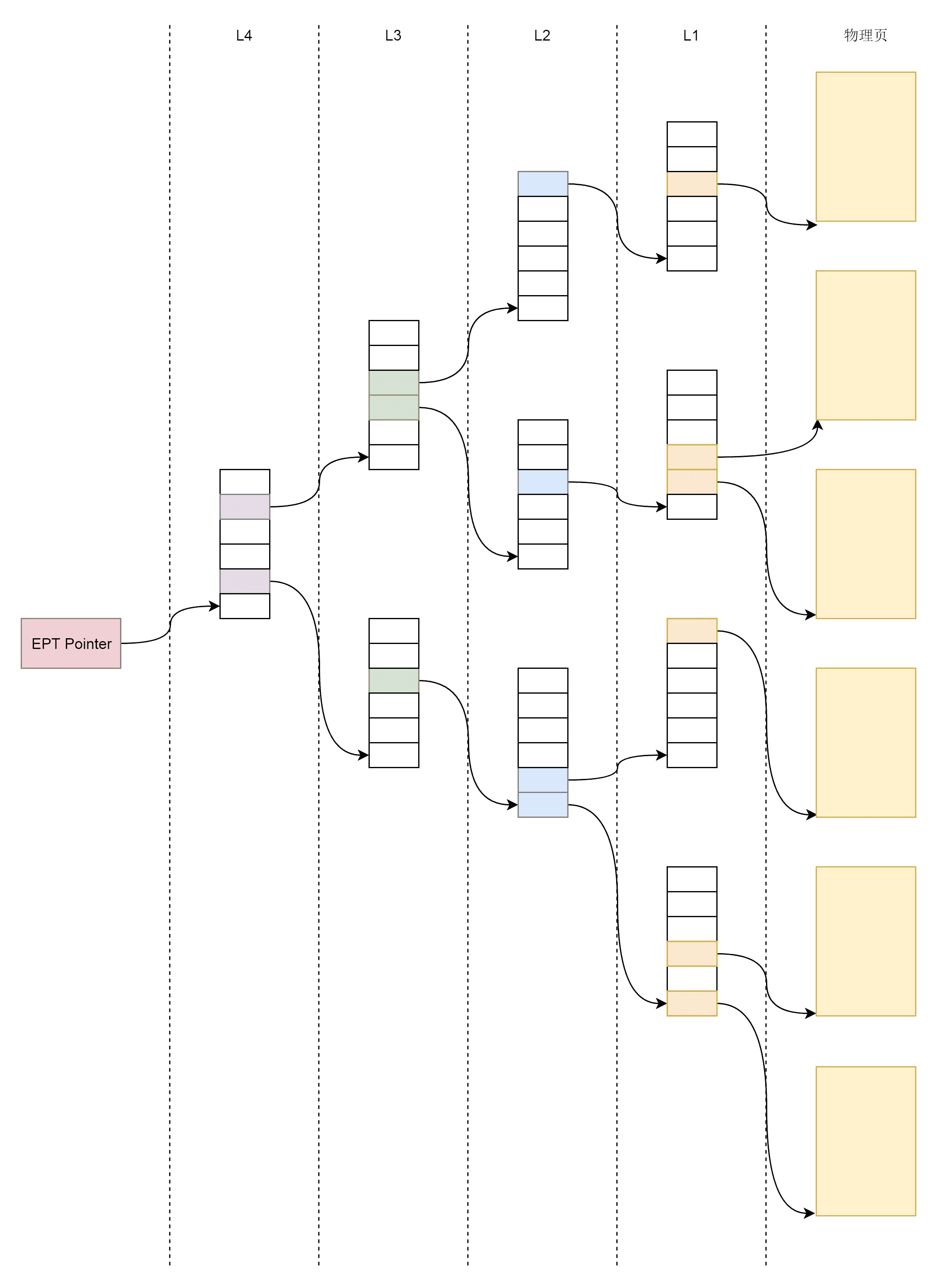
管理物理页面的 Page 结构和咱们讲内存管理那一章是一样的。EPT 页表也需要存放在一个页中,这些页要用 kvm_mmu_page 这个结构来管理。
当一个虚拟机运行,进入客户机模式的时候,我们上一节解析过,它会调用 vcpu_enter_guest 函数,这里面会调用 kvm_mmu_reload->kvm_mmu_load。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
int kvm_mmu_load(struct kvm_vcpu *vcpu)
{
......
r = mmu_topup_memory_caches(vcpu);
r = mmu_alloc_roots(vcpu);
kvm_mmu_sync_roots(vcpu);
/* set_cr3() should ensure TLB has been flushed */
vcpu->arch.mmu.set_cr3(vcpu, vcpu->arch.mmu.root_hpa);
......
}
static int mmu_alloc_roots(struct kvm_vcpu *vcpu)
{
if (vcpu->arch.mmu.direct_map)
return mmu_alloc_direct_roots(vcpu);
else
return mmu_alloc_shadow_roots(vcpu);
}
static int mmu_alloc_direct_roots(struct kvm_vcpu *vcpu)
{
struct kvm_mmu_page *sp;
unsigned i;
if (vcpu->arch.mmu.shadow_root_level == PT64_ROOT_LEVEL) {
spin_lock(&vcpu->kvm->mmu_lock);
make_mmu_pages_available(vcpu);
sp = kvm_mmu_get_page(vcpu, 0, 0, PT64_ROOT_LEVEL, 1, ACC_ALL);
++sp->root_count;
spin_unlock(&vcpu->kvm->mmu_lock);
vcpu->arch.mmu.root_hpa = __pa(sp->spt);
}
......
}
|
这里构建的是页表的根部,也即顶级页表,并且设置 cr3 来刷新 TLB。mmu_alloc_roots 会调用 mmu_alloc_direct_roots,因为我们用的是 EPT 模式,而非影子表。在 mmu_alloc_direct_roots 中,kvm_mmu_get_page 会分配一个 kvm_mmu_page,来存放顶级页表项。
接下来,当虚拟机真的要访问内存的时候,会发现有的页表没有建立,有的物理页没有分配,这都会触发缺页异常,在 KVM 里面会发送 VM-Exit,从客户机模式转换为宿主机模式,来修复这个缺失的页表或者物理页。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
static int (*const kvm_vmx_exit_handlers[])(struct kvm_vcpu *vcpu) = {
[EXIT_REASON_EXCEPTION_NMI] = handle_exception,
[EXIT_REASON_EXTERNAL_INTERRUPT] = handle_external_interrupt,
[EXIT_REASON_IO_INSTRUCTION] = handle_io,
......
[EXIT_REASON_EPT_VIOLATION] = handle_ept_violation,
......
}
|
咱们前面讲过,虚拟机退出客户机模式有很多种原因,例如接收到中断、接收到 I/O 等,EPT 的缺页异常也是一种类型,我们称为 EXIT_REASON_EPT_VIOLATION,对应的处理函数是 handle_ept_violation。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
static int handle_ept_violation(struct kvm_vcpu *vcpu)
{
gpa_t gpa;
......
gpa = vmcs_read64(GUEST_PHYSICAL_ADDRESS);
......
vcpu->arch.gpa_available = true;
vcpu->arch.exit_qualification = exit_qualification;
return kvm_mmu_page_fault(vcpu, gpa, error_code, NULL, 0);
}
int kvm_mmu_page_fault(struct kvm_vcpu *vcpu, gva_t cr2, u64 error_code,
void *insn, int insn_len)
{
......
r = vcpu->arch.mmu.page_fault(vcpu, cr2, lower_32_bits(error_code),false);
......
}
|
在 handle_ept_violation 里面,我们从 VMCS 中得到没有解析成功的 GPA,也即客户机的物理地址,然后调用 kvm_mmu_page_fault,看为什么解析不成功。kvm_mmu_page_fault 会调用 page_fault 函数,其实是 tdp_page_fault 函数。tdp 的意思就是 EPT,前面我们解释过了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
static int tdp_page_fault(struct kvm_vcpu *vcpu, gva_t gpa, u32 error_code, bool prefault)
{
kvm_pfn_t pfn;
int r;
int level;
bool force_pt_level;
gfn_t gfn = gpa >> PAGE_SHIFT;
unsigned long mmu_seq;
int write = error_code & PFERR_WRITE_MASK;
bool map_writable;
r = mmu_topup_memory_caches(vcpu);
level = mapping_level(vcpu, gfn, &force_pt_level);
......
if (try_async_pf(vcpu, prefault, gfn, gpa, &pfn, write, &map_writable))
return 0;
if (handle_abnormal_pfn(vcpu, 0, gfn, pfn, ACC_ALL, &r))
return r;
make_mmu_pages_available(vcpu);
r = __direct_map(vcpu, write, map_writable, level, gfn, pfn, prefault);
......
}
|
既然没有映射,就应该加上映射,tdp_page_fault 就是干这个事情的。
在 tdp_page_fault 这个函数开头,我们通过 gpa,也即客户机的物理地址得到客户机的页号 gfn。接下来,我们要通过调用 try_async_pf 得到宿主机的物理地址对应的页号,也即真正的物理页的页号,然后通过 __direct_map 将两者关联起来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
static bool try_async_pf(struct kvm_vcpu *vcpu, bool prefault, gfn_t gfn, gva_t gva, kvm_pfn_t *pfn, bool write, bool *writable)
{
struct kvm_memory_slot *slot;
bool async;
slot = kvm_vcpu_gfn_to_memslot(vcpu, gfn);
async = false;
*pfn = __gfn_to_pfn_memslot(slot, gfn, false, &async, write, writable);
if (!async)
return false; /* *pfn has correct page already */
if (!prefault && kvm_can_do_async_pf(vcpu)) {
if (kvm_find_async_pf_gfn(vcpu, gfn)) {
kvm_make_request(KVM_REQ_APF_HALT, vcpu);
return true;
} else if (kvm_arch_setup_async_pf(vcpu, gva, gfn))
return true;
}
*pfn = __gfn_to_pfn_memslot(slot, gfn, false, NULL, write, writable);
return false;
}
|
在 try_async_pf 中,要想得到 pfn,也即物理页的页号,会先通过 kvm_vcpu_gfn_to_memslot,根据客户机的物理地址对应的页号找到内存条,然后调用 __gfn_to_pfn_memslot,根据内存条找到 pfn。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
kvm_pfn_t __gfn_to_pfn_memslot(struct kvm_memory_slot *slot, gfn_t gfn,bool atomic, bool *async, bool write_fault,bool *writable)
{
unsigned long addr = __gfn_to_hva_many(slot, gfn, NULL, write_fault);
......
return hva_to_pfn(addr, atomic, async, write_fault,
writable);
}
|
在 __gfn_to_pfn_memslot 中,我们会调用 __gfn_to_hva_many,从客户机物理地址对应的页号,得到宿主机虚拟地址 hva,然后从宿主机虚拟地址到宿主机物理地址,调用的是 hva_to_pfn。
hva_to_pfn 会调用 hva_to_pfn_slow。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
static int hva_to_pfn_slow(unsigned long addr, bool *async, bool write_fault,
bool *writable, kvm_pfn_t *pfn)
{
struct page *page[1];
int npages = 0;
......
if (async) {
npages = get_user_page_nowait(addr, write_fault, page);
} else {
......
npages = get_user_pages_unlocked(addr, 1, page, flags);
}
......
*pfn = page_to_pfn(page[0]);
return npages;
}
|
在 hva_to_pfn_slow 中,我们要先调用 get_user_page_nowait,得到一个物理页面,然后再调用 page_to_pfn 将物理页面转换成为物理页号。
无论是哪一种 get_user_pages_XXX,最终都会调用 __get_user_pages 函数。这里面会调用 faultin_page,在 faultin_page 中我们会调用 handle_mm_fault。看到这个是不是很熟悉?这就是咱们内存管理那一章讲的缺页异常的逻辑,分配一个物理内存。
至此,try_async_pf 得到了物理页面,并且转换为对应的物理页号。
接下来,__direct_map 会关联客户机物理页号和宿主机物理页号。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
static int __direct_map(struct kvm_vcpu *vcpu, int write, int map_writable,
int level, gfn_t gfn, kvm_pfn_t pfn, bool prefault)
{
struct kvm_shadow_walk_iterator iterator;
struct kvm_mmu_page *sp;
int emulate = 0;
gfn_t pseudo_gfn;
if (!VALID_PAGE(vcpu->arch.mmu.root_hpa))
return 0;
for_each_shadow_entry(vcpu, (u64)gfn << PAGE_SHIFT, iterator) {
if (iterator.level == level) {
emulate = mmu_set_spte(vcpu, iterator.sptep, ACC_ALL,
write, level, gfn, pfn, prefault,
map_writable);
direct_pte_prefetch(vcpu, iterator.sptep);
++vcpu->stat.pf_fixed;
break;
}
drop_large_spte(vcpu, iterator.sptep);
if (!is_shadow_present_pte(*iterator.sptep)) {
u64 base_addr = iterator.addr;
base_addr &= PT64_LVL_ADDR_MASK(iterator.level);
pseudo_gfn = base_addr >> PAGE_SHIFT;
sp = kvm_mmu_get_page(vcpu, pseudo_gfn, iterator.addr,
iterator.level - 1, 1, ACC_ALL);
link_shadow_page(vcpu, iterator.sptep, sp);
}
}
return emulate;
}
|
__direct_map 首先判断页表的根是否存在,当然存在,我们刚才初始化了。
接下来是 for_each_shadow_entry 一个循环。每一个循环中,先是会判断需要映射的 level,是否正是当前循环的这个 iterator.level。如果是,则说明是叶子节点,直接映射真正的物理页面 pfn,然后退出。接着是非叶子节点的情形,判断如果这一项指向的页表项不存在,就要建立页表项,通过 kvm_mmu_get_page 得到保存页表项的页面,然后将这一项指向下一级的页表页面。
至此,内存映射就结束了。
总结时刻
我们这里来总结一下,虚拟机的内存管理也是需要用户态的 qemu 和内核态的 KVM 共同完成。为了加速内存映射,需要借助硬件的 EPT 技术。
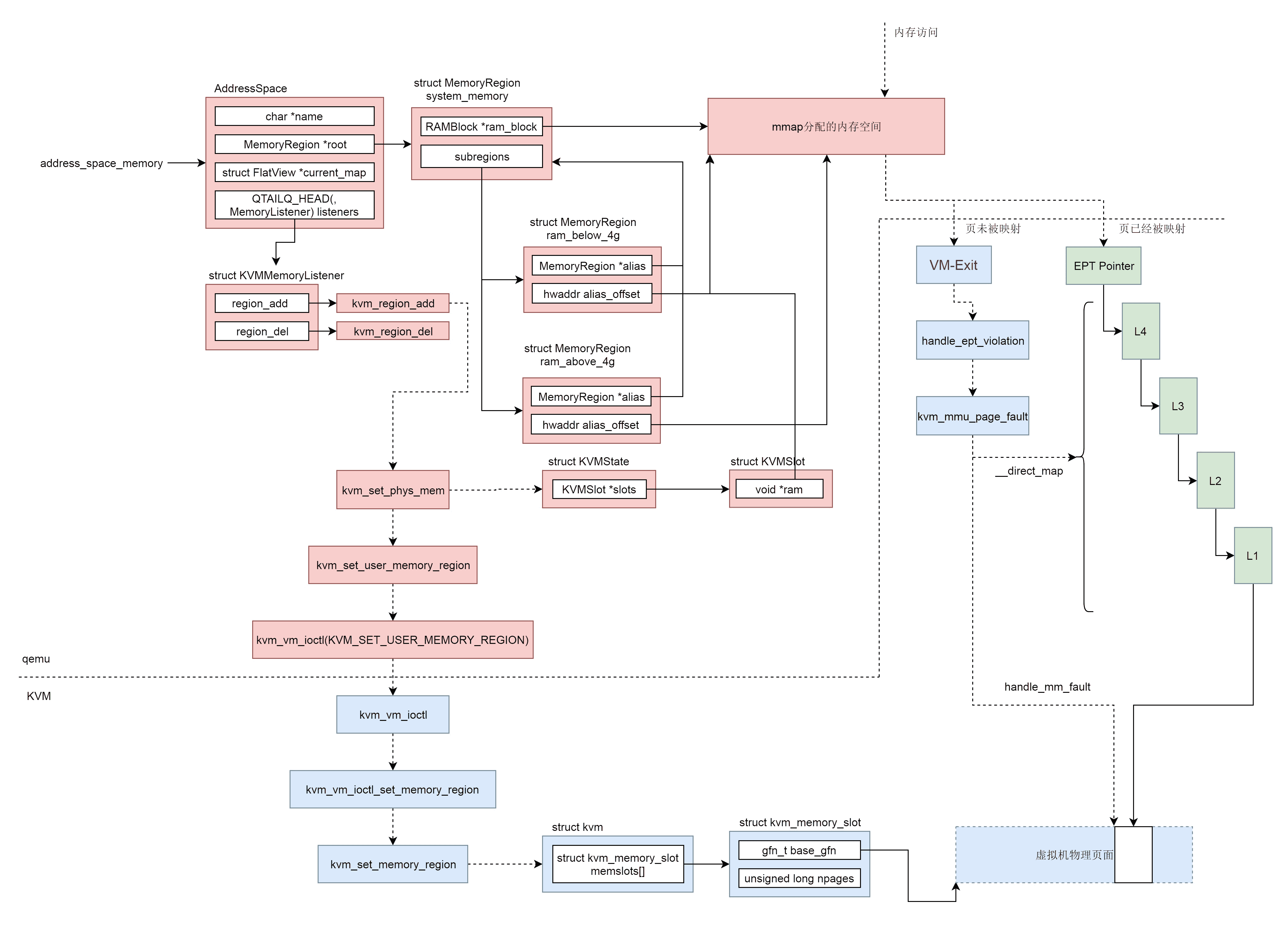
在用户态 qemu 中,有一个结构 AddressSpace address_space_memory 来表示虚拟机的系统内存,这个内存可能包含多个内存区域 struct MemoryRegion,组成树形结构,指向由 mmap 分配的虚拟内存。
在 AddressSpace 结构中,有一个 struct KVMMemoryListener,当有新的内存区域添加的时候,会被通知调用 kvm_region_add 来通知内核。
在用户态 qemu 中,对于虚拟机有一个结构 struct KVMState 表示这个虚拟机,这个结构会指向一个数组的 struct KVMSlot 表示这个虚拟机的多个内存条,KVMSlot 中有一个 void *ram 指针指向 mmap 分配的那块虚拟内存。
kvm_region_add 是通过 ioctl 来通知内核 KVM 的,会给内核 KVM 发送一个 KVM_SET_USER_MEMORY_REGION 消息,表示用户态 qemu 添加了一个内存区域,内核 KVM 也应该添加一个相应的内存区域。
和用户态 qemu 对应的内核 KVM,对于虚拟机有一个结构 struct kvm 表示这个虚拟机,这个结构会指向一个数组的 struct kvm_memory_slot 表示这个虚拟机的多个内存条,kvm_memory_slot 中有起始页号,页面数目,表示这个虚拟机的物理内存空间。
虚拟机的物理内存空间里面的页面当然不是一开始就映射到物理页面的,只有当虚拟机的内存被访问的时候,也即 mmap 分配的虚拟内存空间被访问的时候,先查看 EPT 页表,是否已经映射过,如果已经映射过,则经过四级页表映射,就能访问到物理页面。
如果没有映射过,则虚拟机会通过 VM-Exit 指令回到宿主机模式,通过 handle_ept_violation 补充页表映射。先是通过 handle_mm_fault 为虚拟机的物理内存空间分配真正的物理页面,然后通过 __direct_map 添加 EPT 页表映射。
课堂练习
这一节,影子页表我们没有深入去讲,你能自己研究一下,它是如何实现的吗?
欢迎留言和我分享你的疑惑和见解,也欢迎收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
