63|知识串讲:用一个创业故事串起操作系统原理(二)
文章目录
上一节说到小马同学的公司已经创立了,还请来了周瑜和张昭作为帮手,所谓“兄弟齐心,其利断金”。可是,现在这家公司,还得从接第一个外部项目开始。
首个项目虽简单,项目管理成体系

这第一个项目,还是小马亲自去谈的。其实软件公司了解客户需求还是比较难的,因为客户都说着接近人类的语言,例如 C/C++。这些咱们公司招聘的 CPU 小伙伴们可听不懂,需要有一个人将客户需求,转换为项目执行计划书,CPU 小伙伴们才能执行,这个过程我们称为编译。
编译其实是一个需求分析和需求转换的过程。这个过程会将接近人类的 C/C++ 语言,转换为 CPU 小伙伴能够听懂的二进制语言,并且以一定的文档格式,写成项目执行计划书。这种文档格式是作为一个标准化的公司事先制定好的一种格式,是周瑜从大公司里面借鉴来的,称为 ELF 格式,这个项目执行计划书有总论 ELF Header 的部分,有包含指令的代码段的部分,有包含全局变量的数据段的部分。
小马和客户聊了整整一天,确认了项目的每一个细节,保证编译能够通过,才写成项目执行计划书 ELF 文件,放到档案库中。此时已经半夜了。
第二天,周瑜一到公司,小马就兴奋地给周瑜说,“我昨天接到了第一个项目,而且是一个大项目,项目执行计划书我都写好了,你帮我监督、执行、管理,记得按时交付哦!”
周瑜说,“没问题。”于是,周瑜从父项目开始,fork 一个子项目,然后在子项目中,调用 exec 系统调用,然后到了内核里面,通过 load_elf_binary 将项目执行计划书加载到子进程内存中,交给一个 CPU 执行。
虽然这是第一个项目,以周瑜的项目管理经验,他告诉小马,项目的执行要保质保量,需要有一套项目管理系统来管理项目的状态,而不能靠脑子记。“项目管理系统?当然应该有了”,小马说。他在《企业经营宝典》中看到过。
于是,项目管理系统就搭建起来了。在这里面,所有项目都放在一个 task_struct 列表中,对于每一个项目,都非常详细地登记了项目方方面面的信息。

每一个项目都应该有一个 ID,作为这个项目的唯一标识。到时候排期啊、下发任务啊等等,都按 ID 来,就不会产生歧义。
项目应该有运行中的状态,TASK_RUNNING 并不是说进程正在运行,而是表示进程在时刻准备运行的状态。这个时候,要看 CPU 小伙伴有没有空,有空就运行他,没空就得等着。
有时候,进程运行到一半,需要等待某个条件才能运行下去,这个时候只能睡眠。睡眠状态有两种。一种是 TASK_INTERRUPTIBLE,可中断的睡眠状态。这是一种浅睡眠的状态,也就是说,虽然在睡眠,等条件成熟,进程可以被唤醒。
另一种睡眠是 TASK_UNINTERRUPTIBLE,不可中断的睡眠状态。这是一种深度睡眠状态,不可被唤醒,只能死等条件满足。有了一种新的进程睡眠状态,TASK_KILLABLE,可以终止的新睡眠状态。进程处于这种状态中,他的运行原理类似 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号,也即虽然在深度睡眠,但是可以被干掉。
一旦一个进程要结束,先进入的是 EXIT_ZOMBIE 状态,但是这个时候他的父进程还没有使用 wait() 等系统调用来获知他的终止信息,此时进程就成了僵尸进程。
EXIT_DEAD 是进程的最终状态。

另外,项目运行的统计信息也非常重要。例如,有的员工很长时间都在做一个任务,这个时候你就需要特别关注一下;再如,有的员工的琐碎任务太多,这会大大影响他的工作效率。
那如何才能知道这些员工的工作情况呢?在进程的运行过程中,会有一些统计量,例如进程在用户态和内核态消耗的时间、上下文切换的次数等等。
项目之间的亲缘关系也需要维护,任何一个进程都有父进程。所以,整个进程其实就是一棵进程树。而拥有同一父进程的所有进程都具有兄弟关系。

另外,对于项目来讲,项目组权限的控制也很重要。什么是项目组权限控制呢?这么说吧,我这个项目组能否访问某个文件,能否访问其他的项目组,以及我这个项目组能否被其他项目组访问等等
另外,项目运行过程中占用的公司的资源,例如会议室(内存)、档案库(文件系统)也需要在项目管理系统里面登记。
周瑜同学将项目登记好,然后就分配给 CPU 同学们说,开始执行吧。
好在第一个项目还是比较简单的,一个 CPU 同学按照项目执行计划书按部就班一条条的执行,很快就完成了,客户评价还不错,很快收到了回款。
项目大了要并行,项目多了要排期
小马很开心,可谓开门红。接着,第二个项目就到来了,这可是一个大项目,要帮一家知名公司开发一个交易网站,共 200 个页面,这下要赚翻了,就是时间要的比较急,要求两个星期搞定。
小马把项目带回来,周瑜同学说,这个项目有点大,估计一个 CPU 同学干不过来了,估计要多个 CPU 同学一起协作了。
为了完成这个大的项目(进程),就不能一个人从头干到尾了,这样肯定赶不上工期。于是,周瑜将一个大项目拆分成 20 个子项目,每个子项目完成 10 个页面,一个大项目组也分成 20 个小组,并行开发,都开发完了,再做一次整合,这肯定比依次开发 200 个页面快多了。如果项目叫进程,那子项目就叫线程。
在 Linux 里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务,由一个统一的结构 task_struct 进行管理。
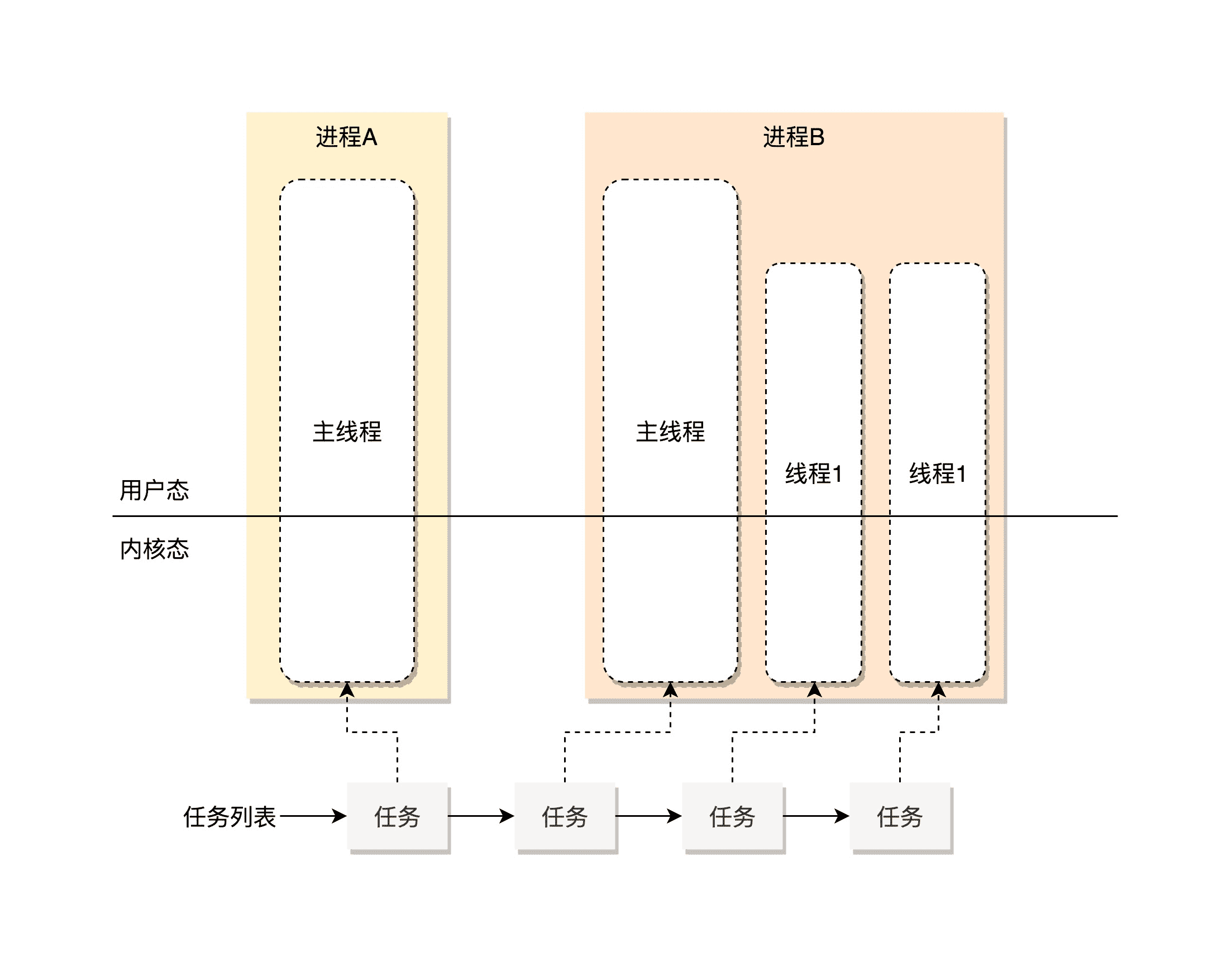
不知道是好消息,还是坏消息,这么大一个项目还没有做完,新的项目又找上门了。看来有了前面的标杆客户,名声算是打出去了,一个项目接一个地不停。
小马是既高兴,又犯愁,于是找周瑜和张昭商量应该咋办。要不多招人?多来几个 CPU 小伙伴,就不搞定了?可是咱们还是在创业阶段,养不起这么多人。另外的办法就是,人力复用,一个 CPU 小伙伴干多个项目,干不过来,就加加班,实在不行就 996,这样应该就没问题了。
一旦涉及一个 CPU 小伙伴同时参与多个项目,就非常考验项目管理的水平了。如何排期、如何调度,是一个大学问。例如,有的项目比较紧急,应该先进行排期;有的项目可以缓缓,但是也不能让客户等太久。所以这个过程非常复杂,需要平衡。
对于操作系统来讲,他面对的 CPU 的数量是有限的,干活儿都是他们,但是进程数目远远超过 CPU 的数目,因而就需要进行进程的调度,有效地分配 CPU 的时间,既要保证进程的最快响应,也要保证进程之间的公平。
如何调度呢?周瑜能够想到的方式就是排队。每一个 CPU 小伙伴旁边都有一个白板,上面写着自己需要完成的任务,来了新任务就写到白板上,做完了就擦掉。
一个 CPU 上有一个队列,队列里面是一系列 sched_entity,每个 sched_entity 都属于一个 task_struct,代表进程或者线程。
调度要解决的第一个问题是,每一个 CPU 小伙伴每过一段时间,都要想一下,白板上这么多项目,我应该干哪一个?CPU 的队列里面有这么多的进程或者线程,应该取出哪一个来执行?

这就是调度规则或者调度算法的问题。
周瑜说,他原来在大公司的时候,调度算法常用是这样设计的。
一个是公平性,对于接到的多个项目,不能厚此薄彼。这个算法主要由 fair_sched_class 实现,fair 就是公平的意思。
另一个是优先级,有的项目要急一点,客户出的钱多,所以应该多分配一些精力在高优先级的项目里面。
在 Linux 里面,讲究的公平可不是一般的公平,而是 CFS 调度算法,CFS 全称是 Completely Fair Scheduling,完全公平调度。
为了公平,项目经理需要记录下进程的运行时间。CPU 会提供一个时钟,过一段时间就触发一个时钟中断。就像咱们的表滴答一下,这个我们叫 Tick。CFS 会为每一个进程安排一个虚拟运行时间 vruntime。如果一个进程在运行,随着时间的增长,也就是一个个 Tick 的到来,进程的 vruntime 将不断增大。没有得到执行的进程 vruntime 不变。
显然,那些 vruntime 少的,原来受到了不公平的对待,需要给他补上,所以会优先运行这样的进程。
这有点儿像让你把一筐球平均分到 N 个口袋里面,你看着哪个少,就多放一些;哪个多了,就先不放。这样经过多轮,虽然不能保证球完全一样多,但是也差不多公平。
有时候,进程会分优先级,如何给优先级高的进程多分时间呢?
这个简单,就相当于 N 个口袋,优先级高的袋子大,优先级低的袋子小。这样球就不能按照个数分配了,要按照比例来,大口袋的放了一半和小口袋放了一半,里面的球数目虽然差很多,也认为是公平的。
函数 update_curr 用于更新进程运行的统计量 vruntime,CFS 还需要一个数据结构来对 vruntime 进行排序,找出最小的那个。在这里使用的是红黑树。红黑树的的节点是 sched_entity,里面包含 vruntime。
调度算法的本质就是解决下一个进程应该轮到谁运行的问题,这个逻辑在 fair_sched_class.pick_next_task 中完成。
调度要解决的第二个问题是,什么时候切换任务?也即,什么时候,CPU 小伙伴应该停下一个进程,换另一个进程运行?
一个人在做 A 项目,在某个时刻,换成做 B 项目去了。发生这种情况,主要有两种方式。
方式一,A 项目做着做着,里面有一条指令 sleep,也就是要休息一下,或者等待某个 I/O 事件。那没办法了,要主动让出 CPU,然后可以开始做 B 项目。主动让出 CPU 的进程,会主动调用 schedule() 函数。
在 schedule() 函数中,会通过 fair_sched_class.pick_next_task,在红黑树形成的队列上取出下一个进程,然后调用 context_switch 进行进程上下文切换。
进程上下文切换主要干两件事情,一是切换进程空间,也即进程的内存,也即 CPU 小伙伴不能 A 项目的会议室里面干活了,要跑到 B 项目的会议室去。二是切换寄存器和 CPU 上下文,也即 CPU 将当期在 A 项目中干到哪里了,记录下来,方便以后接着干。
方式二,A 项目做着做着,旷日持久,实在受不了了。项目经理介入了,说这个项目 A 先停停,B 项目也要做一下,要不然 B 项目该投诉了。最常见的现象就是,A 进程执行时间太长了,是时候切换到 B 进程了。这个时候叫作 A 进程被被动抢占。
抢占还要通过 CPU 的时钟 Tick,来衡量进程的运行时间。时钟 Tick 一下,是很好查看是否需要抢占的时间点。时钟中断处理函数会调用 scheduler_tick(),他会调用 fair_sched_class 的 task_tick_fair,在这里面会调用 update_curr 更新运行时间。当发现当前进程应该被抢占,不能直接把他踢下来,而是把他标记为应该被抢占,打上一个标签 TIF_NEED_RESCHED。
另外一个可能抢占的场景发生在,当一个进程被唤醒的时候。一个进程在等待一个 I/O 的时候,会主动放弃 CPU。但是,当 I/O 到来的时候,进程往往会被唤醒。这个时候是一个时机。当被唤醒的进程优先级高于 CPU 上的当前进程,就会触发抢占。如果应该发生抢占,也不是直接踢走当然进程,而也是将当前进程标记为应该被抢占,打上一个标签 TIF_NEED_RESCHED。
真正的抢占还是需要上下文切换,也就是需要那么一个时刻,让正在运行中的进程有机会调用一下 schedule。调用 schedule 有以下四个时机。
- 对于用户态的进程来讲,从系统调用中返回的那个时刻,是一个被抢占的时机。
- 对于用户态的进程来讲,从中断中返回的那个时刻,也是一个被抢占的时机。
- 对内核态的执行中,被抢占的时机一般发生在 preempt_enable() 中。在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调用 preempt_disable() 关闭抢占。再次打开的时候,就是一次内核态代码被抢占的机会。
- 在内核态也会遇到中断的情况,当中断返回的时候,返回的仍然是内核态。这个时候也是一个执行抢占的时机。
周瑜和张昭商定了这个规则,然后给 CPU 小伙伴们交代之后,项目虽然越来越多,但是也井井有条起来。CPU 小伙伴不会像原来一样火急火燎,不知所从了。
可是其实对于项目的开发,这家公司还是有严重漏洞的,就是项目的保密问题,不管哪家客户将系统外包出去,肯定也不想让其他公司知道详情。如果解决不好这个问题,没人敢把重要的项目交给这家公司,小马的公司也就永远只能接点边角系统,还是不能保证温饱问题。
那接下来,小马会怎么解决项目之间的保密问题呢?欲知后事,且听下回分解。

文章作者 anonymous
上次更新 2024-04-12