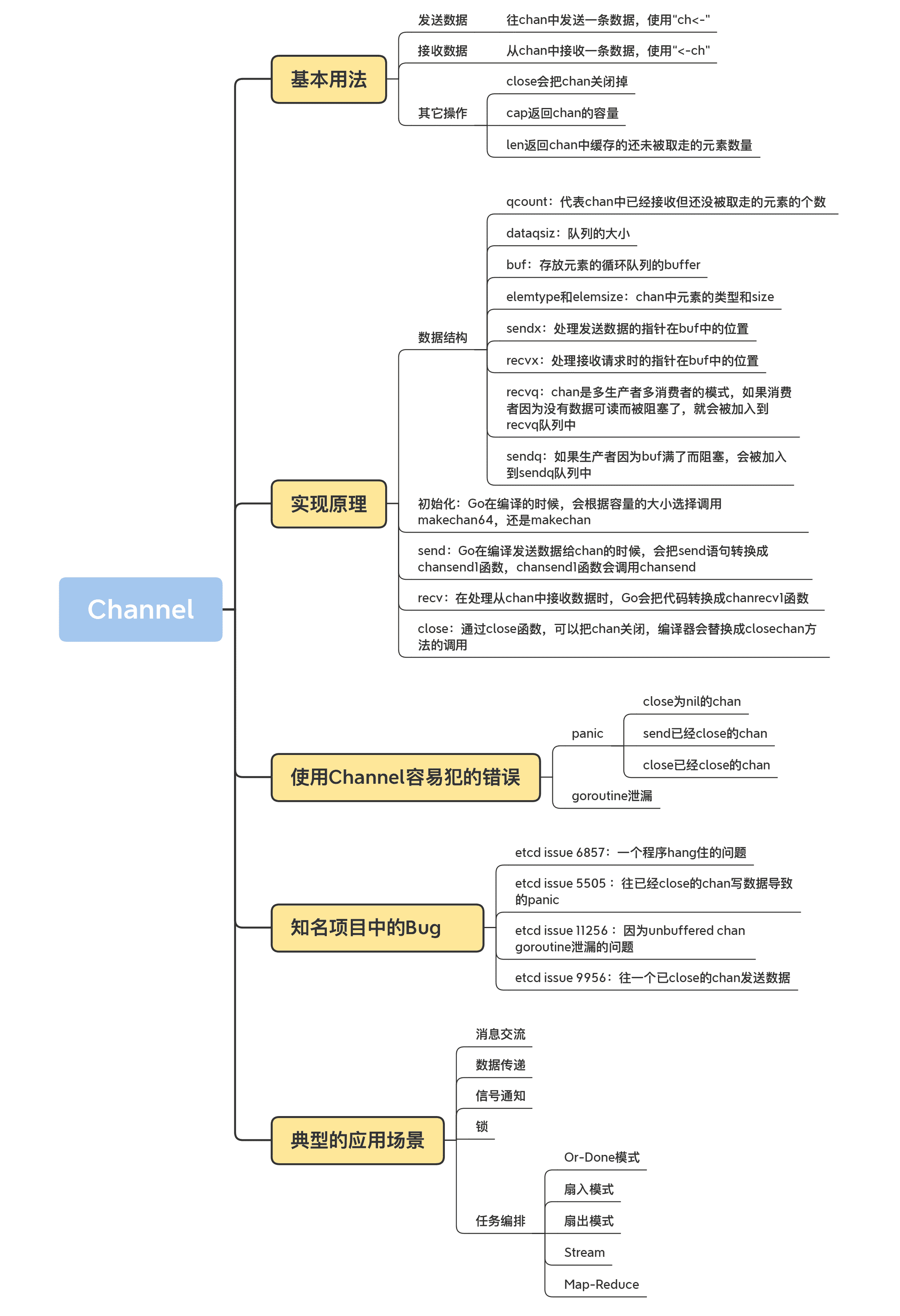
14|Channel:透过代码看典型的应用模式
文章目录
你好,我是鸟窝。
前一讲,我介绍了 Channel 的基础知识,并且总结了几种应用场景。这一讲,我将通过实例的方式,带你逐个学习 Channel 解决这些问题的方法,帮你巩固和完全掌握它的用法。
在开始上课之前,我先补充一个知识点:通过反射的方式执行 select 语句,在处理很多的 case clause,尤其是不定长的 case clause 的时候,非常有用。而且,在后面介绍任务编排的实现时,我也会采用这种方法,所以,我先带你具体学习下 Channel 的反射用法。
使用反射操作 Channel
select 语句可以处理 chan 的 send 和 recv,send 和 recv 都可以作为 case clause。如果我们同时处理两个 chan,就可以写成下面的样子:
select {
case v := <-ch1:
fmt.Println(v)
case v := <-ch2:
fmt.Println(v)
}
如果需要处理三个 chan,你就可以再添加一个 case clause,用它来处理第三个 chan。可是,如果要处理 100 个 chan 呢?一万个 chan 呢?
或者是,chan 的数量在编译的时候是不定的,在运行的时候需要处理一个 slice of chan,这个时候,也没有办法在编译前写成字面意义的 select。那该怎么办?
这个时候,就要“祭”出我们的反射大法了。
通过 reflect.Select 函数,你可以将一组运行时的 case clause 传入,当作参数执行。Go 的 select 是伪随机的,它可以在执行的 case 中随机选择一个 case,并把选择的这个 case 的索引(chosen)返回,如果没有可用的 case 返回,会返回一个 bool 类型的返回值,这个返回值用来表示是否有 case 成功被选择。如果是 recv case,还会返回接收的元素。Select 的方法签名如下:
func Select(cases []SelectCase) (chosen int, recv Value, recvOK bool)
下面,我来借助一个例子,来演示一下,动态处理两个 chan 的情形。因为这样的方式可以动态处理 case 数据,所以,你可以传入几百几千几万的 chan,这就解决了不能动态处理 n 个 chan 的问题。
首先,createCases 函数分别为每个 chan 生成了 recv case 和 send case,并返回一个 reflect.SelectCase 数组。
然后,通过一个循环 10 次的 for 循环执行 reflect.Select,这个方法会从 cases 中选择一个 case 执行。第一次肯定是 send case,因为此时 chan 还没有元素,recv 还不可用。等 chan 中有了数据以后,recv case 就可以被选择了。这样,你就可以处理不定数量的 chan 了。
func main() {
var ch1 = make(chan int, 10)
var ch2 = make(chan int, 10)
// 创建 SelectCase
var cases = createCases(ch1, ch2)
// 执行 10 次 select
for i := 0; i < 10; i++ {
chosen, recv, ok := reflect.Select(cases)
if recv.IsValid() { // recv case
fmt.Println("recv:", cases[chosen].Dir, recv, ok)
} else { // send case
fmt.Println("send:", cases[chosen].Dir, ok)
}
}
}
func createCases(chs …chan int) []reflect.SelectCase {
var cases []reflect.SelectCase
// 创建 recv case
for _, ch := range chs {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(ch),
})
}
// 创建 send case
for i, ch := range chs {
v := reflect.ValueOf(i)
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectSend,
Chan: reflect.ValueOf(ch),
Send: v,
})
}
return cases
}
典型的应用场景
了解刚刚的反射用法,我们就解决了今天的基础知识问题,接下来,我就带你具体学习下 Channel 的应用场景。
首先来看消息交流。
消息交流
从 chan 的内部实现看,它是以一个循环队列的方式存放数据,所以,它有时候也会被当成线程安全的队列和 buffer 使用。一个 goroutine 可以安全地往 Channel 中塞数据,另外一个 goroutine 可以安全地从 Channel 中读取数据,goroutine 就可以安全地实现信息交流了。
我们来看几个例子。
第一个例子是 worker 池的例子。Marcio Castilho 在 使用 Go 每分钟处理百万请求 这篇文章中,就介绍了他们应对大并发请求的设计。他们将用户的请求放在一个 chan Job 中,这个 chan Job 就相当于一个待处理任务队列。除此之外,还有一个 chan chan Job 队列,用来存放可以处理任务的 worker 的缓存队列。
dispatcher 会把待处理任务队列中的任务放到一个可用的缓存队列中,worker 会一直处理它的缓存队列。通过使用 Channel,实现了一个 worker 池的任务处理中心,并且解耦了前端 HTTP 请求处理和后端任务处理的逻辑。
我在讲 Pool 的时候,提到了一些第三方实现的 worker 池,它们全部都是通过 Channel 实现的,这是 Channel 的一个常见的应用场景。worker 池的生产者和消费者的消息交流都是通过 Channel 实现的。
第二个例子是 etcd 中的 node 节点的实现,包含大量的 chan 字段,比如 recvc 是消息处理的 chan,待处理的 protobuf 消息都扔到这个 chan 中,node 有一个专门的 run goroutine 处理这些消息。

数据传递
“击鼓传花”的游戏很多人都玩过,花从一个人手中传给另外一个人,就有点类似流水线的操作。这个花就是数据,花在游戏者之间流转,这就类似编程中的数据传递。
还记得上节课我给你留了一道任务编排的题吗?其实它就可以用数据传递的方式实现。
有 4 个 goroutine,编号为 1、2、3、4。每秒钟会有一个 goroutine 打印出它自己的编号,要求你编写程序,让输出的编号总是按照 1、2、3、4、1、2、3、4……这个顺序打印出来。
为了实现顺序的数据传递,我们可以定义一个令牌的变量,谁得到令牌,谁就可以打印一次自己的编号,同时将令牌传递给下一个 goroutine,我们尝试使用 chan 来实现,可以看下下面的代码。
type Token struct{}
func newWorker(id int, ch chan Token, nextCh chan Token) {
for {
token := <-ch // 取得令牌
fmt.Println((id + 1)) // id 从 1 开始
time.Sleep(time.Second)
nextCh <- token
}
}
func main() {
chs := []chan Token{make(chan Token), make(chan Token), make(chan Token), make(chan Token)}
// 创建 4 个 worker
for i := 0; i < 4; i++ {
go newWorker(i, chs[i], chs[(i+1)%4])
}
//首先把令牌交给第一个 worker
chs[0] <- struct{}{}
select {}
}
我来给你具体解释下这个实现方式。
首先,我们定义一个令牌类型(Token),接着定义一个创建 worker 的方法,这个方法会从它自己的 chan 中读取令牌。哪个 goroutine 取得了令牌,就可以打印出自己编号,因为需要每秒打印一次数据,所以,我们让它休眠 1 秒后,再把令牌交给它的下家。
接着,在第 16 行启动每个 worker 的 goroutine,并在第 20 行将令牌先交给第一个 worker。
如果你运行这个程序,就会在命令行中看到每一秒就会输出一个编号,而且编号是以 1、2、3、4 这样的顺序输出的。
这类场景有一个特点,就是当前持有数据的 goroutine 都有一个信箱,信箱使用 chan 实现,goroutine 只需要关注自己的信箱中的数据,处理完毕后,就把结果发送到下一家的信箱中。
信号通知
chan 类型有这样一个特点:chan 如果为空,那么,receiver 接收数据的时候就会阻塞等待,直到 chan 被关闭或者有新的数据到来。利用这个机制,我们可以实现 wait/notify 的设计模式。
传统的并发原语 Cond 也能实现这个功能,但是,Cond 使用起来比较复杂,容易出错,而使用 chan 实现 wait/notify 模式就方便很多了。
除了正常的业务处理时的 wait/notify,我们经常碰到的一个场景,就是程序关闭的时候,我们需要在退出之前做一些清理(doCleanup 方法)的动作。这个时候,我们经常要使用 chan。
比如,使用 chan 实现程序的 graceful shutdown,在退出之前执行一些连接关闭、文件 close、缓存落盘等一些动作。
func main() {
go func() {
…… // 执行业务处理
}()
// 处理 CTRL+C 等中断信号
termChan := make(chan os.Signal)
signal.Notify(termChan, syscall.SIGINT, syscall.SIGTERM)
<-termChan
// 执行退出之前的清理动作
doCleanup()
fmt.Println(“优雅退出”)
}
有时候,doCleanup 可能是一个很耗时的操作,比如十几分钟才能完成,如果程序退出需要等待这么长时间,用户是不能接受的,所以,在实践中,我们需要设置一个最长的等待时间。只要超过了这个时间,程序就不再等待,可以直接退出。所以,退出的时候分为两个阶段:
- closing,代表程序退出,但是清理工作还没做;
- closed,代表清理工作已经做完。
所以,上面的例子可以改写如下:
func main() {
var closing = make(chan struct{})
var closed = make(chan struct{})
go func() {
// 模拟业务处理
for {
select {
case <-closing:
return
default:
// ....... 业务计算
time.Sleep(100 * time.Millisecond)
}
}
}()
// 处理 CTRL+C 等中断信号
termChan := make(chan os.Signal)
signal.Notify(termChan, syscall.SIGINT, syscall.SIGTERM)
<-termChan
close(closing)
// 执行退出之前的清理动作
go doCleanup(closed)
select {
case <-closed:
case <-time.After(time.Second):
fmt.Println("清理超时,不等了")
}
fmt.Println("优雅退出")
}
func doCleanup(closed chan struct{}) {
time.Sleep((time.Minute))
close(closed)
}
锁
使用 chan 也可以实现互斥锁。
在 chan 的内部实现中,就有一把互斥锁保护着它的所有字段。从外在表现上,chan 的发送和接收之间也存在着 happens-before 的关系,保证元素放进去之后,receiver 才能读取到(关于 happends-before 的关系,是指事件发生的先后顺序关系,我会在下一讲详细介绍,这里你只需要知道它是一种描述事件先后顺序的方法)。
要想使用 chan 实现互斥锁,至少有两种方式。一种方式是先初始化一个 capacity 等于 1 的 Channel,然后再放入一个元素。这个元素就代表锁,谁取得了这个元素,就相当于获取了这把锁。另一种方式是,先初始化一个 capacity 等于 1 的 Channel,它的“空槽”代表锁,谁能成功地把元素发送到这个 Channel,谁就获取了这把锁。
这是使用 Channel 实现锁的两种不同实现方式,我重点介绍下第一种。理解了这种实现方式,第二种方式也就很容易掌握了,我就不多说了。
// 使用 chan 实现互斥锁
type Mutex struct {
ch chan struct{}
}
// 使用锁需要初始化
func NewMutex() *Mutex {
mu := &Mutex{make(chan struct{}, 1)}
mu.ch <- struct{}{}
return mu
}
// 请求锁,直到获取到
func (m *Mutex) Lock() {
<-m.ch
}
// 解锁
func (m *Mutex) Unlock() {
select {
case m.ch <- struct{}{}:
default:
panic(“unlock of unlocked mutex”)
}
}
// 尝试获取锁
func (m *Mutex) TryLock() bool {
select {
case <-m.ch:
return true
default:
}
return false
}
// 加入一个超时的设置
func (m *Mutex) LockTimeout(timeout time.Duration) bool {
timer := time.NewTimer(timeout)
select {
case <-m.ch:
timer.Stop()
return true
case <-timer.C:
}
return false
}
// 锁是否已被持有
func (m *Mutex) IsLocked() bool {
return len(m.ch) == 0
}
func main() {
m := NewMutex()
ok := m.TryLock()
fmt.Printf(“locked v %v\n”, ok)
ok = m.TryLock()
fmt.Printf(“locked %v\n”, ok)
}
你可以用 buffer 等于 1 的 chan 实现互斥锁,在初始化这个锁的时候往 Channel 中先塞入一个元素,谁把这个元素取走,谁就获取了这把锁,把元素放回去,就是释放了锁。元素在放回到 chan 之前,不会有 goroutine 能从 chan 中取出元素的,这就保证了互斥性。
在这段代码中,还有一点需要我们注意下:利用 select+chan 的方式,很容易实现 TryLock、Timeout 的功能。具体来说就是,在 select 语句中,我们可以使用 default 实现 TryLock,使用一个 Timer 来实现 Timeout 的功能。
任务编排
前面所说的消息交流的场景是一个特殊的任务编排的场景,这个“击鼓传花”的模式也被称为流水线模式。
在第 6 讲,我们学习了 WaitGroup,我们可以利用它实现等待模式:启动一组 goroutine 执行任务,然后等待这些任务都完成。其实,我们也可以使用 chan 实现 WaitGroup 的功能。这个比较简单,我就不举例子了,接下来我介绍几种更复杂的编排模式。
这里的编排既指安排 goroutine 按照指定的顺序执行,也指多个 chan 按照指定的方式组合处理的方式。goroutine 的编排类似“击鼓传花”的例子,我们通过编排数据在 chan 之间的流转,就可以控制 goroutine 的执行。接下来,我来重点介绍下多个 chan 的编排方式,总共 5 种,分别是 Or-Done 模式、扇入模式、扇出模式、Stream 和 Map-Reduce。
Or-Done 模式
首先来看 Or-Done 模式。Or-Done 模式是信号通知模式中更宽泛的一种模式。这里提到了“信号通知模式”,我先来解释一下。
我们会使用“信号通知”实现某个任务执行完成后的通知机制,在实现时,我们为这个任务定义一个类型为 chan struct{}类型的 done 变量,等任务结束后,我们就可以 close 这个变量,然后,其它 receiver 就会收到这个通知。
这是有一个任务的情况,如果有多个任务,只要有任意一个任务执行完,我们就想获得这个信号,这就是 Or-Done 模式。
比如,你发送同一个请求到多个微服务节点,只要任意一个微服务节点返回结果,就算成功,这个时候,就可以参考下面的实现:
func or(channels …<-chan interface{}) <-chan interface{} {
// 特殊情况,只有零个或者 1 个 chan
switch len(channels) {
case 0:
return nil
case 1:
return channels[0]
}
orDone := make(chan interface{})
go func() {
defer close(orDone)
switch len(channels) {
case 2: // 2 个也是一种特殊情况
select {
case <-channels[0]:
case <-channels[1]:
}
default: //超过两个,二分法递归处理
m := len(channels) / 2
select {
case <-or(channels[:m]...):
case <-or(channels[m:]...):
}
}
}()
return orDone
}
我们可以写一个测试程序测试它:
func sig(after time.Duration) <-chan interface{} {
c := make(chan interface{})
go func() {
defer close(c)
time.Sleep(after)
}()
return c
}
func main() {
start := time.Now()
<-or(
sig(10*time.Second),
sig(20*time.Second),
sig(30*time.Second),
sig(40*time.Second),
sig(50*time.Second),
sig(01*time.Minute),
)
fmt.Printf("done after %v", time.Since(start))
}
这里的实现使用了一个巧妙的方式,当 chan 的数量大于 2 时,使用递归的方式等待信号。
在 chan 数量比较多的情况下,递归并不是一个很好的解决方式,根据这一讲最开始介绍的反射的方法,我们也可以实现 Or-Done 模式:
func or(channels …<-chan interface{}) <-chan interface{} {
//特殊情况,只有 0 个或者 1 个
switch len(channels) {
case 0:
return nil
case 1:
return channels[0]
}
orDone := make(chan interface{})
go func() {
defer close(orDone)
// 利用反射构建 SelectCase
var cases []reflect.SelectCase
for _, c := range channels {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(c),
})
}
// 随机选择一个可用的 case
reflect.Select(cases)
}()
return orDone
}
这是递归和反射两种方法实现 Or-Done 模式的代码。反射方式避免了深层递归的情况,可以处理有大量 chan 的情况。其实最笨的一种方法就是为每一个 Channel 启动一个 goroutine,不过这会启动非常多的 goroutine,太多的 goroutine 会影响性能,所以不太常用。你只要知道这种用法就行了,不用重点掌握。
扇入模式
扇入借鉴了数字电路的概念,它定义了单个逻辑门能够接受的数字信号输入最大量的术语。一个逻辑门可以有多个输入,一个输出。
在软件工程中,模块的扇入是指有多少个上级模块调用它。而对于我们这里的 Channel 扇入模式来说,就是指有多个源 Channel 输入、一个目的 Channel 输出的情况。扇入比就是源 Channel 数量比 1。
每个源 Channel 的元素都会发送给目标 Channel,相当于目标 Channel 的 receiver 只需要监听目标 Channel,就可以接收所有发送给源 Channel 的数据。
扇入模式也可以使用反射、递归,或者是用最笨的每个 goroutine 处理一个 Channel 的方式来实现。
这里我列举下递归和反射的方式,帮你加深一下对这个技巧的理解。
反射的代码比较简短,易于理解,主要就是构造出 SelectCase slice,然后传递给 reflect.Select 语句。
func fanInReflect(chans …<-chan interface{}) <-chan interface{} {
out := make(chan interface{})
go func() {
defer close(out)
// 构造 SelectCase slice
var cases []reflect.SelectCase
for _, c := range chans {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(c),
})
}
// 循环,从 cases 中选择一个可用的
for len(cases) > 0 {
i, v, ok := reflect.Select(cases)
if !ok { // 此 channel 已经 close
cases = append(cases[:i], cases[i+1:]...)
continue
}
out <- v.Interface()
}
}()
return out
}
递归模式也是在 Channel 大于 2 时,采用二分法递归 merge。
func fanInRec(chans …<-chan interface{}) <-chan interface{} {
switch len(chans) {
case 0:
c := make(chan interface{})
close(c)
return c
case 1:
return chans[0]
case 2:
return mergeTwo(chans[0], chans[1])
default:
m := len(chans) / 2
return mergeTwo(
fanInRec(chans[:m]…),
fanInRec(chans[m:]…))
}
}
这里有一个 mergeTwo 的方法,是将两个 Channel 合并成一个 Channel,是扇入形式的一种特例(只处理两个 Channel)。下面我来借助一段代码帮你理解下这个方法。
func mergeTwo(a, b <-chan interface{}) <-chan interface{} {
c := make(chan interface{})
go func() {
defer close(c)
for a != nil || b != nil { //只要还有可读的 chan
select {
case v, ok := <-a:
if !ok { // a 已关闭,设置为 nil
a = nil
continue
}
c <- v
case v, ok := <-b:
if !ok { // b 已关闭,设置为 nil
b = nil
continue
}
c <- v
}
}
}()
return c
}
扇出模式
有扇入模式,就有扇出模式,扇出模式是和扇入模式相反的。
扇出模式只有一个输入源 Channel,有多个目标 Channel,扇出比就是 1 比目标 Channel 数的值,经常用在设计模式中的观察者模式中(观察者设计模式定义了对象间的一种一对多的组合关系。这样一来,一个对象的状态发生变化时,所有依赖于它的对象都会得到通知并自动刷新)。在观察者模式中,数据变动后,多个观察者都会收到这个变更信号。
下面是一个扇出模式的实现。从源 Channel 取出一个数据后,依次发送给目标 Channel。在发送给目标 Channel 的时候,可以同步发送,也可以异步发送:
func fanOut(ch <-chan interface{}, out []chan interface{}, async bool) {
go func() {
defer func() { //退出时关闭所有的输出 chan
for i := 0; i < len(out); i++ {
close(out[i])
}
}()
for v := range ch { // 从输入 chan 中读取数据
v := v
for i := 0; i < len(out); i++ {
i := i
if async { //异步
go func() {
out[i] <- v // 放入到输出 chan 中,异步方式
}()
} else {
out[i] <- v // 放入到输出 chan 中,同步方式
}
}
}
}()
}
你也可以尝试使用反射的方式来实现,我就不列相关代码了,希望你课后可以自己思考下。
Stream
这里我来介绍一种把 Channel 当作流式管道使用的方式,也就是把 Channel 看作流(Stream),提供跳过几个元素,或者是只取其中的几个元素等方法。
首先,我们提供创建流的方法。这个方法把一个数据 slice 转换成流:
func asStream(done <-chan struct{}, values …interface{}) <-chan interface{} {
s := make(chan interface{}) //创建一个 unbuffered 的 channel
go func() { // 启动一个 goroutine,往 s 中塞数据
defer close(s) // 退出时关闭 chan
for _, v := range values { // 遍历数组
select {
case <-done:
return
case s <- v: // 将数组元素塞入到 chan 中
}
}
}()
return s
}
流创建好以后,该咋处理呢?下面我再给你介绍下实现流的方法。
- takeN:只取流中的前 n 个数据;
- takeFn:筛选流中的数据,只保留满足条件的数据;
- takeWhile:只取前面满足条件的数据,一旦不满足条件,就不再取;
- skipN:跳过流中前几个数据;
- skipFn:跳过满足条件的数据;
- skipWhile:跳过前面满足条件的数据,一旦不满足条件,当前这个元素和以后的元素都会输出给 Channel 的 receiver。
这些方法的实现很类似,我们以 takeN 为例来具体解释一下。
func takeN(done <-chan struct{}, valueStream <-chan interface{}, num int) <-chan interface{} {
takeStream := make(chan interface{}) // 创建输出流
go func() {
defer close(takeStream)
for i := 0; i < num; i++ { // 只读取前 num 个元素
select {
case <-done:
return
case takeStream <- <-valueStream: //从输入流中读取元素
}
}
}()
return takeStream
}
Map-Reduce
map-reduce 是一种处理数据的方式,最早是由 Google 公司研究提出的一种面向大规模数据处理的并行计算模型和方法,开源的版本是 hadoop,前几年比较火。
不过,我要讲的并不是分布式的 map-reduce,而是单机单进程的 map-reduce 方法。
map-reduce 分为两个步骤,第一步是映射(map),处理队列中的数据,第二步是规约(reduce),把列表中的每一个元素按照一定的处理方式处理成结果,放入到结果队列中。
就像做汉堡一样,map 就是单独处理每一种食材,reduce 就是从每一份食材中取一部分,做成一个汉堡。
我们先来看下 map 函数的处理逻辑:
func mapChan(in <-chan interface{}, fn func(interface{}) interface{}) <-chan interface{} {
out := make(chan interface{}) //创建一个输出 chan
if in == nil { // 异常检查
close(out)
return out
}
go func() { // 启动一个 goroutine,实现 map 的主要逻辑
defer close(out)
for v := range in { // 从输入 chan 读取数据,执行业务操作,也就是 map 操作
out <- fn(v)
}
}()
return out
}
reduce 函数的处理逻辑如下:
func reduce(in <-chan interface{}, fn func(r, v interface{}) interface{}) interface{} {
if in == nil { // 异常检查
return nil
}
out := <-in // 先读取第一个元素
for v := range in { // 实现 reduce 的主要逻辑
out = fn(out, v)
}
return out
}
我们可以写一个程序,这个程序使用 map-reduce 模式处理一组整数,map 函数就是为每个整数乘以 10,reduce 函数就是把 map 处理的结果累加起来:
// 生成一个数据流
func asStream(done <-chan struct{}) <-chan interface{} {
s := make(chan interface{})
values := []int{1, 2, 3, 4, 5}
go func() {
defer close(s)
for _, v := range values { // 从数组生成
select {
case <-done:
return
case s <- v:
}
}
}()
return s
}
func main() {
in := asStream(nil)
// map 操作:乘以 10
mapFn := func(v interface{}) interface{} {
return v.(int) * 10
}
// reduce 操作:对 map 的结果进行累加
reduceFn := func(r, v interface{}) interface{} {
return r.(int) + v.(int)
}
sum := reduce(mapChan(in, mapFn), reduceFn) //返回累加结果
fmt.Println(sum)
}
总结
这节课,我借助代码示例,带你学习了 Channel 的应用场景和应用模式。这几种模式不是我们学习的终点,而是学习的起点。掌握了这几种模式之后,我们可以延伸出更多的模式。
虽然 Channel 最初是基于 CSP 设计的用于 goroutine 之间的消息传递的一种数据类型,但是,除了消息传递这个功能之外,大家居然还演化出了各式各样的应用模式。我不确定 Go 的创始人在设计这个类型的时候,有没有想到这一点,但是,我确实被各位大牛利用 Channel 的各种点子折服了,比如有人实现了一个基于 TCP 网络的分布式的 Channel。
在使用 Go 开发程序的时候,你也不妨多考虑考虑是否能够使用 chan 类型,看看你是不是也能创造出别具一格的应用模式。
思考题
想一想,我们在利用 chan 实现互斥锁的时候,如果 buffer 设置的不是 1,而是一个更大的值,会出现什么状况吗?能解决什么问题吗?
欢迎在留言区写下你的思考和答案,我们一起交流讨论。如果你觉得有所收获,也欢迎你把今天的内容分享给你的朋友或同事。
文章作者 anonymous
上次更新 2024-01-16