07|SocketServer(上):Kafka到底是怎么应用NIO实现网络通信的?
文章目录
你好,我是胡夕。这节课我们来说说 Kafka 底层的 NIO 通信机制源码。
在谈到 Kafka 高性能、高吞吐量实现原理的时候,很多人都对它使用了 Java NIO 这件事津津乐道。实际上,搞懂“Kafka 究竟是怎么应用 NIO 来实现网络通信的”,不仅是我们掌握 Kafka 请求全流程处理的前提条件,对我们了解 Reactor 模式的实现大有裨益,而且还能帮助我们解决很多实际问题。
比如说,当 Broker 处理速度很慢、需要优化的时候,你只有明确知道 SocketServer 组件的工作原理,才能制定出恰当的解决方案,并有针对性地给出对应的调优参数。
那么,今天,我们就一起拿下这个至关重要的 NIO 通信机制吧。
网络通信层
在深入学习 Kafka 各个网络组件之前,我们先从整体上看一下完整的网络通信层架构,如下图所示:

可以看出,Kafka 网络通信组件主要由两大部分构成:SocketServer 和 KafkaRequestHandlerPool。
SocketServer 组件是核心,主要实现了 Reactor 模式,用于处理外部多个 Clients(这里的 Clients 指的是广义的 Clients,可能包含 Producer、Consumer 或其他 Broker)的并发请求,并负责将处理结果封装进 Response 中,返还给 Clients。
KafkaRequestHandlerPool 组件就是我们常说的 I/O 线程池,里面定义了若干个 I/O 线程,用于执行真实的请求处理逻辑。
两者的交互点在于 SocketServer 中定义的 RequestChannel 对象和 Processor 线程。对了,我所说的线程,在代码中本质上都是 Runnable 类型,不管是 Acceptor 类、Processor 类,还是后面我们会单独讨论的 KafkaRequestHandler 类。
讲到这里,我稍微提示你一下。在第 9 节课,我会给出 KafkaRequestHandlerPool 线程池的详细介绍。但你现在需要知道的是,KafkaRequestHandlerPool 线程池定义了多个 KafkaRequestHandler 线程,而 KafkaRequestHandler 线程是真正处理请求逻辑的地方。和 KafkaRequestHandler 相比,今天所说的 Acceptor 和 Processor 线程从某种意义上来说,只能算是请求和响应的“搬运工”罢了。
了解了完整的网络通信层架构之后,我们要重点关注一下 SocketServer 组件。这个组件是 Kafka 网络通信层中最重要的子模块。它下辖的 Acceptor 线程、Processor 线程和 RequestChannel 等对象,都是实施网络通信的重要组成部分。你可能会感到意外的是,这套线程组合在源码中有多套,分别具有不同的用途。在下节课,我会具体跟你分享一下,不同的线程组合会被应用到哪些实际场景中。
下面我们进入到 SocketServer 组件的学习。
SocketServer 概览
SocketServer 组件的源码位于 Kafka 工程的 core 包下,具体位置是 src/main/scala/kafka/network 路径下的 SocketServer.scala 文件。
SocketServer.scala 可谓是元老级的源码文件了。在 Kafka 的源码演进历史中,很多代码文件进进出出,这个文件却一直“坚强地活着”,而且还在不断完善。如果翻开它的 Git 修改历史,你会发现,它最早的修改提交历史可回溯到 2011 年 8 月,足见它的资历之老。
目前,SocketServer.scala 文件是一个近 2000 行的大文件,共有 8 个代码部分。我使用一张思维导图帮你梳理下:
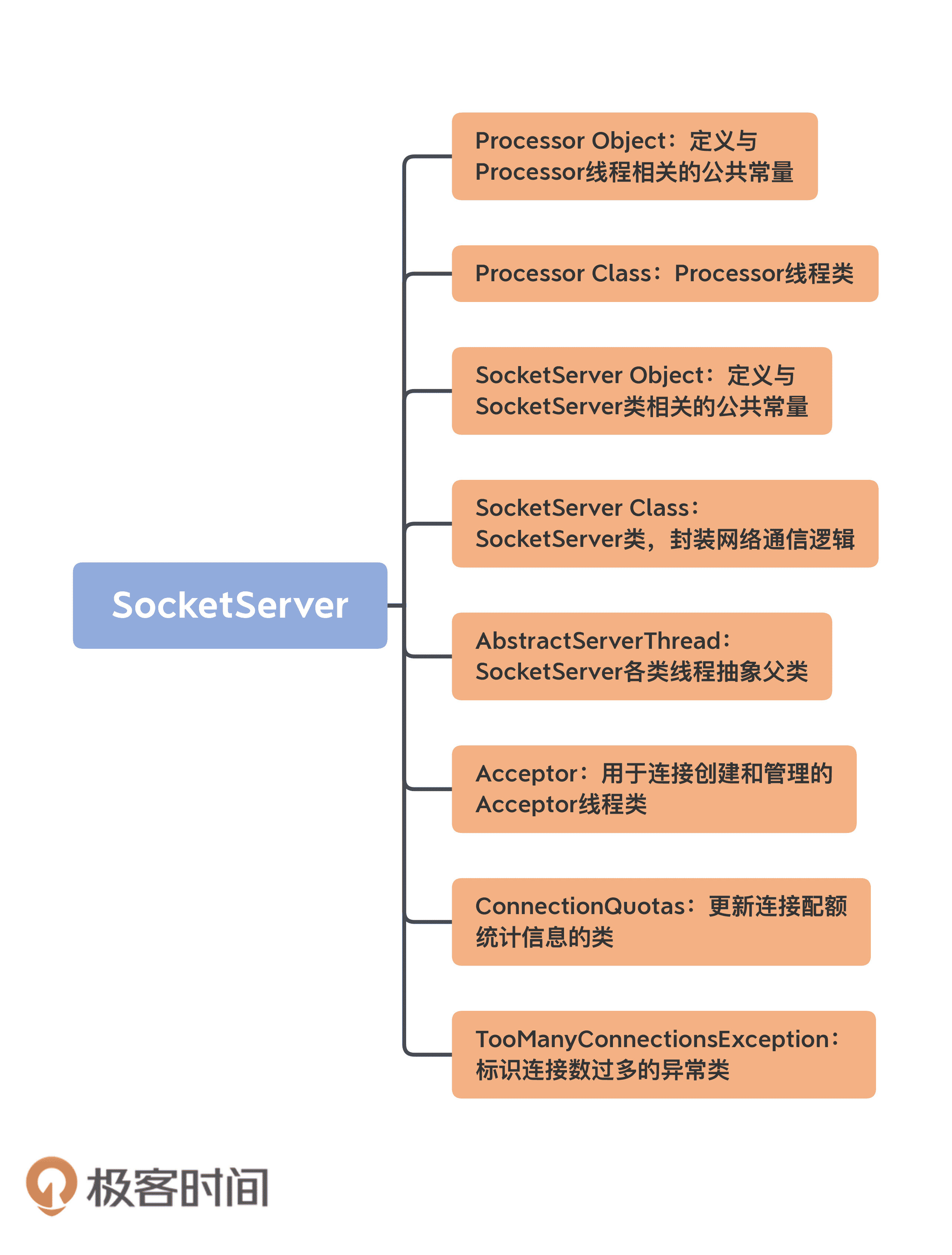
乍一看组件有很多,但你也不必担心,我先对这些组件做个简单的介绍,然后我们重点学习一下 Acceptor 类和 Processor 类的源码。毕竟,这两个类是实现网络通信的关键部件。另外,今天我给出的都是 SocketServer 组件的基本情况介绍,下节课我再详细向你展示它的定义。
1.AbstractServerThread 类:这是 Acceptor 线程和 Processor 线程的抽象基类,定义了这两个线程的公有方法,如 shutdown(关闭线程)等。我不会重点展开这个抽象类的代码,但你要重点关注下 CountDownLatch 类在线程启动和线程关闭时的作用。
如果你苦于寻找 Java 线程安全编程的最佳实践案例,那一定不要错过 CountDownLatch 这个类。Kafka 中的线程控制代码大量使用了基于 CountDownLatch 的编程技术,依托于它来实现优雅的线程启动、线程关闭等操作。因此,我建议你熟练掌握它们,并应用到你日后的工作当中去。
2.Acceptor 线程类:这是接收和创建外部 TCP 连接的线程。每个 SocketServer 实例只会创建一个 Acceptor 线程。它的唯一目的就是创建连接,并将接收到的 Request 传递给下游的 Processor 线程处理。
3.Processor 线程类:这是处理单个 TCP 连接上所有请求的线程。每个 SocketServer 实例默认创建若干个(num.network.threads)Processor 线程。Processor 线程负责将接收到的 Request 添加到 RequestChannel 的 Request 队列上,同时还负责将 Response 返还给 Request 发送方。
4.Processor 伴生对象类:仅仅定义了一些与 Processor 线程相关的常见监控指标和常量等,如 Processor 线程空闲率等。
5.ConnectionQuotas 类:是控制连接数配额的类。我们能够设置单个 IP 创建 Broker 连接的最大数量,以及单个 Broker 能够允许的最大连接数。
6.TooManyConnectionsException 类:SocketServer 定义的一个异常类,用于标识连接数配额超限情况。
7.SocketServer 类:实现了对以上所有组件的管理和操作,如创建和关闭 Acceptor、Processor 线程等。
8.SocketServer 伴生对象类:定义了一些有用的常量,同时明确了 SocketServer 组件中的哪些参数是允许动态修改的。
Acceptor 线程
经典的 Reactor 模式有个 Dispatcher 的角色,接收外部请求并分发给下面的实际处理线程。在 Kafka 中,这个 Dispatcher 就是 Acceptor 线程。
我们看下它的定义:
private[kafka] class Acceptor(val endPoint: EndPoint,
val sendBufferSize: Int,
val recvBufferSize: Int,
brokerId: Int,
connectionQuotas: ConnectionQuotas,
metricPrefix: String) extends AbstractServerThread(connectionQuotas) with KafkaMetricsGroup {
// 创建底层的 NIO Selector 对象
// Selector 对象负责执行底层实际 I/O 操作,如监听连接创建请求、读写请求等
private val nioSelector = NSelector.open()
// Broker 端创建对应的 ServerSocketChannel 实例
// 后续把该 Channel 向上一步的 Selector 对象注册
val serverChannel = openServerSocket(endPoint.host, endPoint.port)
// 创建 Processor 线程池,实际上是 Processor 线程数组
private val processors = new ArrayBufferProcessor
private val processorsStarted = new AtomicBoolean
private val blockedPercentMeter = newMeter(s"${metricPrefix}AcceptorBlockedPercent",
“blocked time”, TimeUnit.NANOSECONDS, Map(ListenerMetricTag -> endPoint.listenerName.value))
……
}
从定义来看,Acceptor 线程接收 5 个参数,其中比较重要的有 3 个。
- endPoint。它就是你定义的 Kafka Broker 连接信息,比如 PLAINTEXT://localhost:9092。Acceptor 需要用到 endPoint 包含的主机名和端口信息创建 Server Socket。
- sendBufferSize。它设置的是 SocketOptions 的 SO_SNDBUF,即用于设置出站(Outbound)网络 I/O 的底层缓冲区大小。该值默认是 Broker 端参数 socket.send.buffer.bytes 的值,即 100KB。
- recvBufferSize。它设置的是 SocketOptions 的 SO_RCVBUF,即用于设置入站(Inbound)网络 I/O 的底层缓冲区大小。该值默认是 Broker 端参数 socket.receive.buffer.bytes 的值,即 100KB。
说到这儿,我想给你提一个优化建议。如果在你的生产环境中,Clients 与 Broker 的通信网络延迟很大(比如 RTT>10ms),那么我建议你调大控制缓冲区大小的两个参数,也就是 sendBufferSize 和 recvBufferSize。通常来说,默认值 100KB 太小了。
除了类定义的字段,Acceptor 线程还有两个非常关键的自定义属性。
- nioSelector:是 Java NIO 库的 Selector 对象实例,也是后续所有网络通信组件实现 Java NIO 机制的基础。如果你不熟悉 Java NIO,那么我推荐你学习这个系列教程:Java NIO。
- processors:网络 Processor 线程池。Acceptor 线程在初始化时,需要创建对应的网络 Processor 线程池。可见,Processor 线程是在 Acceptor 线程中管理和维护的。
既然如此,那它就必须要定义相关的方法。Acceptor 代码中,提供了 3 个与 Processor 相关的方法,分别是 addProcessors、startProcessors 和 removeProcessors。鉴于它们的代码都非常简单,我用注释的方式给出主体逻辑的步骤:
addProcessors
private[network] def addProcessors(
newProcessors: Buffer[Processor], processorThreadPrefix: String): Unit = synchronized {
processors ++= newProcessors // 添加一组新的 Processor 线程
if (processorsStarted.get) // 如果 Processor 线程池已经启动
startProcessors(newProcessors, processorThreadPrefix) // 启动新的 Processor 线程
}
startProcessors
private[network] def startProcessors(processorThreadPrefix: String): Unit = synchronized {
if (!processorsStarted.getAndSet(true)) { // 如果 Processor 线程池未启动
startProcessors(processors, processorThreadPrefix) // 启动给定的 Processor 线程
}
}
private def startProcessors(processors: Seq[Processor], processorThreadPrefix: String): Unit = synchronized {
processors.foreach { processor => // 依次创建并启动 Processor 线程
// 线程命名规范:processor 线程前缀-kafka-network-thread-broker 序号 - 监听器名称 - 安全协议-Processor 序号
// 假设为序号为 0 的 Broker 设置 PLAINTEXT://localhost:9092 作为连接信息,那么 3 个 Processor 线程名称分别为:
// data-plane-kafka-network-thread-0-ListenerName(PLAINTEXT)-PLAINTEXT-0
// data-plane-kafka-network-thread-0-ListenerName(PLAINTEXT)-PLAINTEXT-1
// data-plane-kafka-network-thread-0-ListenerName(PLAINTEXT)-PLAINTEXT-2
KafkaThread.nonDaemon(s"${processorThreadPrefix}-kafka-network-thread-$brokerId-${endPoint.listenerName}-${endPoint.securityProtocol}-${processor.id}", processor).start()
}
}
removeProcessors
private[network] def removeProcessors(removeCount: Int, requestChannel: RequestChannel): Unit = synchronized {
// 获取 Processor 线程池中最后 removeCount 个线程
val toRemove = processors.takeRight(removeCount)
// 移除最后 removeCount 个线程
processors.remove(processors.size - removeCount, removeCount)
// 关闭最后 removeCount 个线程
toRemove.foreach(_.shutdown())
// 在 RequestChannel 中移除这些 Processor
toRemove.foreach(processor => requestChannel.removeProcessor(processor.id))
}
为了更加形象地展示这些方法的逻辑,我画了一张图,它同时包含了这 3 个方法的执行流程,如下图所示:

刚才我们学到的 addProcessors、startProcessors 和 removeProcessors 方法是管理 Processor 线程用的。应该这么说,有了这三个方法,Acceptor 类就具备了基本的 Processor 线程池管理功能。不过,Acceptor 类逻辑的重头戏其实是 run 方法,它是处理 Reactor 模式中分发逻辑的主要实现方法。下面我使用注释的方式给出 run 方法的大体运行逻辑,如下所示:
def run(): Unit = {
//注册 OP_ACCEPT 事件
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
// 等待 Acceptor 线程启动完成
startupComplete()
try {
// 当前使用的 Processor 序号,从 0 开始,最大值是 num.network.threads - 1
var currentProcessorIndex = 0
while (isRunning) {
try {
// 每 500 毫秒获取一次就绪 I/O 事件
val ready = nioSelector.select(500)
if (ready > 0) { // 如果有 I/O 事件准备就绪
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
while (iter.hasNext && isRunning) {
try {
val key = iter.next
iter.remove()
if (key.isAcceptable) {
// 调用 accept 方法创建 Socket 连接
accept(key).foreach { socketChannel =>
var retriesLeft = synchronized(processors.length)
var processor: Processor = null
do {
retriesLeft -= 1
// 指定由哪个 Processor 线程进行处理
processor = synchronized {
currentProcessorIndex = currentProcessorIndex % processors.length
processors(currentProcessorIndex)
}
// 更新 Processor 线程序号
currentProcessorIndex += 1
} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0)) // Processor 是否接受了该连接
}
} else
throw new IllegalStateException(“Unrecognized key state for acceptor thread.”)
} catch {
case e: Throwable => error(“Error while accepting connection”, e)
}
}
}
}
catch {
case e: ControlThrowable => throw e
case e: Throwable => error(“Error occurred”, e)
}
}
} finally { // 执行各种资源关闭逻辑
debug(“Closing server socket and selector.”)
CoreUtils.swallow(serverChannel.close(), this, Level.ERROR)
CoreUtils.swallow(nioSelector.close(), this, Level.ERROR)
shutdownComplete()
}
}
看上去代码似乎有点多,我再用一张图来说明一下 run 方法的主要处理逻辑吧。这里的关键点在于,Acceptor 线程会先为每个入站请求确定要处理它的 Processor 线程,然后调用 assignNewConnection 方法令 Processor 线程创建与发送方的连接。

基本上,Acceptor 线程使用 Java NIO 的 Selector + SocketChannel 的方式循环地轮询准备就绪的 I/O 事件。这里的 I/O 事件,主要是指网络连接创建事件,即代码中的 SelectionKey.OP_ACCEPT。一旦接收到外部连接请求,Acceptor 就会指定一个 Processor 线程,并将该请求交由它,让它创建真正的网络连接。总的来说,Acceptor 线程就做这么点事。
Processor 线程
下面我们进入到 Processor 线程源码的学习。
如果说 Acceptor 是做入站连接处理的,那么,Processor 代码则是真正创建连接以及分发请求的地方。显然,它要做的事情远比 Acceptor 要多得多。我先给出 Processor 线程的 run 方法,你大致感受一下:
override def run(): Unit = {
startupComplete() // 等待 Processor 线程启动完成
try {
while (isRunning) {
try {
configureNewConnections() // 创建新连接
// register any new responses for writing
processNewResponses() // 发送 Response,并将 Response 放入到 inflightResponses 临时队列
poll() // 执行 NIO poll,获取对应 SocketChannel 上准备就绪的 I/O 操作
processCompletedReceives() // 将接收到的 Request 放入 Request 队列
processCompletedSends() // 为临时 Response 队列中的 Response 执行回调逻辑
processDisconnected() // 处理因发送失败而导致的连接断开
closeExcessConnections() // 关闭超过配额限制部分的连接
} catch {
case e: Throwable => processException(“Processor got uncaught exception.”, e)
}
}
} finally { // 关闭底层资源
debug(s"Closing selector - processor $id")
CoreUtils.swallow(closeAll(), this, Level.ERROR)
shutdownComplete()
}
}
run 方法逻辑被切割得相当好,各个子方法的边界非常清楚。因此,从整体上看,该方法呈现出了面向对象领域中非常难得的封装特性。我使用一张图来展示下该方法要做的事情:
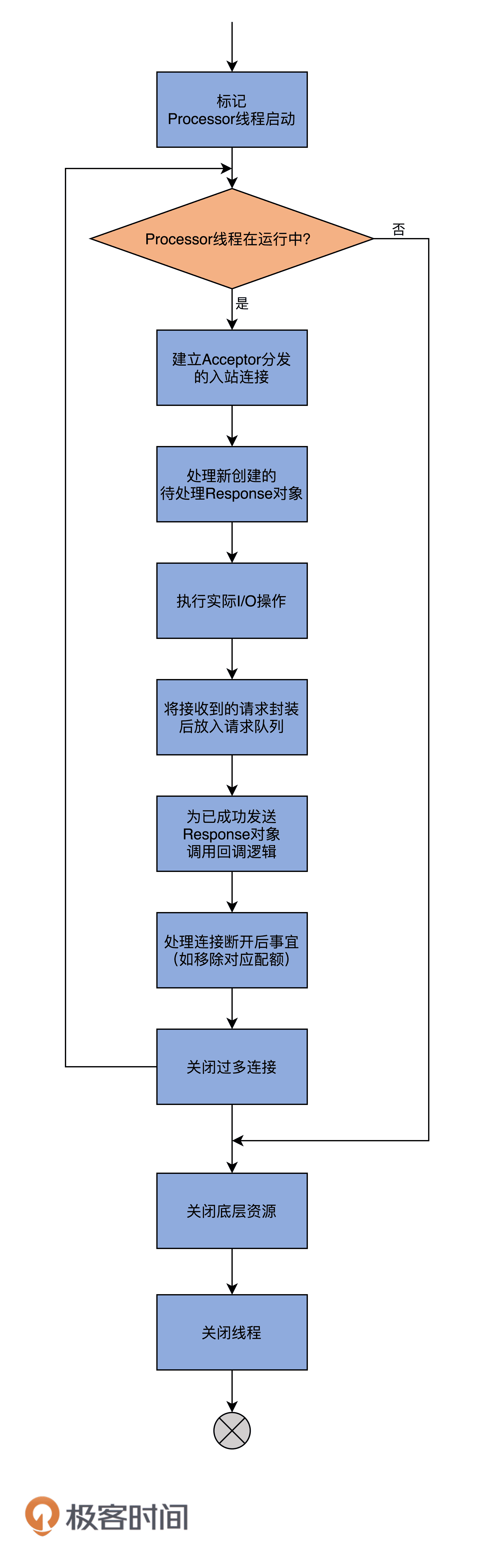
在详细说 run 方法之前,我们先来看下 Processor 线程初始化时要做的事情。
每个 Processor 线程在创建时都会创建 3 个队列。注意,这里的队列是广义的队列,其底层使用的数据结构可能是阻塞队列,也可能是一个 Map 对象而已,如下所示:
private val newConnections = new ArrayBlockingQueueSocketChannel
private val inflightResponses = mutable.MapString, RequestChannel.Response
private val responseQueue = new LinkedBlockingDequeRequestChannel.Response
队列一:newConnections
它保存的是要创建的新连接信息,具体来说,就是 SocketChannel 对象。这是一个默认上限是 20 的队列,而且,目前代码中硬编码了队列的长度,因此,你无法变更这个队列的长度。
每当 Processor 线程接收新的连接请求时,都会将对应的 SocketChannel 放入这个队列。后面在创建连接时(也就是调用 configureNewConnections 时),就从该队列中取出 SocketChannel,然后注册新的连接。
队列二:inflightResponses
严格来说,这是一个临时 Response 队列。当 Processor 线程将 Response 返还给 Request 发送方之后,还要将 Response 放入这个临时队列。
为什么需要这个临时队列呢?这是因为,有些 Response 回调逻辑要在 Response 被发送回发送方之后,才能执行,因此需要暂存在一个临时队列里面。这就是 inflightResponses 存在的意义。
队列三:responseQueue
看名字我们就可以知道,这是 Response 队列,而不是 Request 队列。这告诉了我们一个事实:每个 Processor 线程都会维护自己的 Response 队列,而不是像网上的某些文章说的,Response 队列是线程共享的或是保存在 RequestChannel 中的。Response 队列里面保存着需要被返还给发送方的所有 Response 对象。
好了,了解了这些之后,现在我们来深入地查看一下 Processor 线程的工作逻辑。根据 run 方法中的方法调用顺序,我先来介绍下 configureNewConnections 方法。
configureNewConnections
就像我前面所说的,configureNewConnections 负责处理新连接请求。接下来,我用注释的方式给出这个方法的主体逻辑:
private def configureNewConnections(): Unit = {
var connectionsProcessed = 0 // 当前已配置的连接数计数器
while (connectionsProcessed < connectionQueueSize && !newConnections.isEmpty) { // 如果没超配额并且有待处理新连接
val channel = newConnections.poll() // 从连接队列中取出 SocketChannel
try {
debug(s"Processor $id listening to new connection from ${channel.socket.getRemoteSocketAddress}")
// 用给定 Selector 注册该 Channel
// 底层就是调用 Java NIO 的 SocketChannel.register(selector, SelectionKey.OP_READ)
selector.register(connectionId(channel.socket), channel)
connectionsProcessed += 1 // 更新计数器
} catch {
case e: Throwable =>
val remoteAddress = channel.socket.getRemoteSocketAddress
close(listenerName, channel)
processException(s"Processor $id closed connection from $remoteAddress", e)
}
}
}
该方法最重要的逻辑是调用 selector 的 register 来注册 SocketChannel。每个 Processor 线程都维护了一个 Selector 类实例。Selector 类是社区提供的一个基于 Java NIO Selector 的接口,用于执行非阻塞多通道的网络 I/O 操作。在核心功能上,Kafka 提供的 Selector 和 Java 提供的是一致的。
processNewResponses
它负责发送 Response 给 Request 发送方,并且将 Response 放入临时 Response 队列。处理逻辑如下:
private def processNewResponses(): Unit = {
var currentResponse: RequestChannel.Response = null
while ({currentResponse = dequeueResponse(); currentResponse != null}) { // Response 队列中存在待处理 Response
val channelId = currentResponse.request.context.connectionId // 获取连接通道 ID
try {
currentResponse match {
case response: NoOpResponse => // 无需发送 Response
updateRequestMetrics(response)
trace(s"Socket server received empty response to send, registering for read: $response")
handleChannelMuteEvent(channelId, ChannelMuteEvent.RESPONSE_SENT)
tryUnmuteChannel(channelId)
case response: SendResponse => // 发送 Response 并将 Response 放入 inflightResponses
sendResponse(response, response.responseSend)
case response: CloseConnectionResponse => // 关闭对应的连接
updateRequestMetrics(response)
trace(“Closing socket connection actively according to the response code.”)
close(channelId)
case _: StartThrottlingResponse =>
handleChannelMuteEvent(channelId, ChannelMuteEvent.THROTTLE_STARTED)
case _: EndThrottlingResponse =>
handleChannelMuteEvent(channelId, ChannelMuteEvent.THROTTLE_ENDED)
tryUnmuteChannel(channelId)
case _ =>
throw new IllegalArgumentException(s"Unknown response type: ${currentResponse.getClass}")
}
} catch {
case e: Throwable =>
processChannelException(channelId, s"Exception while processing response for $channelId", e)
}
}
}
这里的关键是 SendResponse 分支上的 sendResponse 方法。这个方法的核心代码其实只有三行:
if (openOrClosingChannel(connectionId).isDefined) { // 如果该连接处于可连接状态
selector.send(responseSend) // 发送 Response
inflightResponses += (connectionId -> response) // 将 Response 加入到 inflightResponses 队列
}
poll
严格来说,上面提到的所有发送的逻辑都不是执行真正的发送。真正执行 I/O 动作的方法是这里的 poll 方法。
poll 方法的核心代码就只有 1 行:selector.poll(pollTimeout)。在底层,它实际上调用的是 Java NIO Selector 的 select 方法去执行那些准备就绪的 I/O 操作,不管是接收 Request,还是发送 Response。因此,你需要记住的是,poll 方法才是真正执行 I/O 操作逻辑的地方。
processCompletedReceives
它是接收和处理 Request 的。代码如下:
private def processCompletedReceives(): Unit = {
// 遍历所有已接收的 Request
selector.completedReceives.asScala.foreach { receive =>
try {
// 保证对应连接通道已经建立
openOrClosingChannel(receive.source) match {
case Some(channel) =>
val header = RequestHeader.parse(receive.payload)
if (header.apiKey == ApiKeys.SASL_HANDSHAKE && channel.maybeBeginServerReauthentication(receive, nowNanosSupplier))
trace(s"Begin re-authentication: $channel")
else {
val nowNanos = time.nanoseconds()
// 如果认证会话已过期,则关闭连接
if (channel.serverAuthenticationSessionExpired(nowNanos)) {
debug(s"Disconnecting expired channel: $channel : $header")
close(channel.id)
expiredConnectionsKilledCount.record(null, 1, 0)
} else {
val connectionId = receive.source
val context = new RequestContext(header, connectionId, channel.socketAddress,
channel.principal, listenerName, securityProtocol,
channel.channelMetadataRegistry.clientInformation)
val req = new RequestChannel.Request(processor = id, context = context,
startTimeNanos = nowNanos, memoryPool, receive.payload, requestChannel.metrics)
if (header.apiKey == ApiKeys.API_VERSIONS) {
val apiVersionsRequest = req.body[ApiVersionsRequest]
if (apiVersionsRequest.isValid) {
channel.channelMetadataRegistry.registerClientInformation(new ClientInformation(
apiVersionsRequest.data.clientSoftwareName,
apiVersionsRequest.data.clientSoftwareVersion))
}
}
// 核心代码:将 Request 添加到 Request 队列
requestChannel.sendRequest(req)
selector.mute(connectionId)
handleChannelMuteEvent(connectionId, ChannelMuteEvent.REQUEST_RECEIVED)
}
}
case None =>
throw new IllegalStateException(s"Channel ${receive.source} removed from selector before processing completed receive")
}
} catch {
case e: Throwable =>
processChannelException(receive.source, s"Exception while processing request from ${receive.source}", e)
}
}
}
看上去代码有很多,但其实最核心的代码就只有 1 行:requestChannel.sendRequest(req),也就是将此 Request 放入 Request 队列。其他代码只是一些常规化的校验和辅助逻辑。
这个方法的意思是说,Processor 从底层 Socket 通道不断读取已接收到的网络请求,然后转换成 Request 实例,并将其放入到 Request 队列。整个逻辑还是很简单的,对吧?
processCompletedSends
它负责处理 Response 的回调逻辑。我之前说过,Response 需要被发送之后才能执行对应的回调逻辑,这便是该方法代码要实现的功能:
private def processCompletedSends(): Unit = {
// 遍历底层 SocketChannel 已发送的 Response
selector.completedSends.asScala.foreach { send =>
try {
// 取出对应 inflightResponses 中的 Response
val response = inflightResponses.remove(send.destination).getOrElse {
throw new IllegalStateException(s"Send for ${send.destination} completed, but not in inflightResponses")
}
updateRequestMetrics(response) // 更新一些统计指标
// 执行回调逻辑
response.onComplete.foreach(onComplete => onComplete(send))
handleChannelMuteEvent(send.destination, ChannelMuteEvent.RESPONSE_SENT)
tryUnmuteChannel(send.destination)
} catch {
case e: Throwable => processChannelException(send.destination,
s"Exception while processing completed send to ${send.destination}", e)
}
}
}
这里通过调用 Response 对象的 onComplete 方法,来实现回调函数的执行。
processDisconnected
顾名思义,它就是处理已断开连接的。该方法的逻辑很简单,我用注释标注了主要的执行步骤:
private def processDisconnected(): Unit = {
// 遍历底层 SocketChannel 的那些已经断开的连接
selector.disconnected.keySet.asScala.foreach { connectionId =>
try {
// 获取断开连接的远端主机名信息
val remoteHost = ConnectionId.fromString(connectionId).getOrElse {
throw new IllegalStateException(s"connectionId has unexpected format: $connectionId")
}.remoteHost
// 将该连接从 inflightResponses 中移除,同时更新一些监控指标
inflightResponses.remove(connectionId).foreach(updateRequestMetrics)
// 更新配额数据
connectionQuotas.dec(listenerName, InetAddress.getByName(remoteHost))
} catch {
case e: Throwable => processException(s"Exception while processing disconnection of $connectionId", e)
}
}
}
比较关键的代码是需要从底层 Selector 中获取那些已经断开的连接,之后把它们从 inflightResponses 中移除掉,同时也要更新它们的配额数据。
closeExcessConnections
这是 Processor 线程的 run 方法执行的最后一步,即关闭超限连接。代码很简单:
private def closeExcessConnections(): Unit = {
// 如果配额超限了
if (connectionQuotas.maxConnectionsExceeded(listenerName)) {
// 找出优先关闭的那个连接
val channel = selector.lowestPriorityChannel()
if (channel != null)
close(channel.id) // 关闭该连接
}
}
所谓优先关闭,是指在诸多 TCP 连接中找出最近未被使用的那个。这里“未被使用”就是说,在最近一段时间内,没有任何 Request 经由这个连接被发送到 Processor 线程。
总结
今天,我带你了解了 Kafka 网络通信层的全貌,大致介绍了核心组件 SocketServer,还花了相当多的时间研究 SocketServer 下的 Acceptor 和 Processor 线程代码。我们来简单总结一下。
- 网络通信层由 SocketServer 组件和 KafkaRequestHandlerPool 组件构成。
- SocketServer 实现了 Reactor 模式,用于高性能地并发处理 I/O 请求。
- SocketServer 底层使用了 Java 的 Selector 实现 NIO 通信。

在下节课,我会重点介绍 SocketServer 处理不同类型 Request 所做的设计及其对应的代码。这是社区为了提高 Broker 处理控制类请求的重大举措,也是为了改善 Broker 一致性所做的努力,非常值得我们重点关注。
课后讨论
最后,请思考这样一个问题:为什么 Request 队列被设计成线程共享的,而 Response 队列则是每个 Processor 线程专属的?
欢迎你在留言区畅所欲言,跟我交流讨论,也欢迎你把今天的内容分享给你的朋友。
文章作者 anonymous
上次更新 2024-05-03