25|ReplicaManager(下):副本管理器是如何管理副本的?
文章目录
你好,我是胡夕。
上节课我们学习了 ReplicaManager 类源码中副本管理器是如何执行副本读写操作的。现在我们知道了,这个副本读写操作主要是通过 appendRecords 和 fetchMessages 这两个方法实现的,而这两个方法其实在底层分别调用了 Log 的 append 和 read 方法,也就是我们在第 3 节课中学到的日志消息写入和日志消息读取方法。
今天,我们继续学习 ReplicaManager 类源码,看看副本管理器是如何管理副本的。这里的副本,涵盖了广义副本对象的方方面面,包括副本和分区对象、副本位移值和 ISR 管理等。因此,本节课我们结合着源码,具体学习下这几个方面。
分区及副本管理
除了对副本进行读写之外,副本管理器还有一个重要的功能,就是管理副本和对应的分区。ReplicaManager 管理它们的方式,是通过字段 allPartitions 来实现的。
所以,我想先带你复习下第 23 节课中的 allPartitions 的代码。不过,这次为了强调它作为容器的属性,我们要把注意力放在它是对象池这个特点上,即 allPartitions 把所有分区对象汇集在一起,统一放入到一个对象池进行管理。
private val allPartitions = new PoolTopicPartition, HostedPartition
从代码可以看到,每个 ReplicaManager 实例都维护了所在 Broker 上保存的所有分区对象,而每个分区对象 Partition 下面又定义了一组副本对象 Replica。通过这样的层级关系,副本管理器实现了对于分区的直接管理和对副本对象的间接管理。应该这样说,ReplicaManager 通过直接操作分区对象来间接管理下属的副本对象。
对于一个 Broker 而言,它管理下辖的分区和副本对象的主要方式,就是要确定在它保存的这些副本中,哪些是 Leader 副本、哪些是 Follower 副本。
这些划分可不是一成不变的,而是随着时间的推移不断变化的。比如说,这个时刻 Broker 是分区 A 的 Leader 副本、分区 B 的 Follower 副本,但在接下来的某个时刻,Broker 很可能变成分区 A 的 Follower 副本、分区 B 的 Leader 副本。
而这些变更是通过 Controller 给 Broker 发送 LeaderAndIsrRequest 请求来实现的。当 Broker 端收到这类请求后,会调用副本管理器的 becomeLeaderOrFollower 方法来处理,并依次执行“成为 Leader 副本”和“成为 Follower 副本”的逻辑,令当前 Broker 互换分区 A、B 副本的角色。
becomeLeaderOrFollower 方法
这里我们又提到了 LeaderAndIsrRequest 请求。其实,我们在学习 Controller 和控制类请求的时候就多次提到过它,在第 12 讲中也详细学习过它的作用了。因为隔的时间比较长了,我怕你忘记了,所以这里我们再回顾下。
简单来说,它就是告诉接收该请求的 Broker:在我传给你的这些分区中,哪些分区的 Leader 副本在你这里;哪些分区的 Follower 副本在你这里。
becomeLeaderOrFollower 方法,就是具体处理 LeaderAndIsrRequest 请求的地方,同时也是副本管理器添加分区的地方。下面我们就完整地学习下这个方法的源码。由于这部分代码很长,我将会分为 3 个部分向你介绍,分别是处理 Controller Epoch 事宜、执行成为 Leader 和 Follower 的逻辑以及构造 Response。
我们先看 becomeLeaderOrFollower 方法的第 1 大部分,处理 Controller Epoch 及其他相关准备工作的流程图:
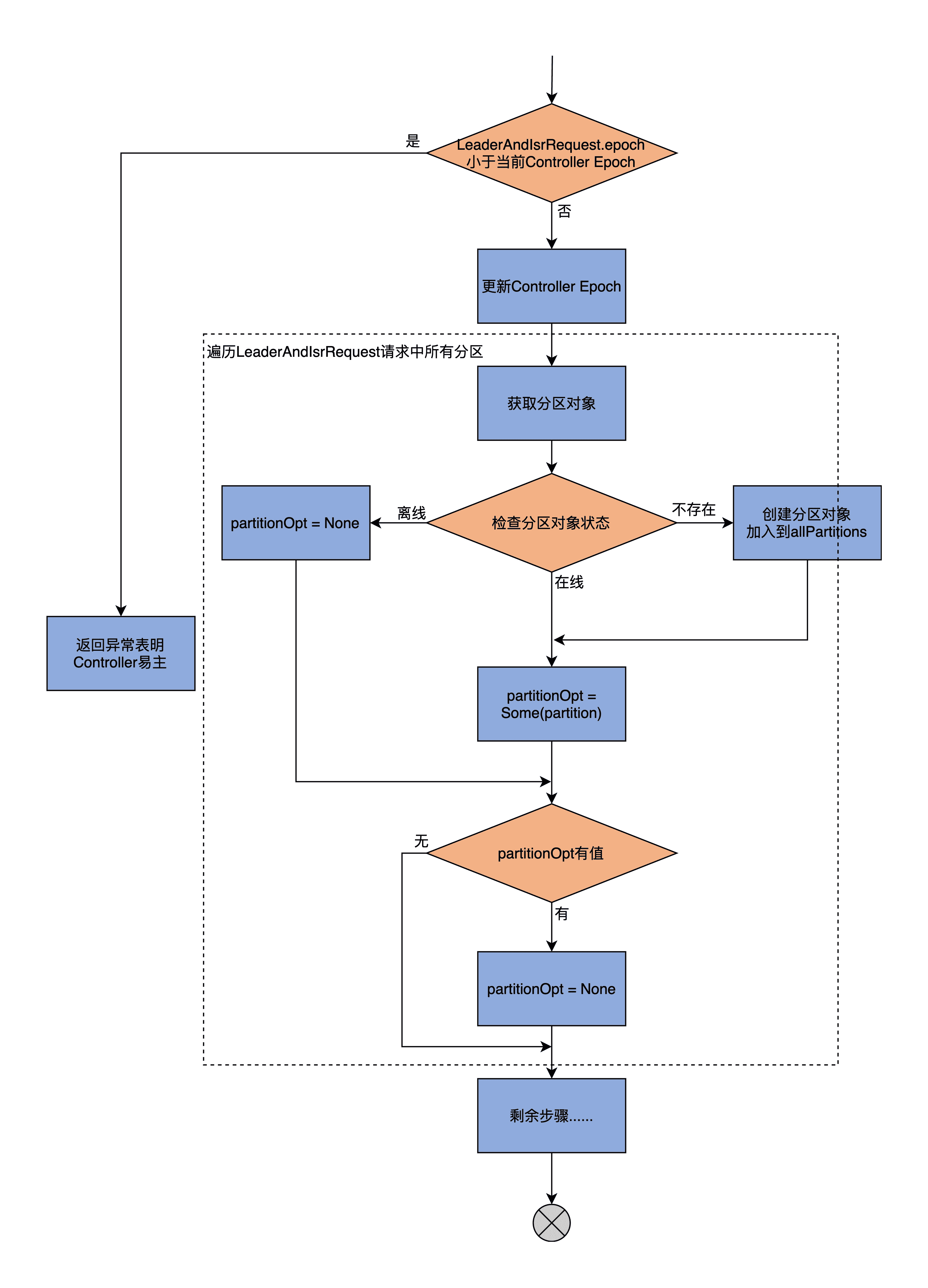
因为 becomeLeaderOrFollower 方法的开头是一段仅用于调试的日志输出,不是很重要,因此,我直接从 if 语句开始讲起。第一部分的主体代码如下:
// 如果 LeaderAndIsrRequest 携带的 Controller Epoch
// 小于当前 Controller 的 Epoch 值
if (leaderAndIsrRequest.controllerEpoch < controllerEpoch) {
stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from controller $controllerId with " +
s"correlation id $correlationId since its controller epoch ${leaderAndIsrRequest.controllerEpoch} is old. " +
s"Latest known controller epoch is $controllerEpoch")
// 说明 Controller 已经易主,抛出相应异常
leaderAndIsrRequest.getErrorResponse(0, Errors.STALE_CONTROLLER_EPOCH.exception)
} else {
val responseMap = new mutable.HashMap[TopicPartition, Errors]
// 更新当前 Controller Epoch 值
controllerEpoch = leaderAndIsrRequest.controllerEpoch
val partitionStates = new mutable.HashMapPartition, LeaderAndIsrPartitionState
// 遍历 LeaderAndIsrRequest 请求中的所有分区
requestPartitionStates.foreach { partitionState =>
val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)
// 从 allPartitions 中获取对应分区对象
val partitionOpt = getPartition(topicPartition) match {
// 如果是 Offline 状态
case HostedPartition.Offline =>
stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from " +
s"controller $controllerId with correlation id $correlationId " +
s"epoch $controllerEpoch for partition $topicPartition as the local replica for the " +
“partition is in an offline log directory”)
// 添加对象异常到 Response,并设置分区对象变量 partitionOpt=None
responseMap.put(topicPartition, Errors.KAFKA_STORAGE_ERROR)
None
// 如果是 Online 状态,直接赋值 partitionOpt 即可
case HostedPartition.Online(partition) =>
Some(partition)
// 如果是 None 状态,则表示没有找到分区对象
// 那么创建新的分区对象将,新创建的分区对象加入到 allPartitions 统一管理
// 然后赋值 partitionOpt 字段
case HostedPartition.None =>
val partition = Partition(topicPartition, time, this)
allPartitions.putIfNotExists(topicPartition, HostedPartition.Online(partition))
Some(partition)
}
// 检查分区的 Leader Epoch 值
……
}
现在,我们一起来学习下这部分内容的核心逻辑。
首先,比较 LeaderAndIsrRequest 携带的 Controller Epoch 值和当前 Controller Epoch 值。如果发现前者小于后者,说明 Controller 已经变更到别的 Broker 上了,需要构造一个 STALE_CONTROLLER_EPOCH 异常并封装进 Response 返回。否则,代码进入 else 分支。
然后,becomeLeaderOrFollower 方法会更新当前缓存的 Controller Epoch 值,再提取出 LeaderAndIsrRequest 请求中涉及到的分区,之后依次遍历这些分区,并执行下面的两步逻辑。
第 1 步,从 allPartitions 中取出对应的分区对象。在第 23 节课,我们学习了分区有 3 种状态,即在线(Online)、离线(Offline)和不存在(None),这里代码就需要分别应对这 3 种情况:
- 如果是 Online 状态的分区,直接将其赋值给 partitionOpt 字段即可;
- 如果是 Offline 状态的分区,说明该分区副本所在的 Kafka 日志路径出现 I/O 故障时(比如磁盘满了),需要构造对应的 KAFKA_STORAGE_ERROR 异常并封装进 Response,同时令 partitionOpt 字段为 None;
- 如果是 None 状态的分区,则创建新分区对象,然后将其加入到 allPartitions 中,进行统一管理,并赋值给 partitionOpt 字段。
第 2 步,检查 partitionOpt 字段表示的分区的 Leader Epoch。检查的原则是要确保请求中携带的 Leader Epoch 值要大于当前缓存的 Leader Epoch,否则就说明是过期 Controller 发送的请求,就直接忽略它,不做处理。
总之呢,becomeLeaderOrFollower 方法的第一部分代码,主要做的事情就是创建新分区、更新 Controller Epoch 和校验分区 Leader Epoch。我们在第 3 讲说到过 Leader Epoch 机制,因为是比较高阶的用法,你可以不用重点掌握,这不会影响到我们学习副本管理。不过,如果你想深入了解的话,推荐你课下自行阅读下 LeaderEpochFileCache.scala 的源码。
当为所有分区都执行完这两个步骤之后,becomeLeaderOrFollower 方法进入到第 2 部分,开始执行 Broker 成为 Leader 副本和 Follower 副本的逻辑:
// 确定 Broker 上副本是哪些分区的 Leader 副本
val partitionsToBeLeader = partitionStates.filter { case (_, partitionState) =>
partitionState.leader == localBrokerId
}
// 确定 Broker 上副本是哪些分区的 Follower 副本
val partitionsToBeFollower = partitionStates.filter { case (k, _) => !partitionsToBeLeader.contains(k) }
val highWatermarkCheckpoints = new LazyOffsetCheckpoints(this.highWatermarkCheckpoints)
val partitionsBecomeLeader = if (partitionsToBeLeader.nonEmpty)
// 调用 makeLeaders 方法为 partitionsToBeLeader 所有分区
// 执行"成为 Leader 副本"的逻辑
makeLeaders(controllerId, controllerEpoch, partitionsToBeLeader, correlationId, responseMap,
highWatermarkCheckpoints)
else
Set.empty[Partition]
val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)
// 调用 makeFollowers 方法为令 partitionsToBeFollower 所有分区
// 执行"成为 Follower 副本"的逻辑
makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap,
highWatermarkCheckpoints)
else
Set.empty[Partition]
val leaderTopicSet = leaderPartitionsIterator.map(.topic).toSet
val followerTopicSet = partitionsBecomeFollower.map(.topic).toSet
// 对于当前 Broker 成为 Follower 副本的主题
// 移除它们之前的 Leader 副本监控指标
followerTopicSet.diff(leaderTopicSet).foreach(brokerTopicStats.removeOldLeaderMetrics)
// 对于当前 Broker 成为 Leader 副本的主题
// 移除它们之前的 Follower 副本监控指
leaderTopicSet.diff(followerTopicSet).foreach(brokerTopicStats.removeOldFollowerMetrics)
// 如果有分区的本地日志为空,说明底层的日志路径不可用
// 标记该分区为 Offline 状态
leaderAndIsrRequest.partitionStates.forEach { partitionState =>
val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)
if (localLog(topicPartition).isEmpty)
markPartitionOffline(topicPartition)
}
首先,这部分代码需要先确定两个分区集合,一个是把该 Broker 当成 Leader 的所有分区;一个是把该 Broker 当成 Follower 的所有分区。判断的依据,主要是看 LeaderAndIsrRequest 请求中分区的 Leader 信息,是不是和本 Broker 的 ID 相同。如果相同,则表明该 Broker 是这个分区的 Leader;否则,表示当前 Broker 是这个分区的 Follower。
一旦确定了这两个分区集合,接着,代码就会分别为它们调用 makeLeaders 和 makeFollowers 方法,正式让 Leader 和 Follower 角色生效。之后,对于那些当前 Broker 成为 Follower 副本的主题,代码需要移除它们之前的 Leader 副本监控指标,以防出现系统资源泄露的问题。同样地,对于那些当前 Broker 成为 Leader 副本的主题,代码要移除它们之前的 Follower 副本监控指标。
最后,如果有分区的本地日志为空,说明底层的日志路径不可用,那么标记该分区为 Offline 状态。所谓的标记为 Offline 状态,主要是两步:第 1 步是更新 allPartitions 中分区的状态;第 2 步是移除对应分区的监控指标。
小结一下,becomeLeaderOrFollower 方法第 2 大部分的主要功能是,调用 makeLeaders 和 makeFollowers 方法,令 Broker 在不同分区上的 Leader 或 Follower 角色生效。关于这两个方法的实现细节,一会儿我再详细说。
现在,让我们看看第 3 大部分的代码,构造 Response 对象。这部分代码是 becomeLeaderOrFollower 方法的收尾操作。
// 启动高水位检查点专属线程
// 定期将 Broker 上所有非 Offline 分区的高水位值写入到检查点文件
startHighWatermarkCheckPointThread()
// 添加日志路径数据迁移线程
maybeAddLogDirFetchers(partitionStates.keySet, highWatermarkCheckpoints)
// 关闭空闲副本拉取线程
replicaFetcherManager.shutdownIdleFetcherThreads()
// 关闭空闲日志路径数据迁移线程
replicaAlterLogDirsManager.shutdownIdleFetcherThreads()
// 执行 Leader 变更之后的回调逻辑
onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower)
// 构造 LeaderAndIsrRequest 请求的 Response 并返回
val responsePartitions = responseMap.iterator.map { case (tp, error) =>
new LeaderAndIsrPartitionError()
.setTopicName(tp.topic)
.setPartitionIndex(tp.partition)
.setErrorCode(error.code)
}.toBuffer
new LeaderAndIsrResponse(new LeaderAndIsrResponseData()
.setErrorCode(Errors.NONE.code)
.setPartitionErrors(responsePartitions.asJava))
我们来分析下这部分代码的执行逻辑吧。
首先,这部分开始时会启动一个专属线程来执行高水位值持久化,定期地将 Broker 上所有非 Offline 分区的高水位值写入检查点文件。这个线程是个后台线程,默认每 5 秒执行一次。
同时,代码还会添加日志路径数据迁移线程。这个线程的主要作用是,将路径 A 上面的数据搬移到路径 B 上。这个功能是 Kafka 支持 JBOD(Just a Bunch of Disks)的重要前提。
之后,becomeLeaderOrFollower 方法会关闭空闲副本拉取线程和空闲日志路径数据迁移线程。判断空闲与否的主要条件是,分区 Leader/Follower 角色调整之后,是否存在不再使用的拉取线程了。代码要确保及时关闭那些不再被使用的线程对象。
再之后是执行 LeaderAndIsrRequest 请求的回调处理逻辑。这里的回调逻辑,实际上只是对 Kafka 两个内部主题(__consumer_offsets 和 __transaction_state)有用,其他主题一概不适用。所以通常情况下,你可以无视这里的回调逻辑。
等这些都做完之后,代码开始执行这部分最后,也是最重要的任务:构造 LeaderAndIsrRequest 请求的 Response,然后将新创建的 Response 返回。至此,这部分方法的逻辑结束。
纵观 becomeLeaderOrFollower 方法的这 3 大部分,becomeLeaderOrFollower 方法最重要的职责,在我看来就是调用 makeLeaders 和 makeFollowers 方法,为各自的分区列表执行相应的角色确认工作。
接下来,我们就分别看看这两个方法是如何实现这种角色确认的。
makeLeaders 方法
makeLeaders 方法的作用是,让当前 Broker 成为给定一组分区的 Leader,也就是让当前 Broker 下该分区的副本成为 Leader 副本。这个方法主要有 3 步:
- 停掉这些分区对应的获取线程;
- 更新 Broker 缓存中的分区元数据信息;
- 将指定分区添加到 Leader 分区集合。
我们结合代码分析下这些都是如何实现的。首先,我们看下 makeLeaders 的方法签名:
// controllerId:Controller 所在 Broker 的 ID
// controllEpoch:Controller Epoch 值,可以认为是 Controller 版本号
// partitionStates:LeaderAndIsrRequest 请求中携带的分区信息
// correlationId:请求的 Correlation 字段,只用于日志调试
// responseMap:按照主题分区分组的异常错误集合
// highWatermarkCheckpoints:操作磁盘上高水位检查点文件的工具类
private def makeLeaders(controllerId: Int,
controllerEpoch: Int,
partitionStates: Map[Partition, LeaderAndIsrPartitionState],
correlationId: Int,
responseMap: mutable.Map[TopicPartition, Errors],
highWatermarkCheckpoints: OffsetCheckpoints): Set[Partition] = {
……
}
可以看出,makeLeaders 方法接收 6 个参数,并返回一个分区对象集合。这个集合就是当前 Broker 是 Leader 的所有分区。在这 6 个参数中,以下 3 个参数比较关键,我们看下它们的含义。
- controllerId:Controller 所在 Broker 的 ID。该字段只是用于日志输出,无其他实际用途。
- controllerEpoch:Controller Epoch 值,可以认为是 Controller 版本号。该字段用于日志输出使用,无其他实际用途。
- partitionStates:LeaderAndIsrRequest 请求中携带的分区信息,包括每个分区的 Leader 是谁、ISR 都有哪些等数据。
好了,现在我们继续学习 makeLeaders 的代码。我把这个方法的关键步骤放在了注释里,并省去了一些日志输出相关的代码。
……
// 使用 Errors.NONE 初始化 ResponseMap
partitionStates.keys.foreach { partition =>
……
responseMap.put(partition.topicPartition, Errors.NONE)
}
val partitionsToMakeLeaders = mutable.SetPartition
try {
// 停止消息拉取
replicaFetcherManager.removeFetcherForPartitions(
partitionStates.keySet.map(_.topicPartition))
stateChangeLogger.info(s"Stopped fetchers as part of LeaderAndIsr request correlationId $correlationId from " +
s"controller $controllerId epoch $controllerEpoch as part of the become-leader transition for " +
s"${partitionStates.size} partitions")
// 更新指定分区的 Leader 分区信息
partitionStates.foreach { case (partition, partitionState) =>
try {
if (partition.makeLeader(partitionState, highWatermarkCheckpoints))
partitionsToMakeLeaders += partition
else
……
} catch {
case e: KafkaStorageException =>
……
// 把 KAFKA_SOTRAGE_ERRROR 异常封装到 Response 中
responseMap.put(partition.topicPartition, Errors.KAFKA_STORAGE_ERROR)
}
}
} catch {
case e: Throwable =>
……
}
……
partitionsToMakeLeaders
我把主要的执行流程,梳理为了一张流程图:
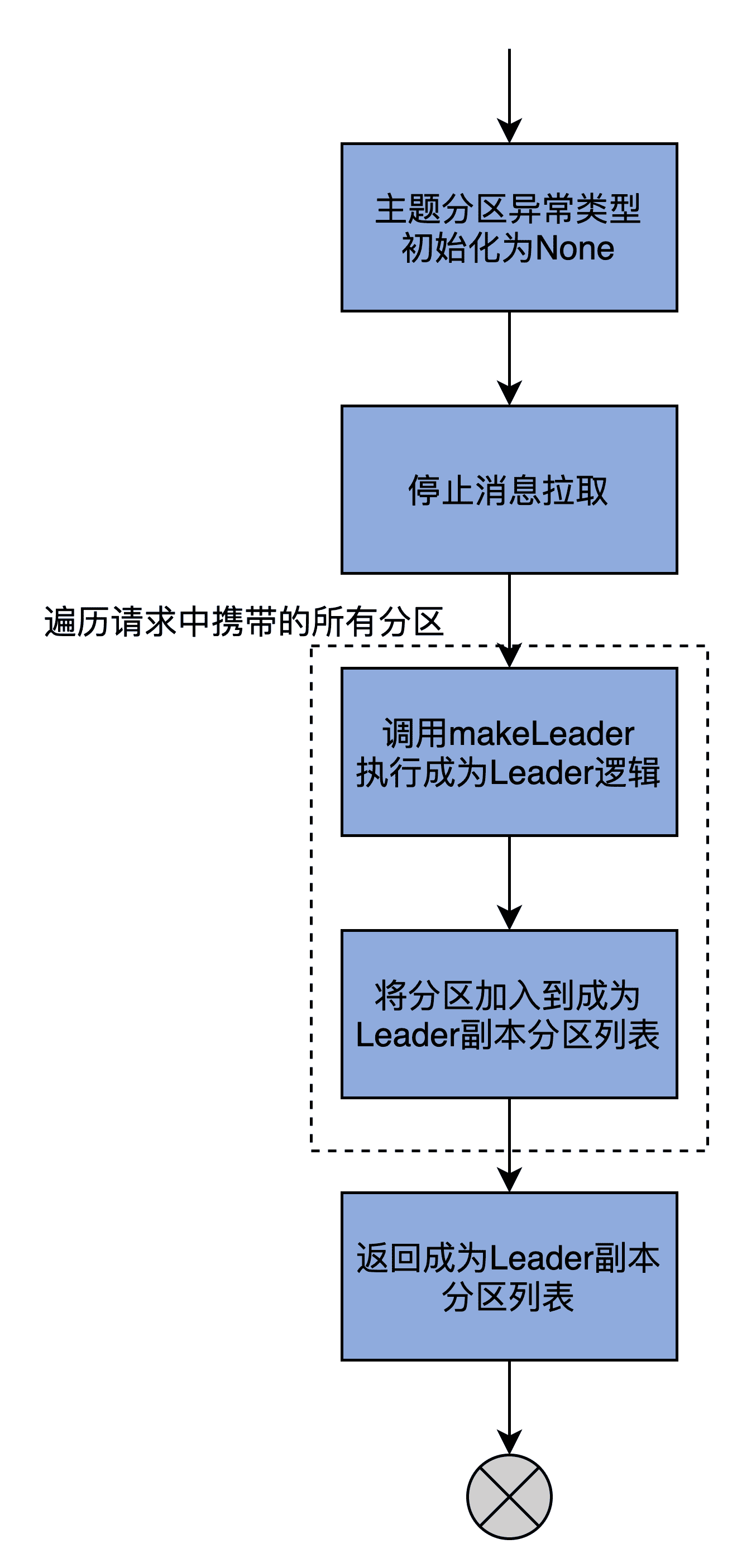
结合着图,我再带着你学习下这个方法的执行逻辑。
首先,将给定的一组分区的状态全部初始化成 Errors.None。
然后,停止为这些分区服务的所有拉取线程。毕竟该 Broker 现在是这些分区的 Leader 副本了,不再是 Follower 副本了,所以没有必要再使用拉取线程了。
最后,makeLeaders 方法调用 Partition 的 makeLeader 方法,去更新给定一组分区的 Leader 分区信息,而这些是由 Partition 类中的 makeLeader 方法完成的。该方法保存分区的 Leader 和 ISR 信息,同时创建必要的日志对象、重设远端 Follower 副本的 LEO 值。
那远端 Follower 副本,是什么意思呢?远端 Follower 副本,是指保存在 Leader 副本本地内存中的一组 Follower 副本集合,在代码中用字段 remoteReplicas 来表征。
ReplicaManager 在处理 FETCH 请求时,会更新 remoteReplicas 中副本对象的 LEO 值。同时,Leader 副本会将自己更新后的 LEO 值与 remoteReplicas 中副本的 LEO 值进行比较,来决定是否“抬高”高水位值。
而 Partition 类中的 makeLeader 方法的一个重要步骤,就是要重设这组远端 Follower 副本对象的 LEO 值。
makeLeaders 方法执行完 Partition.makeLeader 后,如果当前 Broker 成功地成为了该分区的 Leader 副本,就返回 True,表示新 Leader 配置成功,否则,就表示处理失败。倘若成功设置了 Leader,那么,就把该分区加入到已成功设置 Leader 的分区列表中,并返回该列表。
至此,方法结束。我再来小结下,makeLeaders 的作用是令当前 Broker 成为给定分区的 Leader 副本。接下来,我们再看看与 makeLeaders 方法功能相反的 makeFollowers 方法。
makeFollowers 方法
makeFollowers 方法的作用是,将当前 Broker 配置成指定分区的 Follower 副本。我们还是先看下方法签名:
// controllerId:Controller 所在 Broker 的 Id
// controllerEpoch:Controller Epoch 值
// partitionStates:当前 Broker 是 Follower 副本的所有分区的详细信息
// correlationId:连接请求与响应的关联字段
// responseMap:封装 LeaderAndIsrRequest 请求处理结果的字段
// highWatermarkCheckpoints:操作高水位检查点文件的工具类
private def makeFollowers(
controllerId: Int,
controllerEpoch: Int,
partitionStates: Map[Partition, LeaderAndIsrPartitionState],
correlationId: Int,
responseMap: mutable.Map[TopicPartition, Errors],
highWatermarkCheckpoints: OffsetCheckpoints) : Set[Partition] = {
……
}
你看,makeFollowers 方法的参数列表与 makeLeaders 方法,是一模一样的。这里我也就不再展开了。
其中比较重要的字段,就是 partitionStates 和 responseMap。基本上,你可以认为 partitionStates 是 makeFollowers 方法的输入,responseMap 是输出。
因为整个 makeFollowers 方法的代码很长,所以我接下来会先用一张图解释下它的核心逻辑,让你先有个全局观;然后,我再按照功能划分带你学习每一部分的代码。

总体来看,makeFollowers 方法分为两大步:
- 第 1 步,遍历 partitionStates 中的所有分区,然后执行“成为 Follower”的操作;
- 第 2 步,执行其他动作,主要包括重建 Fetcher 线程、完成延时请求等。
首先,我们学习第 1 步遍历 partitionStates 所有分区的代码:
// 第一部分:遍历 partitionStates 所有分区
……
partitionStates.foreach { case (partition, partitionState) =>
……
// 将所有分区的处理结果的状态初始化为 Errors.NONE
responseMap.put(partition.topicPartition, Errors.NONE)
}
val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()
try {
// 遍历 partitionStates 所有分区
partitionStates.foreach { case (partition, partitionState) =>
// 拿到分区的 Leader Broker ID
val newLeaderBrokerId = partitionState.leader
try {
// 在元数据缓存中找到 Leader Broke 对象
metadataCache.getAliveBrokers.find(.id == newLeaderBrokerId) match {
// 如果 Leader 确实存在
case Some() =>
// 执行 makeFollower 方法,将当前 Broker 配置成该分区的 Follower 副本
if (partition.makeFollower(partitionState, highWatermarkCheckpoints))
// 如果配置成功,将该分区加入到结果返回集中
partitionsToMakeFollower += partition
else // 如果失败,打印错误日志
……
// 如果 Leader 不存在
case None =>
……
// 依然创建出分区 Follower 副本的日志对象
partition.createLogIfNotExists(isNew = partitionState.isNew, isFutureReplica = false,
highWatermarkCheckpoints)
}
} catch {
case e: KafkaStorageException =>
……
}
}
在这部分代码中,我们可以把它的执行逻辑划分为两大步骤。
第 1 步,将结果返回集合中所有分区的处理结果状态初始化为 Errors.NONE;第 2 步,遍历 partitionStates 中的所有分区,依次为每个分区执行以下逻辑:
- 从分区的详细信息中获取分区的 Leader Broker ID;
- 拿着上一步获取的 Broker ID,去 Broker 元数据缓存中找到 Leader Broker 对象;
- 如果 Leader 对象存在,则执行 Partition 类的 makeFollower 方法将当前 Broker 配置成该分区的 Follower 副本。如果 makeFollower 方法执行成功,就说明当前 Broker 被成功配置为指定分区的 Follower 副本,那么将该分区加入到结果返回集中。
- 如果 Leader 对象不存在,依然创建出分区 Follower 副本的日志对象。
说到 Partition 的 makeFollower 方法的执行逻辑,主要是包括以下 4 步:
- 更新 Controller Epoch 值;
- 保存副本列表(Assigned Replicas,AR)和清空 ISR;
- 创建日志对象;
- 重设 Leader 副本的 Broker ID。
接下来,我们看下 makeFollowers 方法的第 2 步,执行其他动作的代码:
// 第二部分:执行其他动作
// 移除现有 Fetcher 线程
replicaFetcherManager.removeFetcherForPartitions(
partitionsToMakeFollower.map(.topicPartition))
……
// 尝试完成延迟请求
partitionsToMakeFollower.foreach { partition =>
completeDelayedFetchOrProduceRequests(partition.topicPartition)
}
if (isShuttingDown.get()) {
…..
} else {
// 为需要将当前 Broker 设置为 Follower 副本的分区
// 确定 Leader Broker 和起始读取位移值 fetchOffset
val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map { partition =>
val leader = metadataCache.getAliveBrokers
.find(.id == partition.leaderReplicaIdOpt.get).get
.brokerEndPoint(config.interBrokerListenerName)
val fetchOffset = partition.localLogOrException.highWatermark
partition.topicPartition -> InitialFetchState(leader,
partition.getLeaderEpoch, fetchOffset)
}.toMap
// 使用上一步确定的 Leader Broker 和 fetchOffset 添加新的 Fetcher 线程
replicaFetcherManager.addFetcherForPartitions(
partitionsToMakeFollowerWithLeaderAndOffset)
}
} catch {
case e: Throwable =>
……
throw e
}
……
// 返回需要将当前 Broker 设置为 Follower 副本的分区列表
partitionsToMakeFollower
你看,这部分代码的任务比较简单,逻辑也都是线性递进的,很好理解。我带你简单地梳理一下。
首先,移除现有 Fetcher 线程。因为 Leader 可能已经更换了,所以要读取的 Broker 以及要读取的位移值都可能随之发生变化。
然后,为需要将当前 Broker 设置为 Follower 副本的分区,确定 Leader Broker 和起始读取位移值 fetchOffset。这些信息都已经在 LeaderAndIsrRequest 中了。
接下来,使用上一步确定的 Leader Broker 和 fetchOffset 添加新的 Fetcher 线程。
最后,返回需要将当前 Broker 设置为 Follower 副本的分区列表。
至此,副本管理器管理分区和副本的主要方法实现,我们就都学完啦。可以看出,这些代码实现的大部分,都是围绕着如何处理 LeaderAndIsrRequest 请求数据展开的。比如,makeLeaders 拿到请求数据后,会为分区设置 Leader 和 ISR;makeFollowers 拿到数据后,会为分区更换 Fetcher 线程以及清空 ISR。
LeaderAndIsrRequest 请求是 Kafka 定义的最重要的控制类请求。搞懂它是如何被处理的,对于你弄明白 Kafka 的副本机制是大有裨益的。
ISR 管理
除了读写副本、管理分区和副本的功能之外,副本管理器还有一个重要的功能,那就是管理 ISR。这里的管理主要体现在两个方法:
- 一个是 maybeShrinkIsr 方法,作用是阶段性地查看 ISR 中的副本集合是否需要收缩;
- 另一个是 maybePropagateIsrChanges 方法,作用是定期向集群 Broker 传播 ISR 的变更。
首先,我们看下 ISR 的收缩操作。
maybeShrinkIsr 方法
收缩是指,把 ISR 副本集合中那些与 Leader 差距过大的副本移除的过程。所谓的差距过大,就是 ISR 中 Follower 副本滞后 Leader 副本的时间,超过了 Broker 端参数 replica.lag.time.max.ms 值的 1.5 倍。
稍等,为什么是 1.5 倍呢?你可以看下面的代码:
def startup(): Unit = {
scheduler.schedule(“isr-expiration”, maybeShrinkIsr _, period = config.replicaLagTimeMaxMs / 2, unit = TimeUnit.MILLISECONDS)
……
}
我来解释下。ReplicaManager 类的 startup 方法会在被调用时创建一个异步线程,定时查看是否有 ISR 需要进行收缩。这里的定时频率是 replicaLagTimeMaxMs 值的一半,而判断 Follower 副本是否需要被移除 ISR 的条件是,滞后程度是否超过了 replicaLagTimeMaxMs 值。
因此理论上,滞后程度小于 1.5 倍 replicaLagTimeMaxMs 值的 Follower 副本,依然有可能在 ISR 中,不会被移除。这就是数字“1.5”的由来了。
接下来,我们看下 maybeShrinkIsr 方法的源码。
private def maybeShrinkIsr(): Unit = {
trace(“Evaluating ISR list of partitions to see which replicas can be removed from the ISR”)
allPartitions.keys.foreach { topicPartition =>
nonOfflinePartition(topicPartition).foreach(_.maybeShrinkIsr())
}
}
可以看出,maybeShrinkIsr 方法会遍历该副本管理器上所有分区对象,依次为这些分区中状态为 Online 的分区,执行 Partition 类的 maybeShrinkIsr 方法。这个方法的源码如下:
def maybeShrinkIsr(): Unit = {
// 判断是否需要执行 ISR 收缩
val needsIsrUpdate = inReadLock(leaderIsrUpdateLock) {
needsShrinkIsr()
}
val leaderHWIncremented = needsIsrUpdate && inWriteLock(leaderIsrUpdateLock) {
leaderLogIfLocal match {
// 如果是 Leader 副本
case Some(leaderLog) =>
// 获取不同步的副本 Id 列表
val outOfSyncReplicaIds = getOutOfSyncReplicas(replicaLagTimeMaxMs)
// 如果存在不同步的副本 Id 列表
if (outOfSyncReplicaIds.nonEmpty) {
// 计算收缩之后的 ISR 列表
val newInSyncReplicaIds = inSyncReplicaIds – outOfSyncReplicaIds
assert(newInSyncReplicaIds.nonEmpty)
info(“Shrinking ISR from %s to %s. Leader: (highWatermark: %d, endOffset: %d). Out of sync replicas: %s.”
.format(inSyncReplicaIds.mkString(","),
newInSyncReplicaIds.mkString(","),
leaderLog.highWatermark,
leaderLog.logEndOffset,
outOfSyncReplicaIds.map { replicaId =>
s"(brokerId: $replicaId, endOffset: ${getReplicaOrException(replicaId).logEndOffset})"
}.mkString(" “)
)
)
// 更新 ZooKeeper 中分区的 ISR 数据以及 Broker 的元数据缓存中的数据
shrinkIsr(newInSyncReplicaIds)
// 尝试更新 Leader 副本的高水位值
maybeIncrementLeaderHW(leaderLog)
} else {
false
}
// 如果不是 Leader 副本,什么都不做
case None => false
}
}
// 如果 Leader 副本的高水位值抬升了
if (leaderHWIncremented)
// 尝试解锁一下延迟请求
tryCompleteDelayedRequests()
}
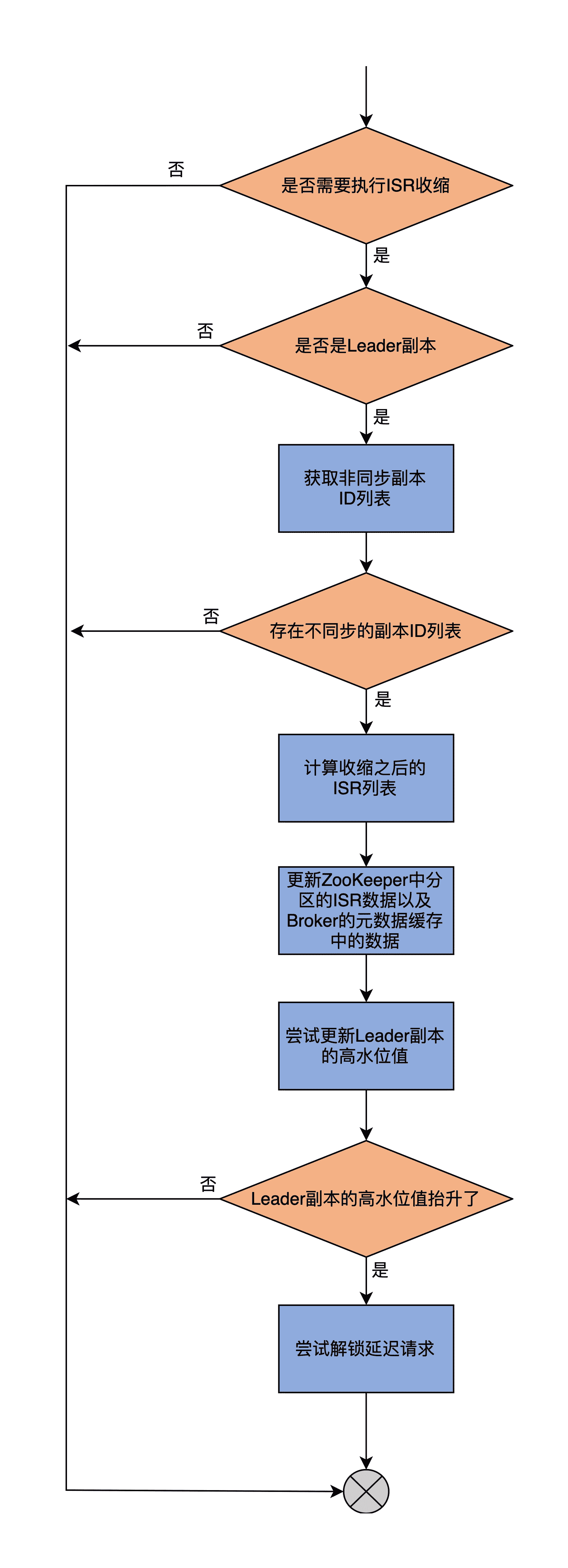
可以看出,maybeShrinkIsr 方法的整个执行流程是:
- 第 1 步,判断是否需要执行 ISR 收缩。主要的方法是,调用 needShrinkIsr 方法来获取与 Leader 不同步的副本。如果存在这样的副本,说明需要执行 ISR 收缩。
- 第 2 步,再次获取与 Leader 不同步的副本列表,并把它们从当前 ISR 中剔除出去,然后计算得出最新的 ISR 列表。
- 第 3 步,调用 shrinkIsr 方法去更新 ZooKeeper 上分区的 ISR 数据以及 Broker 上元数据缓存。
- 第 4 步,尝试更新 Leader 分区的高水位值。这里有必要检查一下是否可以抬升高水位值的原因在于,如果 ISR 收缩后只剩下 Leader 副本一个了,那么高水位值的更新就不再受那么多限制了。
- 第 5 步,根据上一步的结果,来尝试解锁之前不满足条件的延迟操作。
我把这个执行过程,梳理到了一张流程图中:
maybePropagateIsrChanges 方法
ISR 收缩之后,ReplicaManager 还需要将这个操作的结果传递给集群的其他 Broker,以同步这个操作的结果。这是由 ISR 通知事件来完成的。
在 ReplicaManager 类中,方法 maybePropagateIsrChanges 专门负责创建 ISR 通知事件。这也是由一个异步线程定期完成的,代码如下:
scheduler.schedule(“isr-change-propagation”, maybePropagateIsrChanges _, period = 2500L, unit = TimeUnit.MILLISECONDS)
接下来,我们看下 maybePropagateIsrChanges 方法的代码:
def maybePropagateIsrChanges(): Unit = {
val now = System.currentTimeMillis()
isrChangeSet synchronized {
// ISR 变更传播的条件,需要同时满足:
// 1. 存在尚未被传播的 ISR 变更
// 2. 最近 5 秒没有任何 ISR 变更,或者自上次 ISR 变更已经有超过 1 分钟的时间
if (isrChangeSet.nonEmpty &&
(lastIsrChangeMs.get() + ReplicaManager.IsrChangePropagationBlackOut < now ||
lastIsrPropagationMs.get() + ReplicaManager.IsrChangePropagationInterval < now)) {
// 创建 ZooKeeper 相应的 Znode 节点
zkClient.propagateIsrChanges(isrChangeSet)
// 清空 isrChangeSet 集合
isrChangeSet.clear()
// 更新最近 ISR 变更时间戳
lastIsrPropagationMs.set(now)
}
}
}
可以看到,maybePropagateIsrChanges 方法的逻辑也比较简单。我来概括下其执行逻辑。
首先,确定 ISR 变更传播的条件。这里需要同时满足两点:
- 一是,存在尚未被传播的 ISR 变更;
- 二是,最近 5 秒没有任何 ISR 变更,或者自上次 ISR 变更已经有超过 1 分钟的时间。
一旦满足了这两个条件,代码会创建 ZooKeeper 相应的 Znode 节点;然后,清空 isrChangeSet 集合;最后,更新最近 ISR 变更时间戳。
总结
今天,我们重点学习了 ReplicaManager 类的分区和副本管理功能,以及 ISR 管理。我们再完整地梳理下 ReplicaManager 类的核心功能和方法。
- 分区 / 副本管理。ReplicaManager 类的核心功能是,应对 Broker 端接收的 LeaderAndIsrRequest 请求,并将请求中的分区信息抽取出来,让所在 Broker 执行相应的动作。
- becomeLeaderOrFollower 方法。它是应对 LeaderAndIsrRequest 请求的入口方法。它会将请求中的分区划分成两组,分别调用 makeLeaders 和 makeFollowers 方法。
- makeLeaders 方法。它的作用是让 Broker 成为指定分区 Leader 副本。
- makeFollowers 方法。它的作用是让 Broker 成为指定分区 Follower 副本的方法。
- ISR 管理。ReplicaManager 类提供了 ISR 收缩和定期传播 ISR 变更通知的功能。
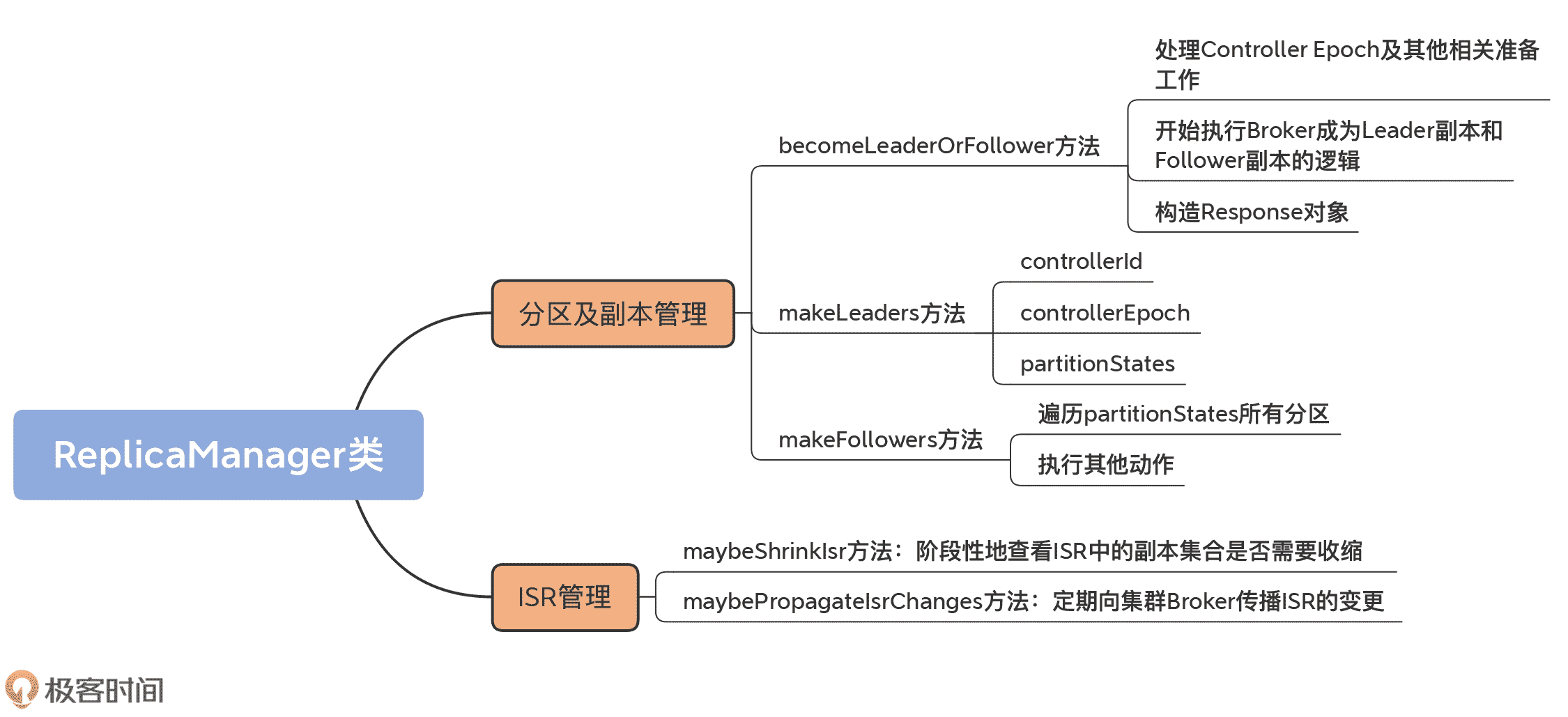
掌握了这些核心知识点,你差不多也就掌握了绝大部分的副本管理器功能,比如说 Broker 如何成为分区的 Leader 副本和 Follower 副本,以及 ISR 是如何被管理的。
你可能也发现了,有些非核心小功能我们今天并没有展开,比如 Broker 上的元数据缓存是怎么回事。下一节课,我将带你深入到这个缓存当中,去看看它到底是什么。
课后讨论
maybePropagateIsrChanges 源码中,有个 isrChangeSet 字段。你知道它是在哪里被更新的吗?
欢迎在留言区写下你的思考和答案,跟我交流讨论,也欢迎你把今天的内容分享给你的朋友。
文章作者 anonymous
上次更新 2024-05-03