特别发送(一)|经典面试题讲解第一弹
文章目录
你好,我是朱晓峰。
到这里,“实践篇”的内容咱们就学完了。今天,我们来学点儿不一样的——5 道经典面试题。这些都是在实际面试中的原题,当然,我没有完全照搬,而是结合咱们课程的具体情况,有针对性地进行了调整。我不仅会给你提供答案,还会和你一起分析,让你能够灵活地吃透这些题目,并能举一反三。
话不多说,我们现在开始。我先带你从一道简单的关于“索引”的面试题入手,索引在面试题里经常出现,来看看这一道你能不能做对。
第一题
下面关于索引的描述,正确的是:
- 建立索引的主要目的是减少冗余数据,使数据表占用更少的空间,并且提高查询的速度
- 一个表上可以建立一个或者多个索引
- 组合索引可以有效提高查询的速度,比单字段索引更高效,所以,我们应该创建一个由所有的字段组成的组合索引,这样就可以解决所有问题了
- 因为索引可以提高查询效率,所以索引建得越多越好
解析:这道题的正确答案是选项 2,我们来分析一下其他选项。
- 选项 1 说对了一半,索引可以提高查询效率,但是创建索引不能减少冗余数据,而且索引还要占用额外的存储空间,所以选项 1 不对。
- 选项 3 不对的原因有 2 个。第一,组合索引不一定比单字段索引高效,因为组合索引的字段是有序的,遵循左对齐的原则。如果查询的筛选条件不包含组合索引中最左边的字段,那么组合索引就完全不能用。第二,创建索引也是有成本的,需要占用额外的存储空间。用所有的字段创建组合索引的存储成本比较高,而且利用率比较低,完全用上的可能性几乎不存在,所以很少有人会这样做。而且一旦更改任何一个字段的数据,就必须要改索引,这样操作成本也比较高。
- 选项 4 错误,因为索引有成本,很少作为筛选条件的字段,没有必要创建索引。
如果这道题你回答错了,一定要回去复习下第 11 讲的内容。
第二题
假设我们有这样一份学生成绩单,所有同学的成绩都各不相同,请编写一个简单的 SQL 语句,查询分数排在第三名的同学的成绩:
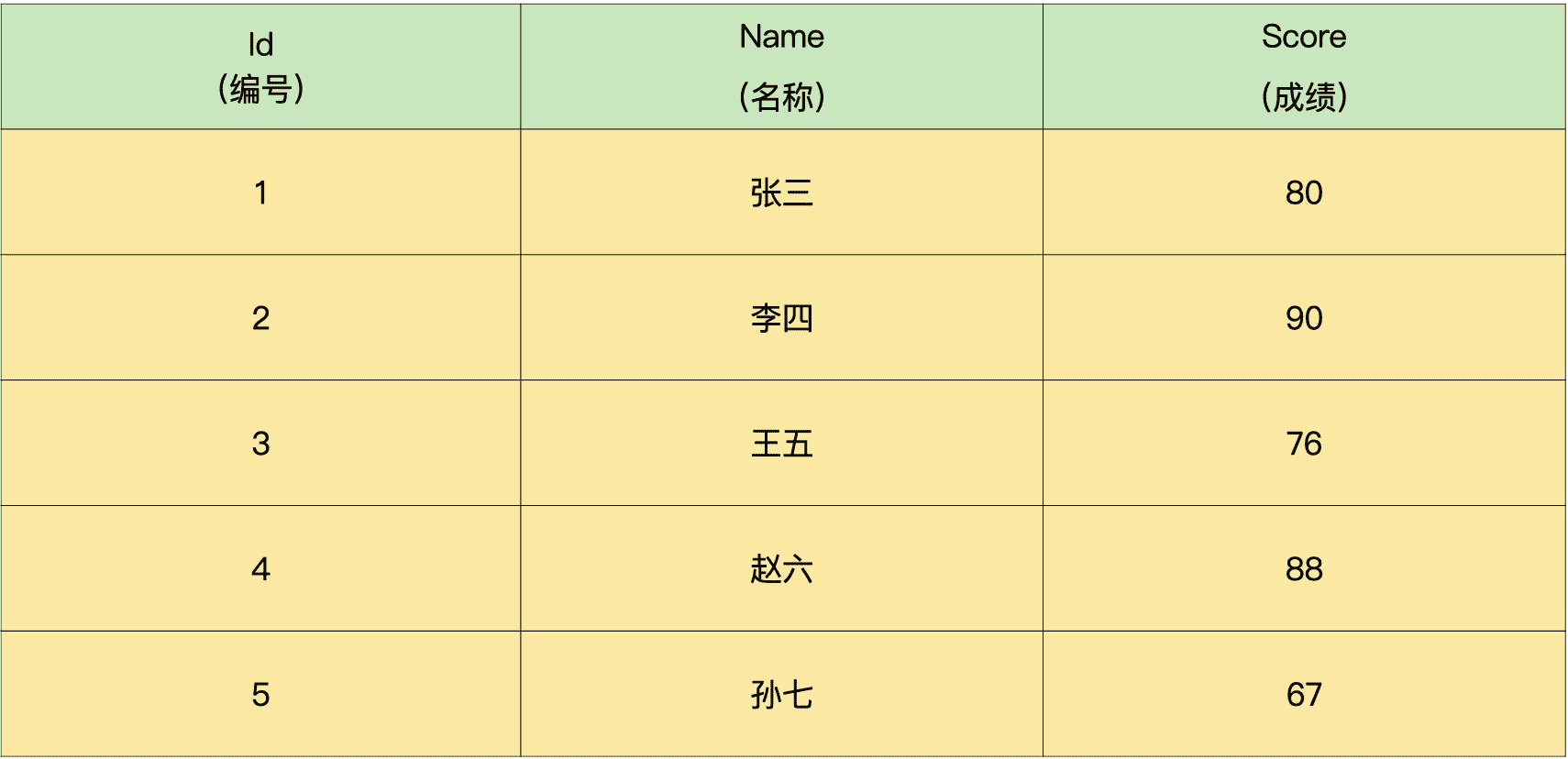
解析:这道题考查的是我们对查询语句的掌握情况。针对题目中的场景,可以分两步来进行查询。
第一步,按照成绩高低进行排序:
mysql> SELECT *
-> FROM demo.test1
-> ORDER BY score DESC; – DESC 表示降序排列
+—-+——+——-+
| id | name | score |
+—-+——+——-+
| 2 | 李四 | 90.00 |
| 4 | 赵六 | 88.00 |
| 1 | 张三 | 80.00 |
| 3 | 王五 | 76.00 |
| 5 | 孙七 | 67.00 |
+—-+——+——-+
5 rows in set (0.00 sec)
第二步,找出排名第三的同学和对应的成绩。我们可以用第 4 讲里学过的对返回记录进行限定的关键字 LIMIT:
mysql> SELECT *
-> FROM demo.test1
-> ORDER BY score DESC
-> LIMIT 2,1;
+—-+——+——-+
| id | name | score |
+—-+——+——-+
| 1 | 张三 | 80.00 |
+—-+——+——-+
1 row in set (0.00 sec)
在 MySQL 中,LIMIT 后面可以跟 2 个参数,第一个参数表示记录的起始位置(第一个记录的位置是 0),第二个参数表示返回几条记录。因此,“LIMIT 2,1”就表示从第 3 条记录开始,返回 1 条记录。这样,就可以查出排名第三的同学的成绩了。
第三题
现在我们有两个表,分别是人员表(demo.person)和地址表(demo.address),要求你使用关联查询查出完整信息。无论有没有地址信息,人员的信息必须全部包含在结果集中。
人员表:
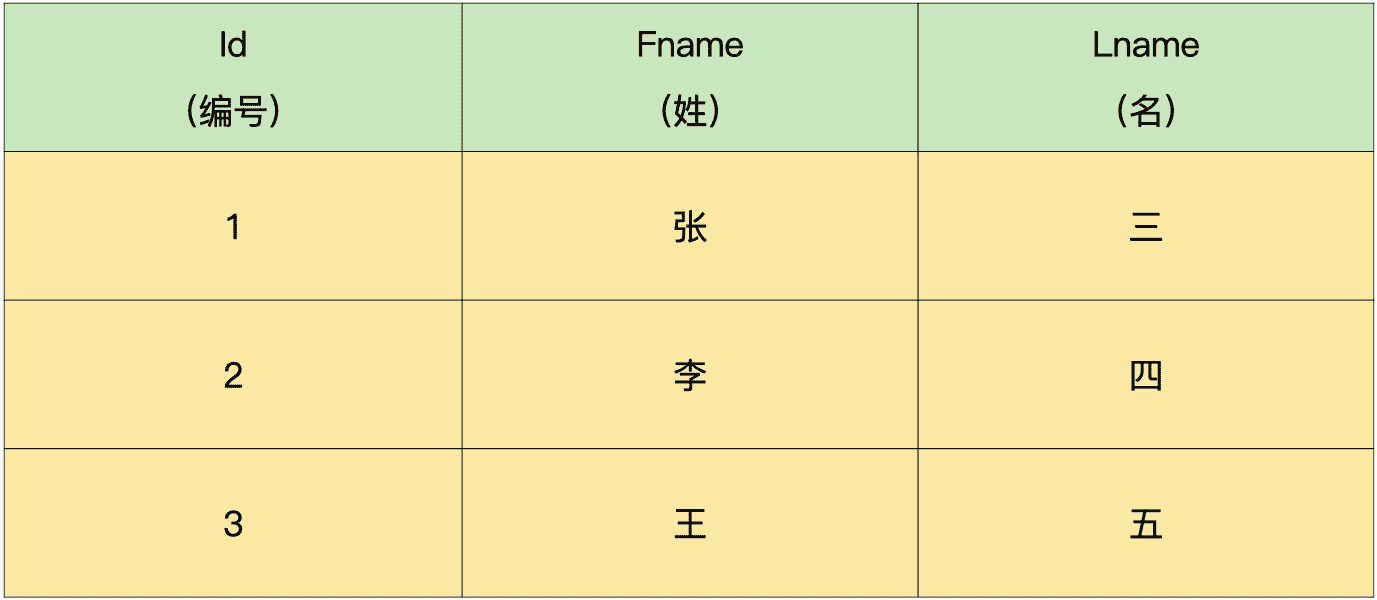
地址表:

解析:这个是典型的外查询,咱们在第 6 讲里学过。题目要求我们查出人员表中的全部信息,而地址表中信息则可以为空,就可以用下面的查询代码:
mysql> SELECT *
-> FROM demo.person AS a
-> LEFT JOIN demo.address AS b – 左连接,确保 demo.person 中的记录全部包括在结果集中
-> ON (a.id=b.id);
+—-+——-+——-+——+———+——+———–+
| id | fname | lname | id | country | city | address |
+—-+——-+——-+——+———+——+———–+
| 1 | 张 | 三 | 1 | 中国 | 北京 | 海淀 123 |
| 2 | 李 | 四 | 2 | 美国 | 纽约 | 奥巴尼 333 |
| 3 | 王 | 五 | NULL | NULL | NULL | NULL |
+—-+——-+——-+——+———+——+———–+
3 rows in set (0.02 sec)
第四题
假设有这样一个教学表(demo.teach),里面包含了人员编号(id)、姓名(fname)和对应的老师的人员编号(teacherid)。如果一个人是学生,那么他一定有对应的老师编号,通过这个编号,就可以找到老师的信息;如果一个人是老师,那么他对应的老师编号就是空。比如说,下表中李四的老师编号是 101,我们就可以通过搜索人员编号,找到 101 的名称是张三,那么李四的老师就是张三;而张三自己就是老师,所以他对应的老师编号是空。

要求:请写一个 SQL 语句,查询出至少有 2 名学生的老师姓名。
说明一下,在刚刚的数据表中,张三有 3 名学生,分别是李四、王五和周八。赵六有一名学生,是孙七。因此,正确的 SQL 语句的查询结果应该是:

解析:
针对这道题,我们可以按照这样的思路去做:
- 通过统计学生对应的老师编号,就可以获取至少有 2 个学生的老师的编号。
- 通过关联查询和自连接获取需要的信息。所谓的自连接,就是数据表与自身进行连接。你可以认为是把数据表复制成一模一样的 2 个表,通过给数据表起不同的名字来区分它们,这样方便对表进行操作,然后就可以对这 2 个表进行连接操作了。
- 通过使用条件语句 WHERE 和 HAVING 对数据进行筛选:先用 WHERE 筛选出所有的老师编号,再用 HAVING 筛选出有 2 个以上学生的老师编号。
首先,我们来获取老师编号,如下:
mysql> SELECT teacherid
-> FROM demo.teach
-> WHERE teacherid is not NULL – 用 WHERE 筛选出所有的老师编号
-> GROUP BY teacherid
-> HAVING COUNT(*)>=2; – 用 HAVING 筛选出有 2 个以上学生的老师编号
+———–+
| teacherid |
+———–+
| 101 |
+———–+
1 row in set (0.00 sec)
接着,通过自连接,来获取老师的姓名:
mysql> SELECT a.id,a.fname
-> FROM demo.teach AS a
-> JOIN
-> (
-> SELECT teacherid
-> FROM demo.teach
-> WHERE teacherid IS NOT NULL
-> GROUP BY teacherid
-> HAVING COUNT(*)>=2
-> ) AS b
-> ON (a.id = b.teacherid);
+—–+——-+
| id | fname |
+—–+——-+
| 101 | 张三 |
+—–+——-+
1 row in set (0.00 sec)
第五题
假设某中学高三年级有多位同学,分成多个班,我们有统一记录学生成绩的表(demo.student) 和班级信息表(demo.class),具体信息如下所示:
学生成绩表:
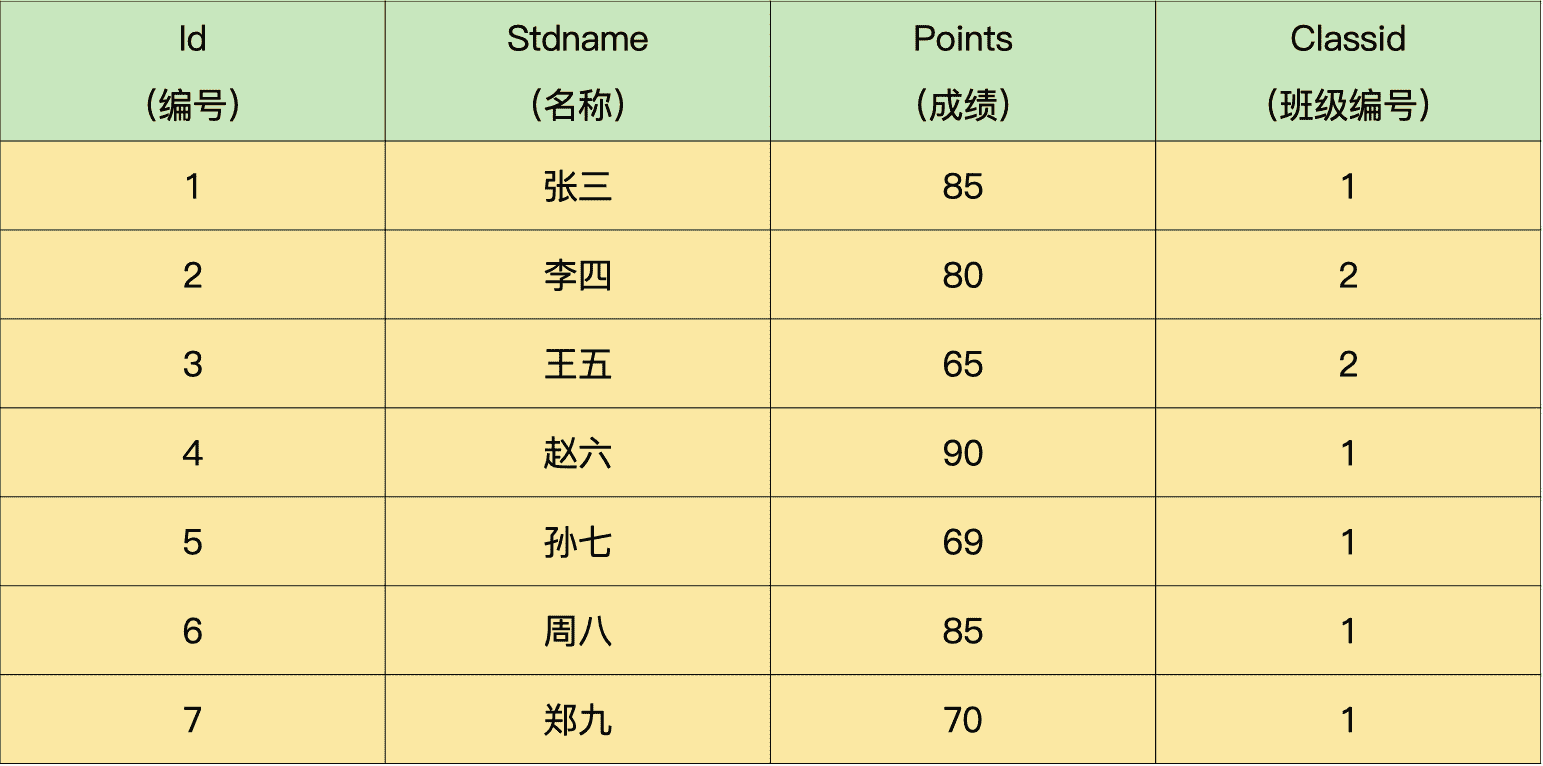
班级信息表:

要求:写一个 SQL 查询语句,查出每个班级前三名的同学。
说明一下,针对上面的数据,正确的 SQL 查询应该得出下面的结果:
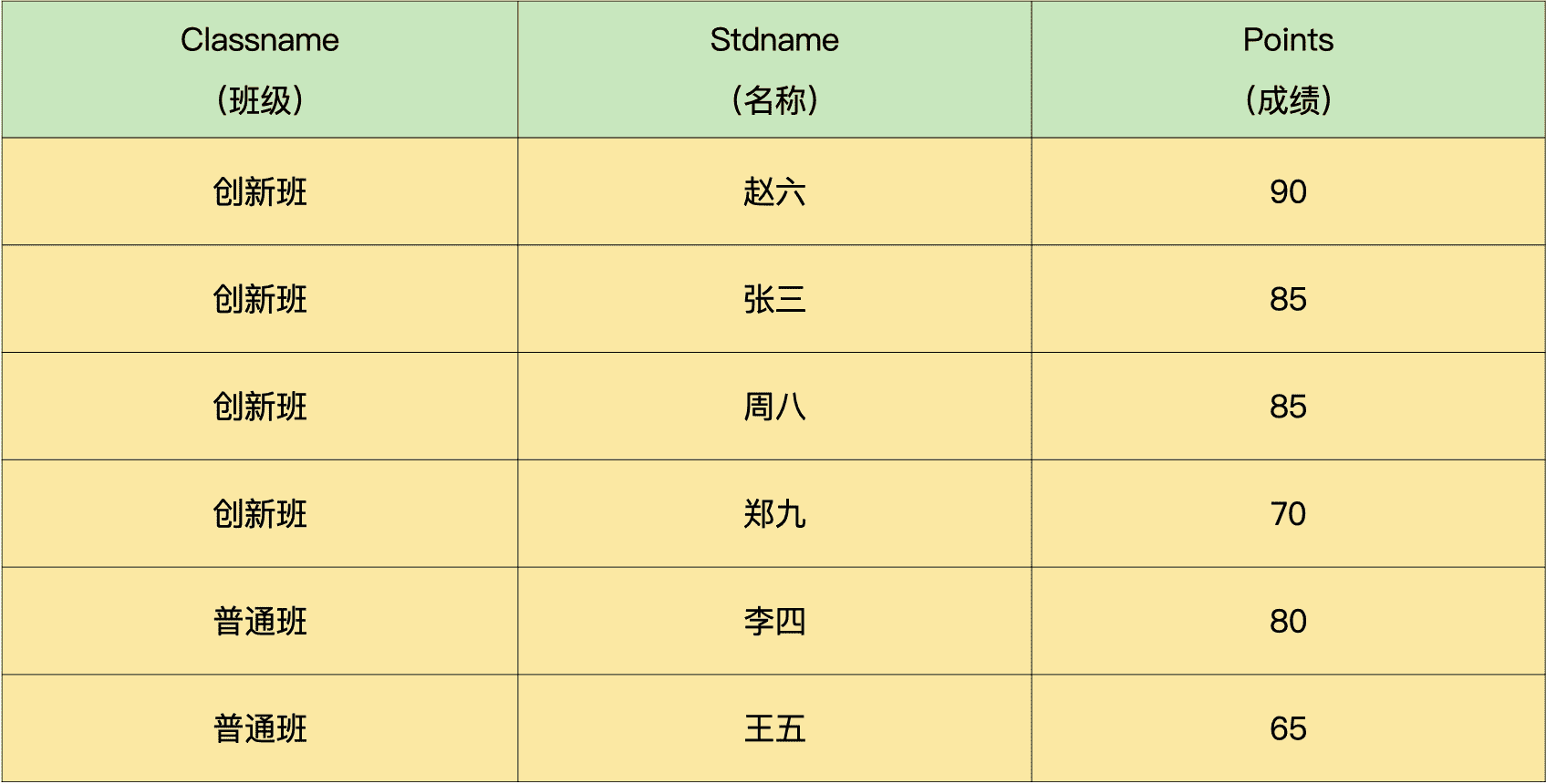
解析:
- 从题目给出的查询结果看,不需要考虑并列的情况。那么,现在要选出分数排名前三的同学,其实只要找出 3 个最好的分数以及对应的同学就可以了。
- 这道题需要用到我们讲过的关联查询和子查询的知识。
- WHERE 语句的筛选条件表达式中,也可以包括一个子查询的结果。
第一步,我们假设有一个分数 X,就是那个第 N 好的分数,算一下有多少个同学的成绩优于这个分数:
SELECT COUNT(DISTINCT b.points)
FROM demo.student AS b
WHERE b.points > X;
这个查询的结果小于 3 的话,就代表这个分数 X 是排名第三的分数了。
第二步,查询出哪些同学满足成绩排名前三的这个档次:
mysql> SELECT a.stdname,a.points
-> FROM demo.student AS a
-> WHERE 3 > – 比这个成绩好的不超过 3,说明这是第三好的成绩
-> (
-> SELECT COUNT(DISTINCT b.points) – 统计一下有几个成绩
-> FROM demo.student AS b
-> WHERE b.points > a.points – 比这个成绩好
-> );
+———+——–+
| stdname | points |
+———+——–+
| 张三 | 85 |
| 李四 | 80 |
| 赵六 | 90 |
| 周八 | 85 |
+———+——–+
4 rows in set (0.00 sec)
第三步,与班级表关联,按班级统计前三名同学的成绩,并且获取班级信息:
mysql> SELECT c.classname,a.stdname,a.points
-> FROM demo.student AS a
-> JOIN demo.class AS c
-> ON (a.classid = c.id) – 关联班级信息
-> WHERE 3 >
-> (
-> SELECT COUNT(DISTINCT b.points)
-> FROM demo.student AS b
-> WHERE b.points > a.points
-> AND b.classid = a.classid – 按班级分别查询
-> )
-> ORDER BY c.classname,a.points DESC;
+———–+———+——–+
| classname | stdname | points |
+———–+———+——–+
| 创新班 | 赵六 | 90 |
| 创新班 | 张三 | 85 |
| 创新班 | 周八 | 85 |
| 创新班 | 郑九 | 70 |
| 普通班 | 李四 | 80 |
| 普通班 | 王五 | 65 |
+———–+———+——–+
6 rows in set (0.00 sec)
总结
今天,我们借助几个面试题,回顾了索引的概念、查询、子查询和关联查询的知识,以及条件语句 WHERE 和 HAVING 的不同使用方法。如果你发现哪些内容掌握得还没有那么牢固,一定要及时回去复习一下。
在真正的面试中,很少有单纯考查知识点本身的题目,更多的是考查你在解决实际问题的过程中,对知识的灵活运用能力。所以,在学习每一节课时,你一定要结合我给出的实际项目,去真正实践一下,这样才能以不变应万变,在面试中有好的表现。
文章作者 anonymous
上次更新 2024-02-26