22|动态分组:超高效实现秒级扩缩容
文章目录
你好,我是何小锋。上一讲我们介绍了在 RPC 里面怎么支持流量回放,应用在引入 RPC 后,所有的请求都会被 RPC 接管,而我们在 RPC 里面引入回放的原因也很简单,就是想通过线上流量来验证改造后应用的正确性,而线上流量相比手动维护 TestCase 的场景更丰富,所以用线上流量进行测试的覆盖率会更广。
回顾完上一讲的重点,我们就切入今天的主题,一起看看动态分组在 RPC 里面的应用。
在[第 16 讲] 我们讲过,在调用方复杂的情况下,如果还是让所有调用方都调用同一个集群的话,很有可能会因为非核心业务的调用量突然增长,而让整个集群变得不可用了,进而让核心业务的调用方受到影响。为了避免这种情况发生,我们需要把整个大集群根据不同的调用方划分出不同的小集群来,从而实现调用方流量隔离的效果,进而保障业务之间不会互相影响。
分组后容量评估
通过人为分组的方式确实能帮服务提供方硬隔离调用方的流量,让不同的调用方拥有自己独享的集群,从而保障各个调用方之间互不影响。但这对于我们服务提供方来说,又带来了一个新的问题,就是我们该给调用方分配多大的集群才合适呢?
在[第 16 讲] 我们也有聊到过这样的问题,就是该怎么划分集群的分组?当然,最理想的情况就是给每个调用方都分配一个独立的分组,但是如果在服务提供方的调用方相对比较多的情况下,对于服务提供方来说要维护这些关系还是比较困难的。因此实际在给集群划分分组的时候,我们一般会选择性地合并一些调用方到同一个分组里。这就需要我们服务提供方考虑该怎么合并,且合并哪些调用方?
因为这个问题并没有统一的标准,所以我当时给的建议就是我们可以按照应用的重要级别来划分,让非核心业务应用跟核心业务应用不要公用一个分组,核心应用之间也最好别用同一个分组。但这只是一个划分集群分组的建议,并没有具体告诉你该如何划分集群大小。换句话就是,你可以按照这个原则去规划设计自己的集群要分多少个组。
按照上面的原则,我们把整个集群从逻辑上分为不同的分组之后,接下来我们要做的事情就是给每个分组分配相应的机器数量。那每个分组对应的机器数量,我们该怎么计算呢?我相信这个问题肯定难不倒你。在这儿我先分享下我们团队常用的做法,我们一般会先通过压测去评估下服务提供方单台机器所能承受的 QPS,然后再计算出每个分组里面的所有调用方的调用总量。有了这两个值之后,我们就能很容易地计算出这个分组所需要的机器数。
通过计算分组内所有调用方 QPS 的方式来算出单个分组内所需的机器数,整体而言还是比较客观准确的。但因为每个调用方的调用量并不是一成不变的,比如商家找个网红做个直播卖货,那就很有可能会导致今天的下单量相对昨天有小幅度的上涨。就是因为这些不确定性因素的存在,所以服务提供方在给调用方做容量评估的时候,通常都会在现有调用量的基础上加一个百分比,而这个百分比多半来自历史经验总结。
总之,就是在我们算每个分组所需要的机器数的时候,需要额外给每个分组增加一些机器,从而让每个小集群有一定的抗压能力,而这个抗压能力取决于给这个集群预留的机器数量。作为服务提供方来说,肯定希望给每个集群预留的机器数越多越好,但现实情况又不允许预留太多,因为这样会增加团队的整体成本。
分组带来的问题
通过给分组预留少量机器的方式,以增加单个集群的抗压能力。一般情况下,这种机制能够运行得很好,但在应对大的突发流量时,就会显得有点捉襟见肘了。因为机器成本的原因,我们给每个分组预留的机器数量都不会太多,所以当突发流量超过预留机器的能力的时候,就会让这个分组的集群处于一个危险状态了。
这时候我们唯一能做的就是给这个分组去扩容新的机器,但临时扩容新机器通常需要一个比较长的时间,而且花的时间越长,业务受影响的范围就越大。
那有没有更便捷一点的方案呢?前面我们说过,我们在给分组做容量评估的时候,通常都会增加了一些富余。换句话就是,除了当前出问题的分组,其它分组的服务提供方在保障自己调用方质量的同时,还是可以额外承担一些流量的。我们可以想办法快速利用这部分已有的能力。
但因为我们实现了流量隔离功能,整个集群被我们划分成了不同的分组,所以当前出问题的调用方并不能把请求发送到其它分组的机器上。那可能你会说,既然临时去申请机器进行扩容时间长,那我能不能把上面说的那些富余的机器直接拿过来,把部署在机器上的应用改成出问题的分组,然后进行重启啊?这样出问题的那个分组的服务提供方机器数就会变多了。
从结果上来看,这样处理确实能够解决问题,但有一个问题就是这样处理的时间还是相对较长的,而且当这个分组的流量恢复后,你还得把临时借过来的机器还回原来的分组。
问题分析到这儿,我想说,动态分组就可以派上用场了。
动态分组的应用
上面的问题,其根本原因就是某个分组的调用方流量突增,而这个分组所预留的空间也不能满足当前流量的需求,但是其它分组的服务提供方有足够的富余能力。但这些富余的能力,又被我们的分组进行了强制的隔离,我们又不能抛弃分组功能,否则老问题就要循环起来了。
那这样的话,我们就只能在出问题的时候临时去借用其它分组的部分能力,但通过改分组进行重启应用的方式,不仅操作过程慢,事后还得恢复。因此这种生硬的方式显然并不是很合适。
想一下啊,我们改应用分组然后进行重启的目的,就是让出问题的服务调用方能通过服务发现找到更多的服务提供方机器,而服务发现的数据来自注册中心,那我们是不是可以通过修改注册中心的数据来解决呢?
我们只要把注册中心里面的部分实例的别名改成我们想要的别名,然后通过服务发现进而影响到不同调用方能够调用的服务提供方实例集合。
举个例子,服务提供方有 3 个服务实例,其中 A 分组有 2 个实例,B 分组有 1 个实例,调用方 1 调用 A 分组,调用方 2 调用 B 分组。我们把 A 分组里面的一个实例分组在注册中心由 A 分组改为 B 分组,经过服务发现影响后,整个调用拓扑就变成了这样:
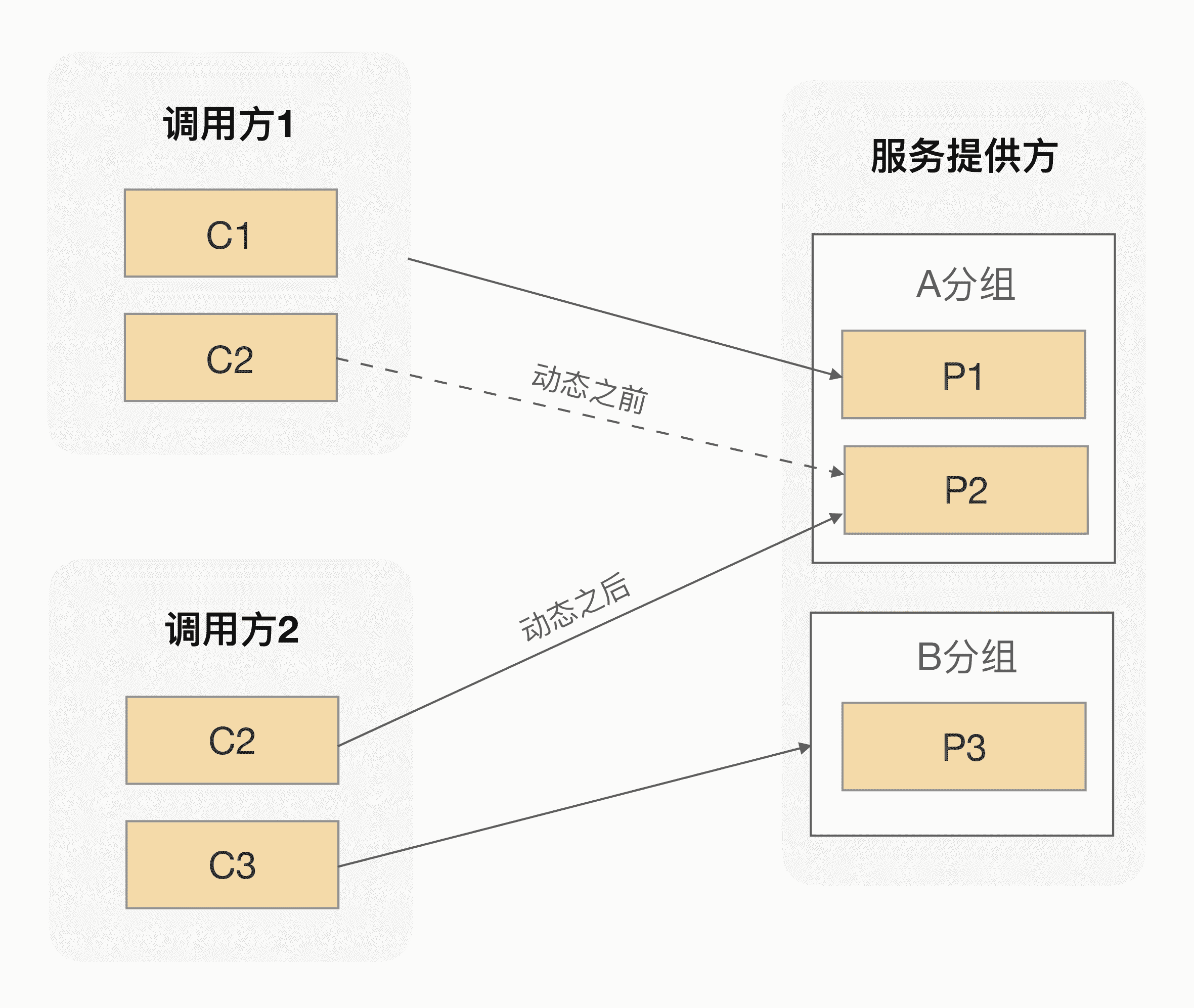
动态别名过程
通过直接修改注册中心数据,我们可以让任何一个分组瞬间拥有不同规模的集群能力。我们不仅可以实现把某个实例的分组名改成另外一个分组名,还可以让某个实例分组名变成多个分组名,这就是我们在动态分组里面最常见的两种动作——追加和替换。
总结
在[第 16 讲],我们讲了分组后带来的收益,它可以帮助服务提供方实现调用方的隔离。但是因为调用方流量并不是一成不变的,而且还可能会因为突发事件导致某个分组的流量溢出,而在整个大集群还有富余能力的时候,又因为分组隔离不能为出问题的集群提供帮助。
为了解决这种突发流量的问题,我们提供了一种更高效的方案,可以实现分组的快速扩缩容。事实上我们还可以利用动态分组解决分组后给每个分组预留机器冗余的问题,我们没有必要把所有冗余的机器都分配到分组里面,我们可以把这些预留的机器做成一个共享的池子,从而减少整体预留的实例数量。
课后思考
在服务治理的过程中,我们通常会给服务进行逻辑分组,但之后某个分组可能会遇到突发流量调用的问题,在本讲我给出了一个动态分组的方案。但是动态分组的过程中,我们只是把注册中心的数据改了,而服务提供方提供真实的分组名并没有改变,这时候用动态分组名的调用方调用过来的请求可能就会报错,因为服务提供方会验证调用方过来的分组名跟自身的是否一样。针对这个问题,你能想到什么解决方案?
欢迎留言和我分享你的答案,也欢迎你把文章分享给你的朋友,邀请他加入学习。我们下节课再见!
文章作者 anonymous
上次更新 2024-02-15