05|调度系统:“数据不动代码动”到底是什么意思?
文章目录
你好,我是吴磊。
在日常的开发与调优工作中,为了充分利用硬件资源,我们往往需要手工调节任务并行度来提升 CPU 利用率,控制任务并行度的参数是 Spark 的配置项:spark.default.parallelism。增加并行度确实能够充分利用闲置的 CPU 线程,但是,parallelism 数值也不宜过大,过大反而会引入过多的调度开销,得不偿失。
这个调优技巧可以说是老生常谈了,网上到处都可以搜得到。那你知道为什么 parallelism 数值过大调度开销会呈指数级增长吗?调度开销具体又是指什么呢?以及,如果不想一个数值一个数值的尝试,parallelism 数值究竟该怎么设置,才能以最少的时间获得最好的效果?如果你还没有答案,或者说还没有把握答对,接下来你就要好好听我讲。
这一讲,我会通过一个机器学习案例,来和你一起聊聊调度系统是什么,它是怎么工作的,从而帮助你摆脱调优总是停留在知其然、不知其所以然的尴尬境地。
案例:对用户兴趣特征做 Label Encoding
在机器学习应用中,特征工程几乎占据了算法同学 80% 的时间和精力,毕竟,一份质量优良的训练样本限定了模型效果的上限和天花板,我们要讲的案例就来自特征工程中一个典型的处理场景:Label Encoding(标签编码)。
什么是 Label encoding 呢?模型特征按照是否连续可以分为两类:连续性数值特征和离散型特征,离散型特征往往以字符串的形式存在,比如用户兴趣特征就包括体育、政治、军事和娱乐等。对于很多机器学习算法来说,字符串类型的数据是不能直接消费的,需要转换为数值才行,例如把体育、政治、军事、娱乐映射为 0、1、2、3,这个过程在机器学习领域有个术语就叫 Label encoding。
我们这一讲的案例,就是要对用户兴趣特征做 Label encoding,简单来说就是以固定的模板把字符串转换为数值,然后将千亿条样本中的用户兴趣转换为对应的索引值。固定模板是离线模型训练与线上模型服务之间的文件接口,内容仅包含用户兴趣这一列,字符串已按事先约定好的规则进行排序。我们需要注意的是,用户兴趣包含 4 个层级,因此这个模板文件较大,记录数达到万级别。
//模板文件
//用户兴趣
体育 - 篮球-NBA-湖人
军事 - 武器 - 步枪-AK47
那具体怎么转换呢?例如,我们可以将用户兴趣“体育 - 篮球 -NBA- 湖人”映射为 0,将兴趣“军事 - 武器 - 步枪 -AK47”映射为 1,以此类推。应该说,需求还是相当明确的,我身边的同学们拿到需求之后,奔儿都没打,以迅雷不及掩耳之势就实现了如下的处理函数。
/**
实现方式 1
输入参数:模板文件路径,用户兴趣字符串
返回值:用户兴趣字符串对应的索引值
*/
//函数定义
def findIndex(templatePath: String, interest: String): Int = {
val source = Source.fromFile(filePath, “UTF-8”)
val lines = source.getLines().toArray
source.close()
val searchMap = lines.zip(0 until lines.size).toMap
searchMap.getOrElse(interest, -1)
}
//Dataset 中的函数调用
findIndex(filePath, “体育 - 篮球-NBA-湖人”)
我们可以看到这个函数有两个形参,一个是模板文件路径,另一个是训练样本中的用户兴趣。处理函数首先读取模板文件,然后根据文件中排序的字符串构建一个从兴趣到索引的 Map 映射,最后在这个 Map 中查找第二个形参传入的用户兴趣,如果能找到则返回对应的索引,找不到的话则返回 -1。
这段代码看上去似乎没什么问题,同学们基于上面的函数对千亿样本做 Label encoding,在 20 台机型为 C5.4xlarge AWS EC2 的分布式集群中花费了 5 个小时。坦白说,这样的执行性能,我是不能接受的。你可能会说:“需求就是这个样子,还能有什么别的办法呢?”我们不妨来看另外一种实现方式。
/**
实现方式 2
输入参数:模板文件路径,用户兴趣字符串
返回值:用户兴趣字符串对应的索引值
*/
//函数定义
val findIndex: (String) => (String) => Int = {
(filePath) =>
val source = Source.fromFile(filePath, “UTF-8”)
val lines = source.getLines().toArray
source.close()
val searchMap = lines.zip(0 until lines.size).toMap
(interest) => searchMap.getOrElse(interest, -1)
}
val partFunc = findIndex(filePath)
//Dataset 中的函数调用
partFunc(“体育 - 篮球-NBA-湖人”)
同学们基于第二种方式对相同的数据集做 Label encoding 之后,在 10 台同样机型的分布式集群中花了不到 20 分钟就把任务跑完了。可以说,执行性能的提升是显而易见的。那么,两份代码有什么区别呢?
我们可以看到,相比于第一份代码,第二份代码的函数体内没有任何变化,还是先读取模板文件、构建 Map 映射、查找用户兴趣,最后返回索引。最大的区别就是第二份代码对高阶函数的使用,具体来说有 2 点:
- 处理函数定义为高阶函数,形参是模板文件路径,返回结果是从用户兴趣到索引的函数;
- 封装千亿样本的 Dataset 所调用的函数,不是第一份代码中的 findIndex,而是用模板文件调用 findIndex 得到的 partFunc,partFunc 是形参为兴趣、结果为索引的普通标量函数。
那么,高阶函数真有这么神奇吗?其实,性能的提升并不是高阶函数的功劳,而是调度系统在起作用。
Spark 的调度系统是如何工作的?
Spark 调度系统的核心职责是,先将用户构建的 DAG 转化为分布式任务,结合分布式集群资源的可用性,基于调度规则依序把分布式任务分发到执行器。这个过程听上去就够复杂的了,为了方便你理解,我们还是先来讲一个小故事。
土豆工坊流水线升级
在学完了内存计算的第二层含义之后,土豆工坊的老板决定对土豆加工流水线做升级,来提高工坊的生产效率和灵活性。
这里,我们先对内存计算的第二层含义做个简单地回顾,它指的是同一 Stage 中的所有操作会被捏合为一个函数,这个函数一次性会被地应用到输入数据上,并且一次性地产生计算结果。
升级之前的土豆加工流程 DAG 被切分为 3 个执行阶段 Stage,它们分别是 Stage 0、Stage 1、Stage 2。其中,Stage 0 产出即食薯片,Stage 1 分发调味品,Stage 2 则产出不同尺寸、不同风味的薯片。我们重点关注 Stage 0,Stage 0 有 3 个加工环节,分别是清洗、切片和烘焙。这 3 个环节需要 3 种不同的设备,即清洗机、切片机和烤箱。

土豆工坊加工流程的 3 个执行阶段
工坊有 3 条流水线,每种设备都需要 3 套,在成本方面要花不少钱呢,因此工坊老板一直绞尽脑汁想把设备方面的成本降下来。
此时,工头儿建议:“老板,我听说市场上有一种可编程的土豆加工设备,它是个黑盒子并且只有输入口和输出口,从外面看不见里面的操作流程。不过黑盒子受程序控制,给定输入口的食材,我们可以编写程序控制黑盒子的输出。有了这个可编程设备,咱们不但省了钱,将来还可以灵活地扩充产品线。比方想生产各种风味的薯条或是土豆泥,只需要更换一份程序加载到黑盒子里就行啦!”
老板听后大喜,决定花钱购入可编程土豆加工设备,替换并淘汰现有的清洗机、切片机和烤箱。
于是,工坊的加工流水线就变成了如下的样子。工人们的工作也从按照 DAG 流程图的关键步骤,在流水线上安装相应的设备,变成了把关键步骤编写相应的程序加载到黑盒内。这样一来,这家工坊的生产力也从作坊式的生产方式,升级到了现代化流水线的作业模式。

演进的土豆加工流水线
那么,这个故事跟我们今天要讲的调度系统有什么关系呢?事实上,Spark 调度系统的工作流程包含如下 5 个步骤:
1. 将 DAG 拆分为不同的运行阶段 Stages;
2. 创建分布式任务 Tasks 和任务组 TaskSet;
3. 获取集群内可用 的 硬件资源情况;
4. 按照调度规则决定优先调度哪些任务 / 组;
5. 依序将分布式任务分发到执行器 Executor。
除了第 4 步以外,其他几步和土豆工坊流水线上的关键步骤都是一一对应的,它们的对应关系如下:

现在,你可能会觉得用故事来记这几个步骤好像多此一举,但当我们学完了所有的原理之后,再回过头来把故事的主线串联起来,你就会惊喜地发现,所有的原理你都能轻松地记住和理解,这可比死记硬背的效率要高得多。
调度系统中的核心组件有哪些?
接下来,我们深入到流程中的每一步去探究 Spark 调度系统是如何工作的。不过在此之前,我们得先弄清楚调度系统都包含哪些关键组件,不同组件之间如何交互,它们分别担任了什么角色,才能更好地理解流程中的每一步。
Spark 调度系统包含 3 个核心组件,分别是 DAGScheduler、TaskScheduler 和 SchedulerBackend。这 3 个组件都运行在 Driver 进程中,它们通力合作将用户构建的 DAG 转化为分布式任务,再把这些任务分发给集群中的 Executors 去执行。不过,它们的名字都包含 Scheduler,光看名字还真是丈二和尚摸不着头脑,所以我把它们和调度系统流程中 5 个步骤的对应关系总结在了下表中,你可以看一看。

1. DAGScheduler
DAGScheduler 的主要职责有二:一是把用户 DAG 拆分为 Stages,如果你不记得这个过程可以回顾一下上一讲的内容;二是在 Stage 内创建计算任务 Tasks,这些任务囊括了用户通过组合不同算子实现的数据转换逻辑。然后,执行器 Executors 接收到 Tasks,会将其中封装的计算函数应用于分布式数据分片,去执行分布式的计算过程。
不过,如果我们给集群中处于繁忙或者是饱和状态的 Executors 分发了任务,执行效果会大打折扣。因此,在分发任务之前,调度系统得先判断哪些节点的计算资源空闲,然后再把任务分发过去。那么,调度系统是怎么判断节点是否空闲的呢?
2. SchedulerBackend
SchedulerBackend 就是用来干这个事的,它是对于资源调度器的封装与抽象,为了支持多样的资源调度模式如 Standalone、YARN 和 Mesos,SchedulerBackend 提供了对应的实现类。在运行时,Spark 根据用户提供的 MasterURL,来决定实例化哪种实现类的对象。MasterURL 就是你通过各种方式指定的资源管理器,如 –master spark://ip:host(Standalone 模式)、–master yarn(YARN 模式)。
对于集群中可用的计算资源,SchedulerBackend 会用一个叫做 ExecutorDataMap 的数据结构,来记录每一个计算节点中 Executors 的资源状态。ExecutorDataMap 是一种 HashMap,它的 Key 是标记 Executor 的字符串,Value 是一种叫做 ExecutorData 的数据结构,ExecutorData 用于封装 Executor 的资源状态,如 RPC 地址、主机地址、可用 CPU 核数和满配 CPU 核数等等,它相当于是对 Executor 做的“资源画像”。
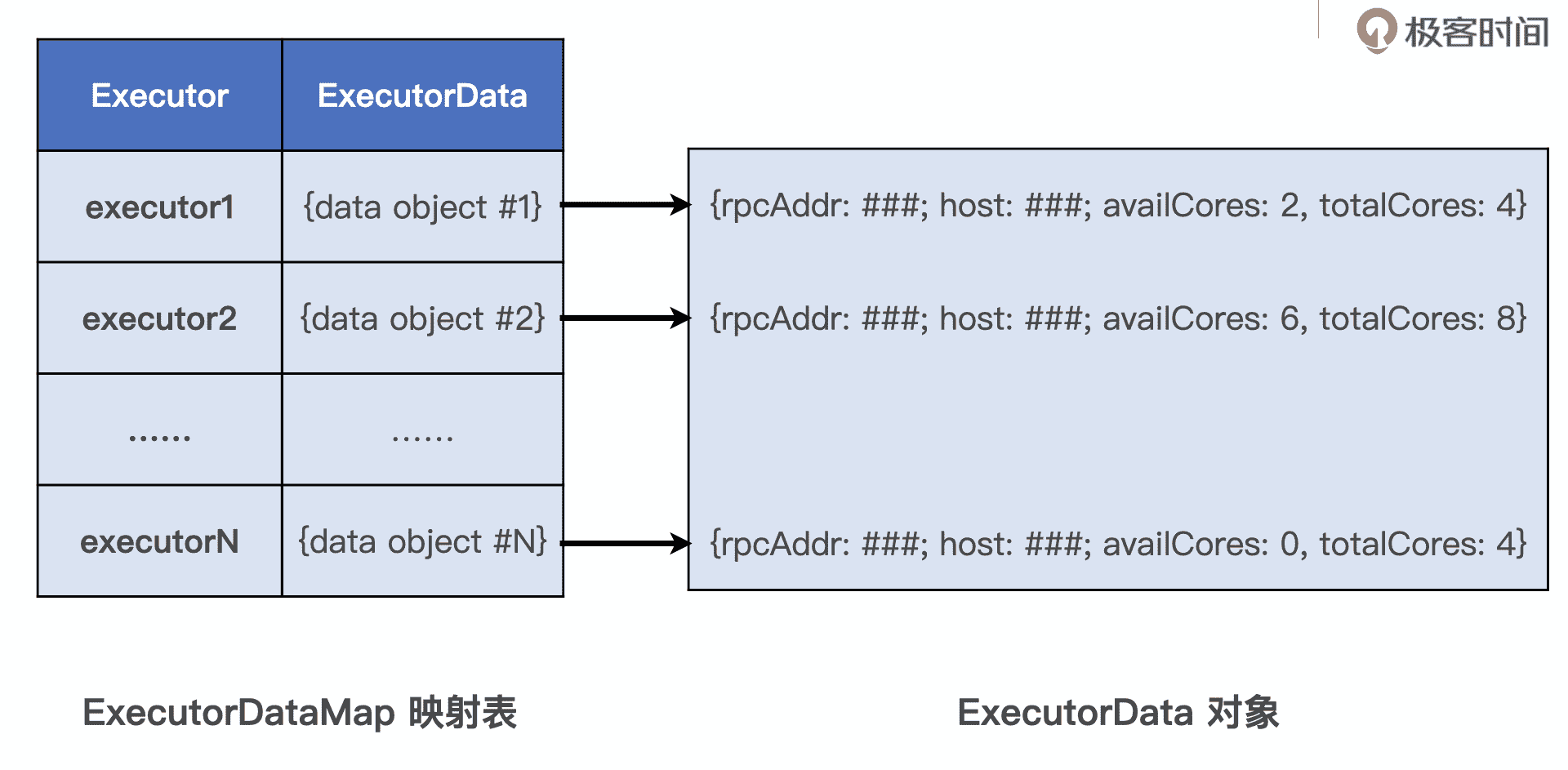
ExecutorDataMap 映射表
总的来说,对内,SchedulerBackend 用 ExecutorData 对 Executor 进行资源画像;对外,SchedulerBackend 以 WorkerOffer 为粒度提供计算资源,WorkerOffer 封装了 Executor ID、主机地址和 CPU 核数,用来表示一份可用于调度任务的空闲资源。显然,基于 Executor 资源画像,SchedulerBackend 可以同时提供多个 WorkerOffer 用于分布式任务调度。WorkerOffer 这个名字起得蛮有意思,Offer 的字面意思是公司给你提供的工作机会,结合 Spark 调度系统的上下文,就变成了使用硬件资源的机会。
好了,到此为止,要调度的计算任务有了,就是 DAGScheduler 通过 Stages 创建的 Tasks;可用于调度任务的计算资源也有了,即 SchedulerBackend 提供的一个又一个 WorkerOffer。如果从供需的角度看待任务调度,DAGScheduler 就是需求端,SchedulerBackend 就是供给端。
3. TaskScheduler
左边有需求,右边有供给,如果把 Spark 调度系统看作是一个交易市场的话,那么中间还需要有个中介来帮它们对接意愿、撮合交易,从而最大限度地提升资源配置的效率。在 Spark 调度系统中,这个中介就是 TaskScheduler。TaskScheduler 的职责是,基于既定的规则与策略达成供需双方的匹配与撮合。

Spark 分布式任务调度流程
显然,TaskScheduler 的核心是任务调度的规则和策略,TaskScheduler 的调度策略分为两个层次,一个是不同 Stages 之间的调度优先级,一个是 Stages 内不同任务之间的调度优先级。
首先,对于两个或多个 Stages,如果它们彼此之间不存在依赖关系、互相独立,在面对同一份可用计算资源的时候,它们之间就会存在竞争关系。这个时候,先调度谁、或者说谁优先享受这份计算资源,大家就得基于既定的规则和协议照章办事了。
对于这种 Stages 之间的任务调度,TaskScheduler 提供了 2 种调度模式,分别是 FIFO(先到先得)和 FAIR(公平调度)。 FIFO 非常好理解,在这种模式下,Stages 按照被创建的时间顺序来依次消费可用计算资源。这就好比在二手房交易市场中,两个人同时看中一套房子,不管两个人各自愿意出多少钱,谁最先交定金,中介就优先给谁和卖家撮合交易。
你可能会说:“这不合常理啊!如果第二个人愿意出更多的钱,卖家自然更乐意和他成交。”没错,考虑到开发者的意愿度,TaskScheduler 提供了 FAIR 公平调度模式。在这种模式下,哪个 Stages 优先被调度,取决于用户在配置文件 fairscheduler.xml 中的定义。
在配置文件中,Spark 允许用户定义不同的调度池,每个调度池可以指定不同的调度优先级,用户在开发过程中可以关联不同作业与调度池的对应关系,这样不同 Stages 的调度就直接和开发者的意愿挂钩,也就能享受不同的优先级待遇。对应到二手房交易的例子中,如果第二个人乐意付 30% 的高溢价,中介自然乐意优先撮合他与卖家的交易。
说完了不同 Stages 之间的调度优先级,我们再来说说同一个 Stages 内部不同任务之间的调度优先级,Stages 内部的任务调度相对来说简单得多。当 TaskScheduler 接收到来自 SchedulerBackend 的 WorkerOffer 后,TaskScheduler 会优先挑选那些满足本地性级别要求的任务进行分发。众所周知,本地性级别有 4 种:Process local < Node local < Rack local < Any。从左到右分别是进程本地性、节点本地性、机架本地性和跨机架本地性。从左到右,计算任务访问所需数据的效率越来越差。
进程本地性表示计算任务所需的输入数据就在某一个 Executor 进程内,因此把这样的计算任务调度到目标进程内最划算。同理,如果数据源还未加载到 Executor 进程,而是存储在某一计算节点的磁盘中,那么把任务调度到目标节点上去,也是一个不错的选择。再次,如果我们无法确定输入源在哪台机器,但可以肯定它一定在某个机架上,本地性级别就会退化到 Rack local。
DAGScheduler 划分 Stages、创建分布式任务的过程中,会为每一个任务指定本地性级别,本地性级别中会记录该任务有意向的计算节点地址,甚至是 Executor 进程 ID。换句话说,任务自带调度意愿,它通过本地性级别告诉 TaskScheduler 自己更乐意被调度到哪里去。
既然计算任务的个人意愿这么强烈,TaskScheduler 作为中间商,肯定要优先满足人家的意愿。这就像一名码农想要租西二旗的房子,但是房产中介 App 推送的结果都是东三环国贸的房子,那么这个中介的匹配算法肯定有问题。
由此可见,Spark 调度系统的原则是尽可能地让数据呆在原地、保持不动,同时尽可能地把承载计算任务的代码分发到离数据最近的地方,从而最大限度地降低分布式系统中的网络开销。毕竟,分发代码的开销要比分发数据的代价低太多,这也正是“数据不动代码动”这个说法的由来。
总的来说,TaskScheduler 根据本地性级别遴选出待计算任务之后,先对这些任务进行序列化。然后,交给 SchedulerBackend,SchedulerBackend 根据 ExecutorData 中记录的 RPC 地址和主机地址,再将序列化的任务通过网络分发到目的主机的 Executor 中去。最后,Executor 接收到任务之后,把任务交由内置的线程池,线程池中的多线程则并发地在不同数据分片之上执行任务中封装的数据处理函数,从而实现分布式计算。
性能调优案例回顾
知道了调度系统是如何工作的,我们就可以回过头来说说开头 Label encoding 的开发案例中,2 种实现方式的差别到底在哪儿了。我们先来回顾案例中处理函数的主要计算步骤:
- 读取并遍历模板文件内容,建立从字符串到数值的字典;
- 根据样本中的用户兴趣,查找字典并返回兴趣字符串对应的数值索引。
2 种实现方式的本质区别在于,函数中 2 个计算步骤的分布式计算过程不同。在第 1 种实现方式中,函数是一个接收两个形参的普通标量函数,Dataset 调用这个函数在千亿级样本上做 Label encoding。
在 Spark 任务调度流程中,该函数在 Driver 端交由 DAGScheduler 打包为 Tasks,经过 TaskScheduler 调度给 SchedulerBackend,最后由 SchedulerBackend 分发到集群中的 Executors 中去执行。这意味着集群中的每一个 Executors 都需要执行函数中封装的两个计算步骤,要知道,第一个步骤中遍历文件内容并建立字典的计算开销还是相当大的。
反观第 2 种实现方式,2 个计算步骤被封装到一个高阶函数中。用户代码先在 Driver 端用模板文件调用这个高阶函数,完成第一步计算建立字典的过程,同时输出一个只带一个形参的标量函数,这个标量函数内携带了刚刚建好的映射字典。最后,Dataset 将这个标量函数作用于千亿样本之上做 Label encoding。
发现区别了吗?在第 2 种实现中,函数的第一步计算只在 Driver 端计算一次,分发给集群中所有 Executors 的任务中封装的是携带了字典的标量函数。然后在 Executors 端,Executors 在各自的数据分片上调用该函数,省去了扫描模板文件、建立字典的开销。最后,我们只需要把样本中的用户兴趣传递进去,函数就能以 O(1) 的查询效率返回数值结果。
对于一个有着成百上千 Executors 的分布式集群来说,这 2 种不同的实现方式带来的性能差异还是相当可观的。因此,如果你能把 Spark 调度系统的工作原理牢记于心,我相信在代码开发或是 review 的过程中,你都能够意识到第一个计算步骤会带来的性能问题。这种开发过程中的反思,其实就是在潜移默化地建立以性能为导向的开发习惯。
小结
今天这一讲,我们先通过一个机器学的案例对比了 2 种实现方式的性能差异,知道了对于调度系统一知半解,很有可能在开发过程中引入潜在的性能隐患。为此,我梳理了调度系统工作流程的 5 个主要步骤:
- 将 DAG 拆分为不同的运行阶段 Stages;
- 创建分布式任务 Tasks 和任务组 TaskSet;
- 获取集群内可用硬件资源情况;
- 按照调度规则决定优先调度哪些任务 / 组;
- 依序将分布式任务分发到执行器 Executor;
结合这 5 个步骤,我们深入分析了 Spark 调度系统的工作原理,我们可以从核心职责和核心原则这两方面来归纳:
- Spark 调度系统的核心职责是,先将用户构建的 DAG 转化为分布式任务,结合分布式集群资源的可用性,基于调度规则依序把分布式任务分发到执行器 Executors;
- Spark 调度系统的核心原则是,尽可能地让数据呆在原地、保持不动,同时尽可能地把承载计算任务的代码分发到离数据最近的地方(Executors 或计算节点),从而最大限度地降低分布式系统中的网络开销。
每日一练
- DAGScheduler 在创建 Tasks 的过程中,是如何设置每一个任务的本地性级别?
- 在计算与存储分离的云计算环境中,Node local 本地性级别成立吗?你认为哪些情况下成立?哪些情况下不成立?
期待在留言区看到你的思考和答案,如果你的朋友也正急需搞清楚调度系统的工作原理,也欢迎你把这一讲转发给他,我们下一讲见!
文章作者 anonymous
上次更新 2024-01-26